文章目录
爬取京东笔记本图片
-
选取爬取目标
选取我们的爬取目标,电脑中的笔记本,我们发现url如下
https://list.jd.com/list.html?cat=670,671,672
-
构建url,爬取多页图片
对每页url进行观察
第一页url
https://list.jd.com/list.html?cat=670,671,672第二页url
https://list.jd.com/list.html?cat=670,671,672&page=2&sort=sort_totalsales15_desc&trans=1&JL=6_0_0#J_main第三页url
https://list.jd.com/list.html?cat=670,671,672&page=3&sort=sort_totalsales15_desc&trans=1&JL=6_0_0#J_main我们尝试直接使用如下url,发现出现的页面就是第二页,所以jd上显示的url后面为多余的
https://list.jd.com/list.html?cat=670,671,672&page=2每页的url为:
https://list.jd.com/list.html?cat=670,671,672&page=i
-
构建正则表达式
右键点击笔记本图片→检查
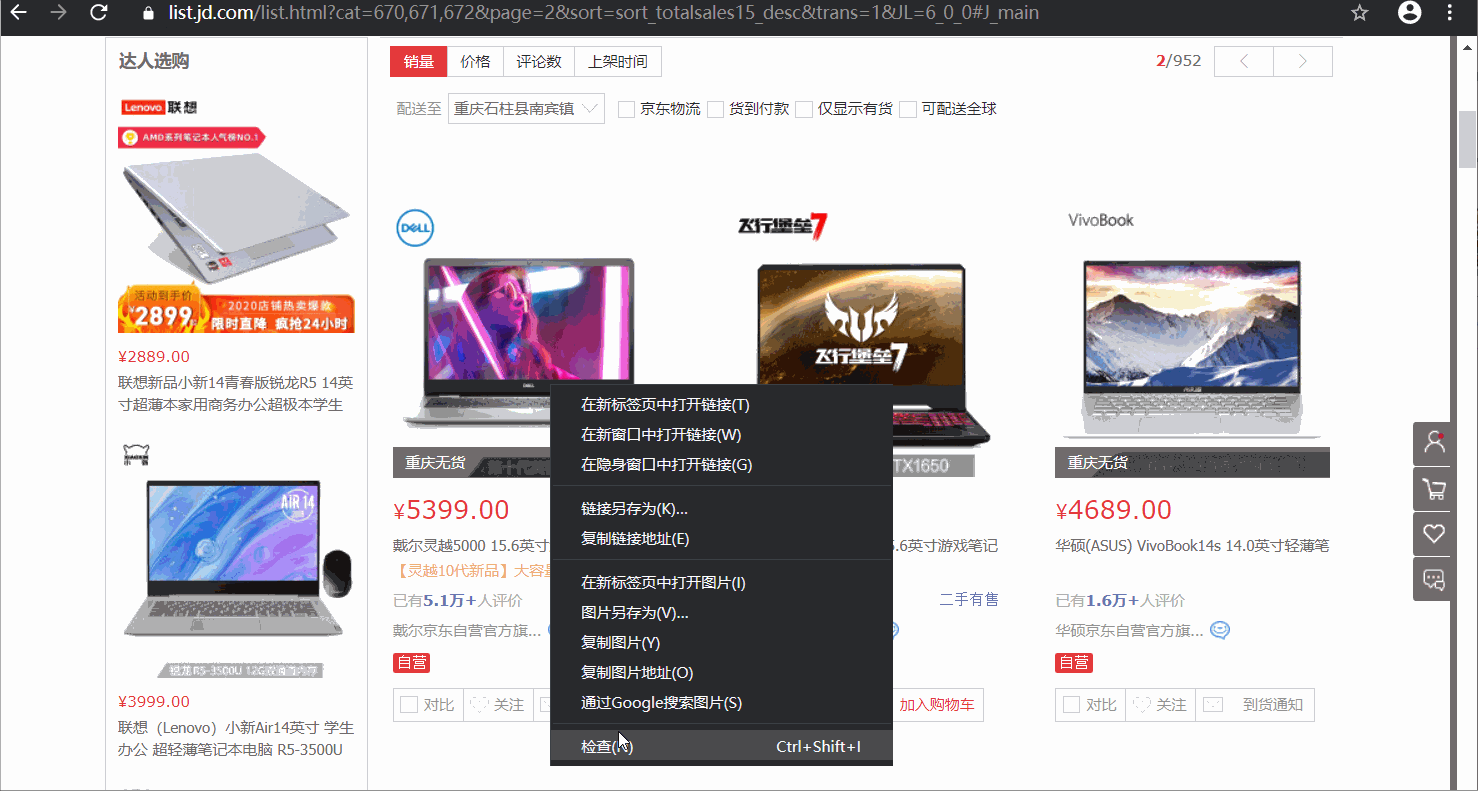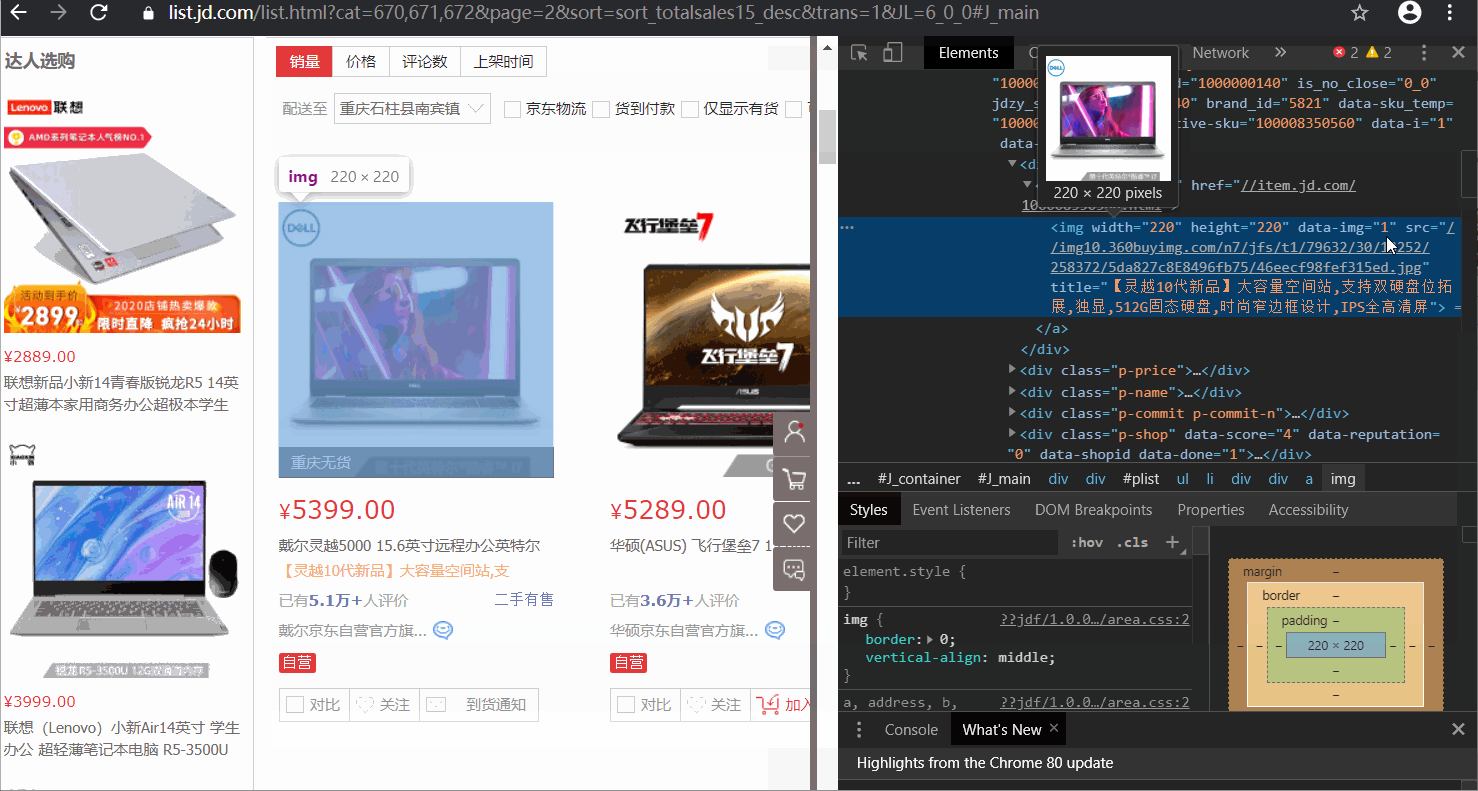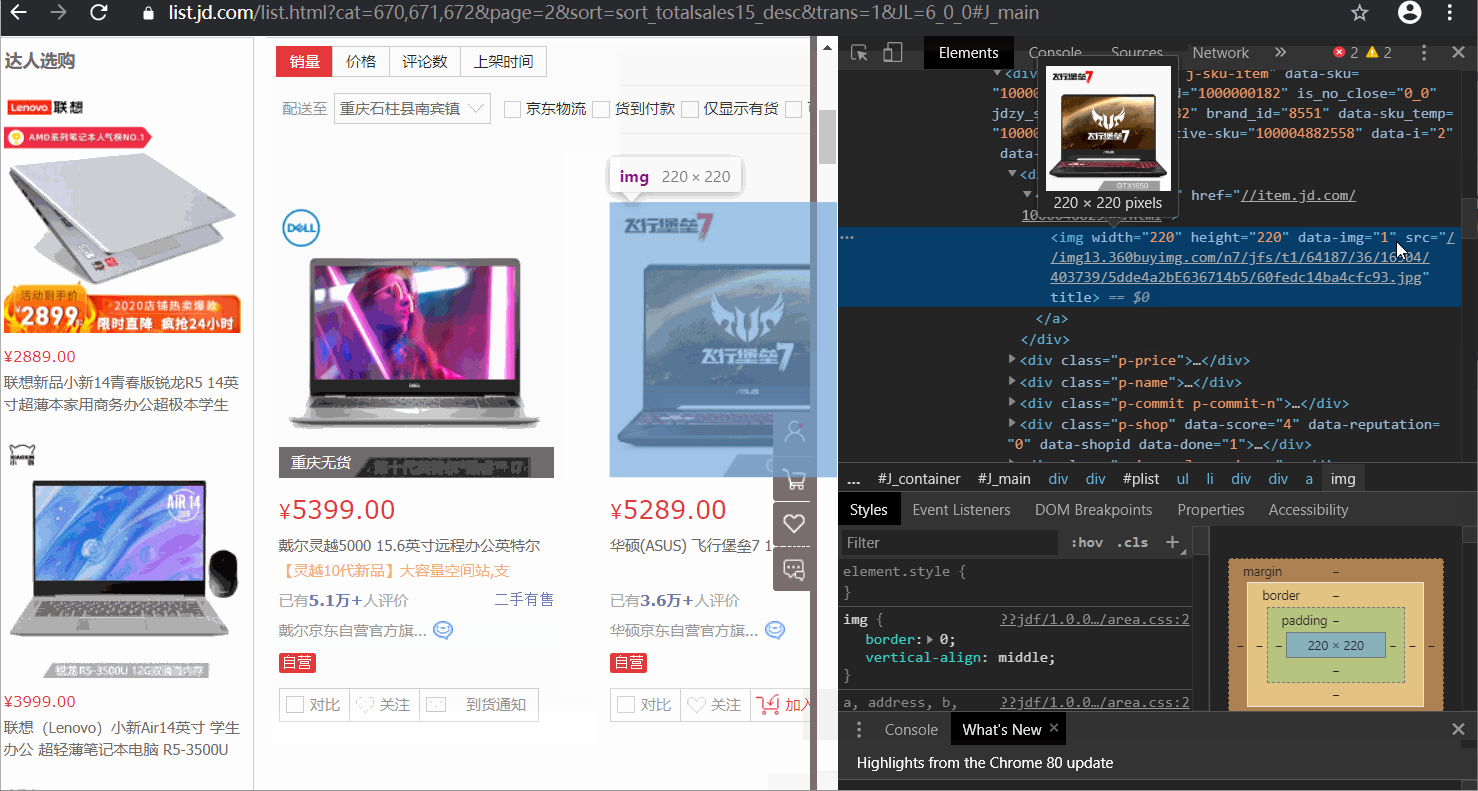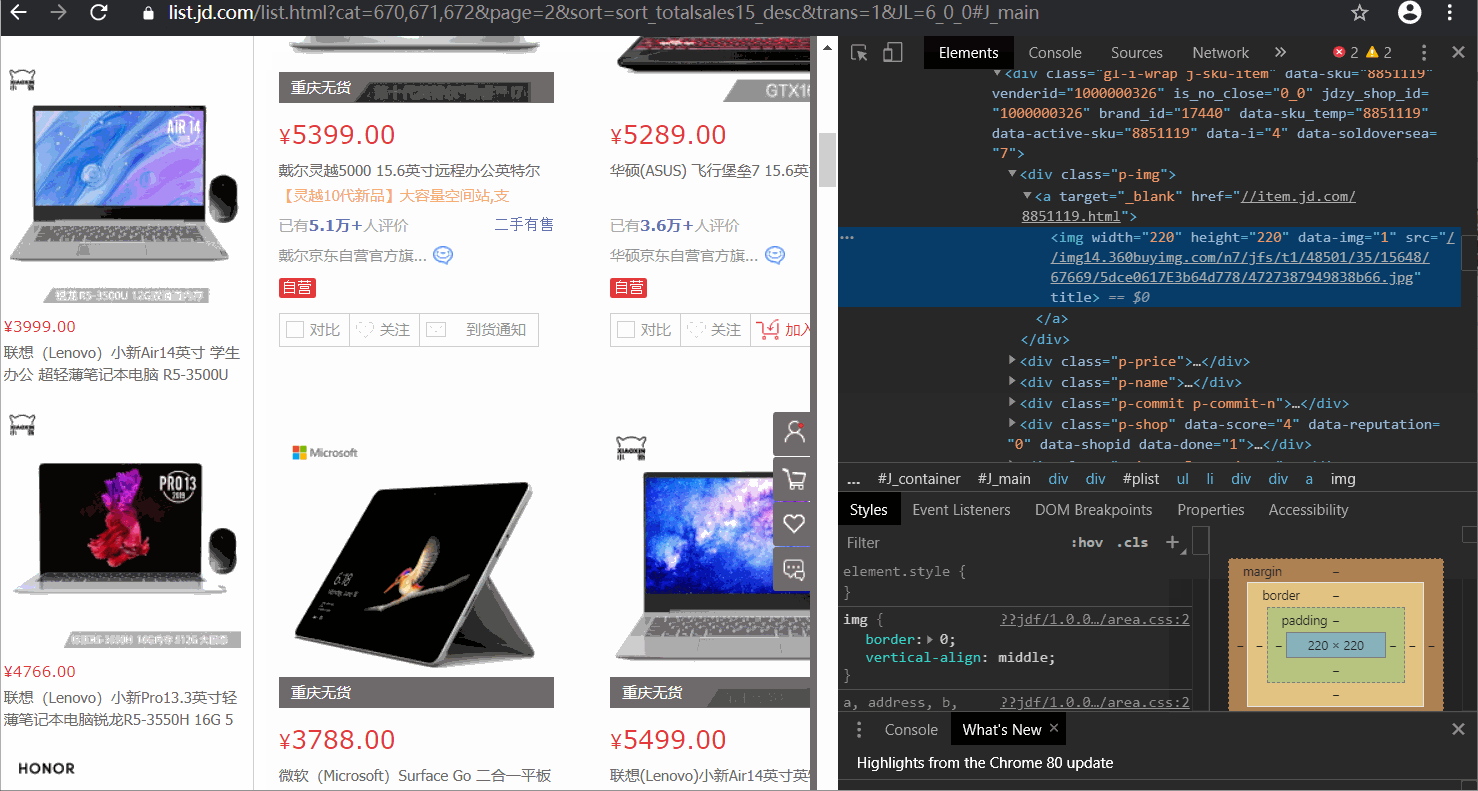
通过浏览器的检查功能,发现图片所在位置为"img width=“220” height=“220” data-img=“1” src="",所以,构造正则表达式pattern1='<img width="220" height="220" data-img="1" src=".+?">'这里,我们先观察下效果
In:
import urllib.request import re def reptile(url,page): req=urllib.request.Request(url) #创建Request对象 #模拟浏览器 req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36")# 添加报头信息格式:对象名.add_header() data=urllib.request.urlopen(req).read()#打开网址 data=str(data) #获取标签数据 pattern1='<img width="220" height="220" data-img="1" src=".+?">' result=re.compile(pattern1).findall(data) result=str(result) print(result) url="https://list.jd.com/list.html?cat=670,671,672&page="+str(i) reptile(url,1)Out:

发现匹配到的正是我们需要的src
-
提取数据
上面我们得到了图片位置,但还不能直接获取,还需要一定的处理
'<img width="220" height="220" data-img="1" src="//img12.360buyimg.com/n7/jfs/t1/90347/19/13459/85049/5e5a6779E5ab27072/757c0ae9a50c18ce.jpg">'观察上述标签,发现只有src中才是我们需要的内容,所以构建正则在匹配一次
pattern2='<img width="220" height="220" data-img="1" src="//(.+?\.jpg)">' result1=re.compile(pattern2).findall(result)查看效果
In:
import urllib.request import re def reptile(url,page): req=urllib.request.Request(url) #创建Request对象 #模拟浏览器 req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36")# 添加报头信息格式:对象名.add_header() data=urllib.request.urlopen(req).read()#打开网址 data=str(data) #获取标签数据 pattern1='<img width="220" height="220" data-img="1" src=".+?">' result=re.compile(pattern1).findall(data) result=str(result) #提取src pattern2='<img width="220" height="220" data-img="1" src="//(.+?\.jpg)">' result1=re.compile(pattern2).findall(result) print(result1) url="https://list.jd.com/list.html?cat=670,671,672&page="+str(i) reptile(url,1)Out:
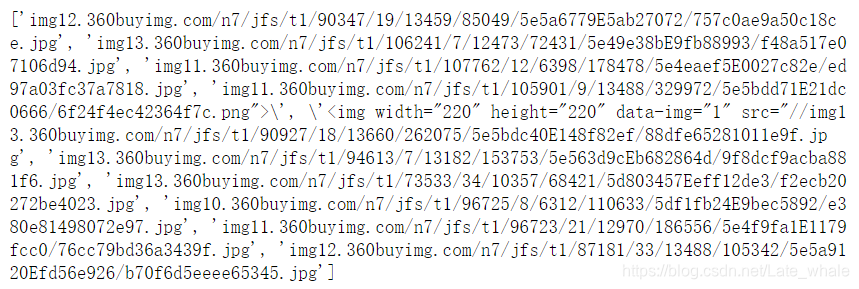
显而易见,这正是我们需要的只有src中的内容
-
构建真正的url链接
将之前获得的scr直接在浏览器中打开就是我们所需的图片了,所以这里就不要构建了,直接加上http://即可,不加浏览器也会自动加
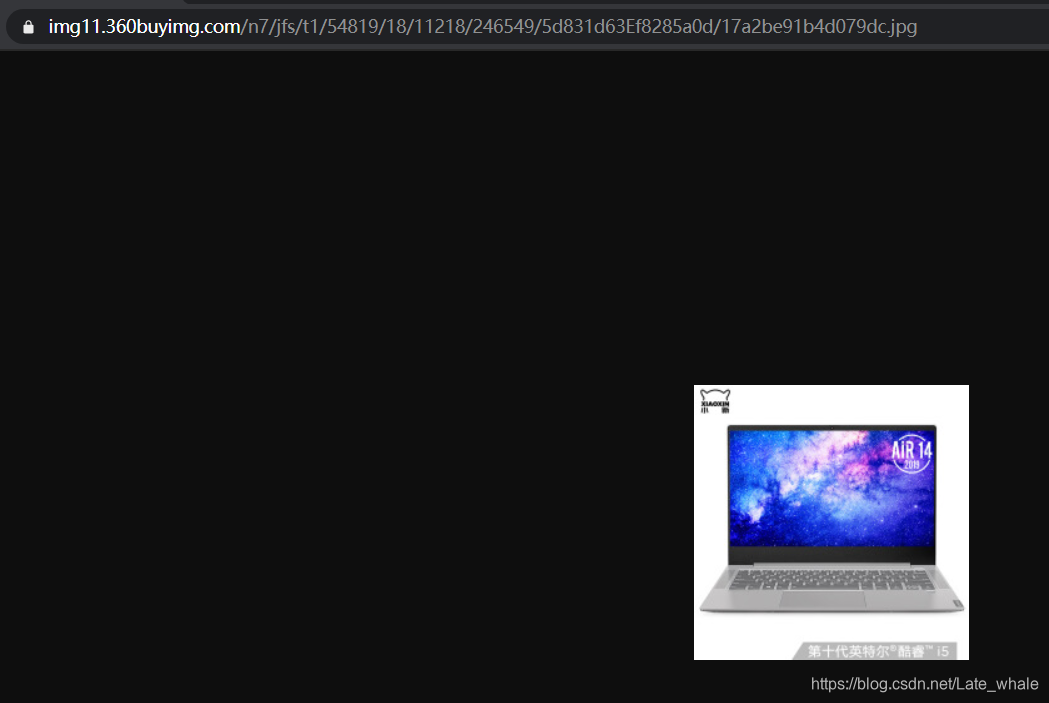
-
检查
检查构建之后的url链接有没有错误的
In:
import urllib.request import re def reptile(url,page): req=urllib.request.Request(url) #创建Request对象 #模拟浏览器 req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36")# 添加报头信息格式:对象名.add_header() data=urllib.request.urlopen(req).read()#打开网址 data=str(data) #获取标签数据 pattern1='<img width="220" height="220" data-img="1" src=".+?">' result=re.compile(pattern1).findall(data) result=str(result) #提取src pattern2='<img width="220" height="220" data-img="1" src="//(.+?\.jpg)">' result1=re.compile(pattern2).findall(result) for imageurl in result1: imageurl="http://"+imageurl print(imageurl) for i in range(1,8): url="https://list.jd.com/list.html?cat=670,671,672&page="+str(i) reptile(url,i)Out:
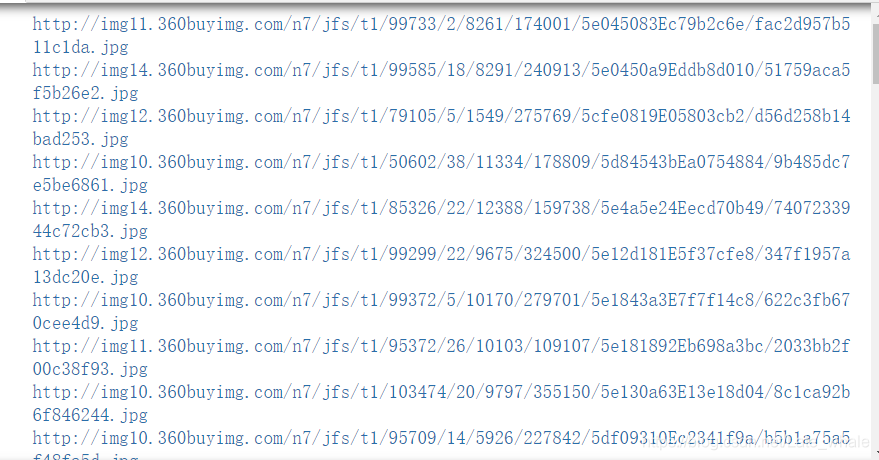
一定要仔细检查检查后无误
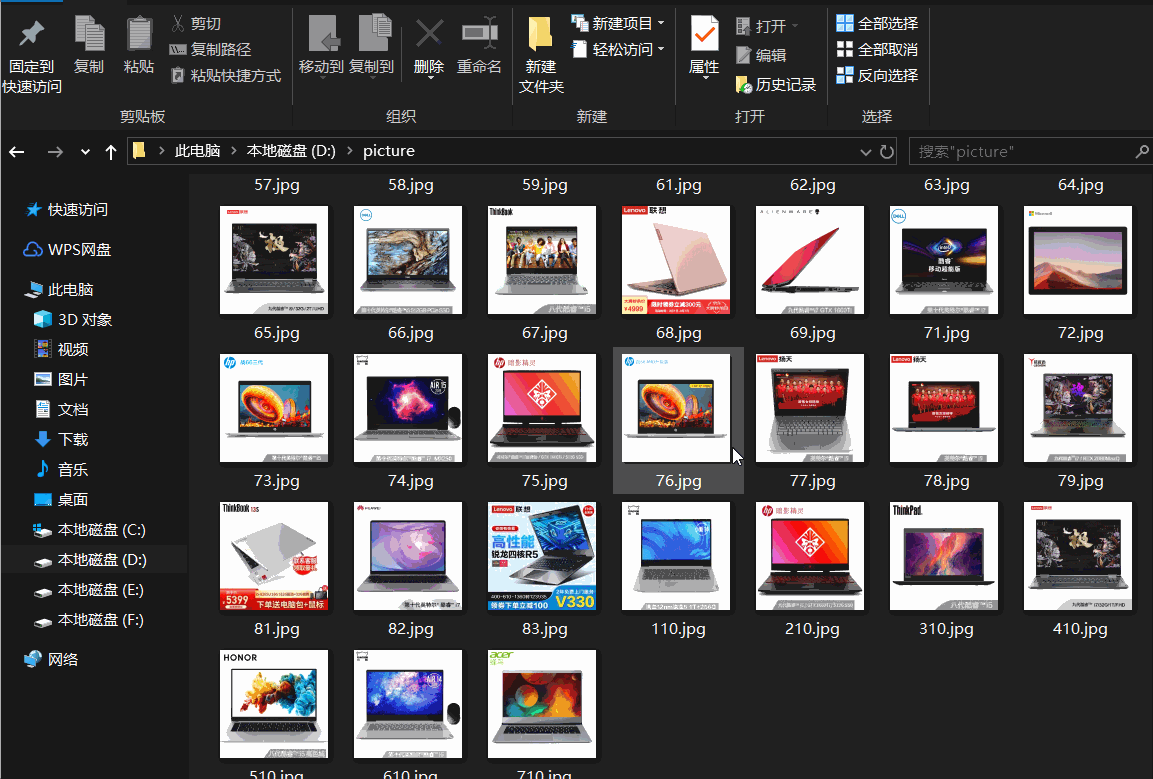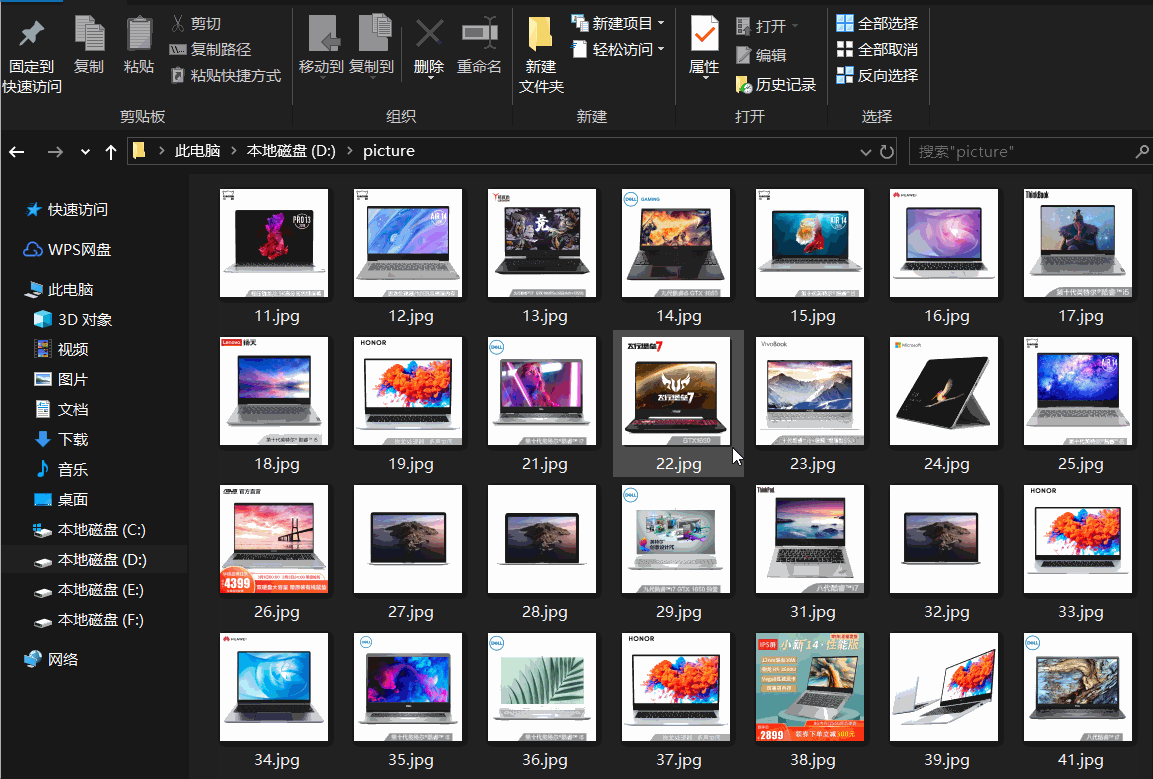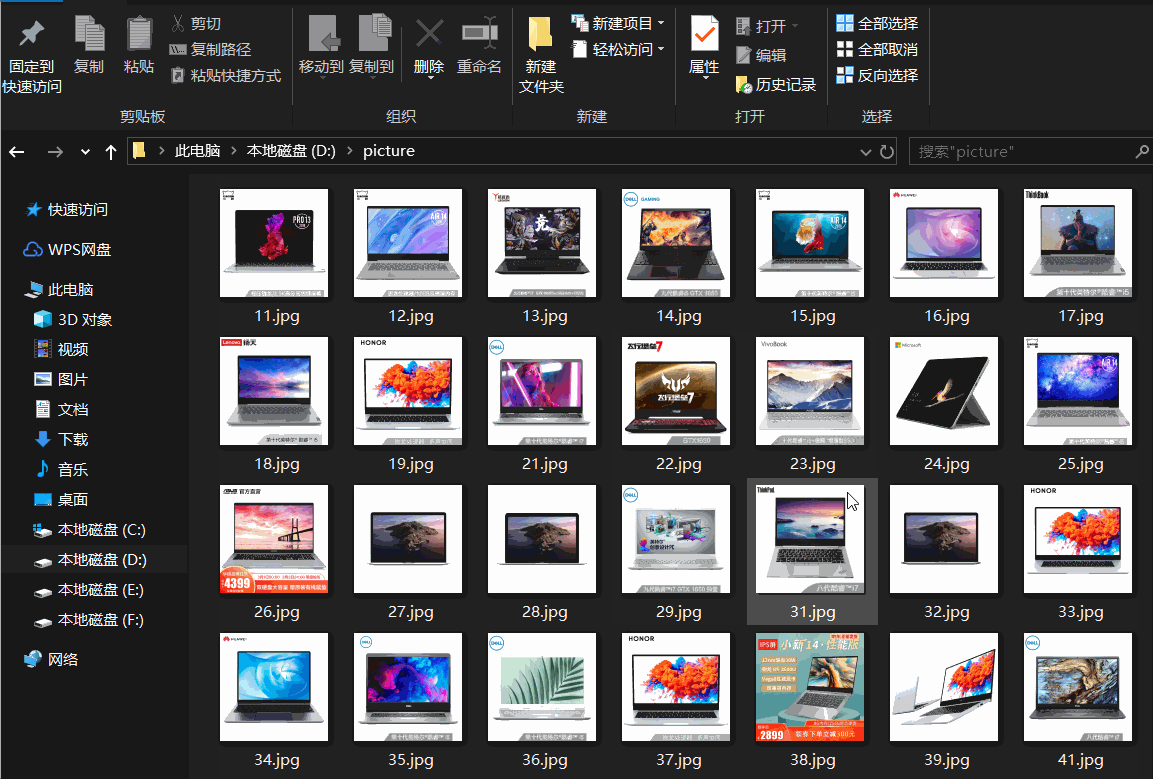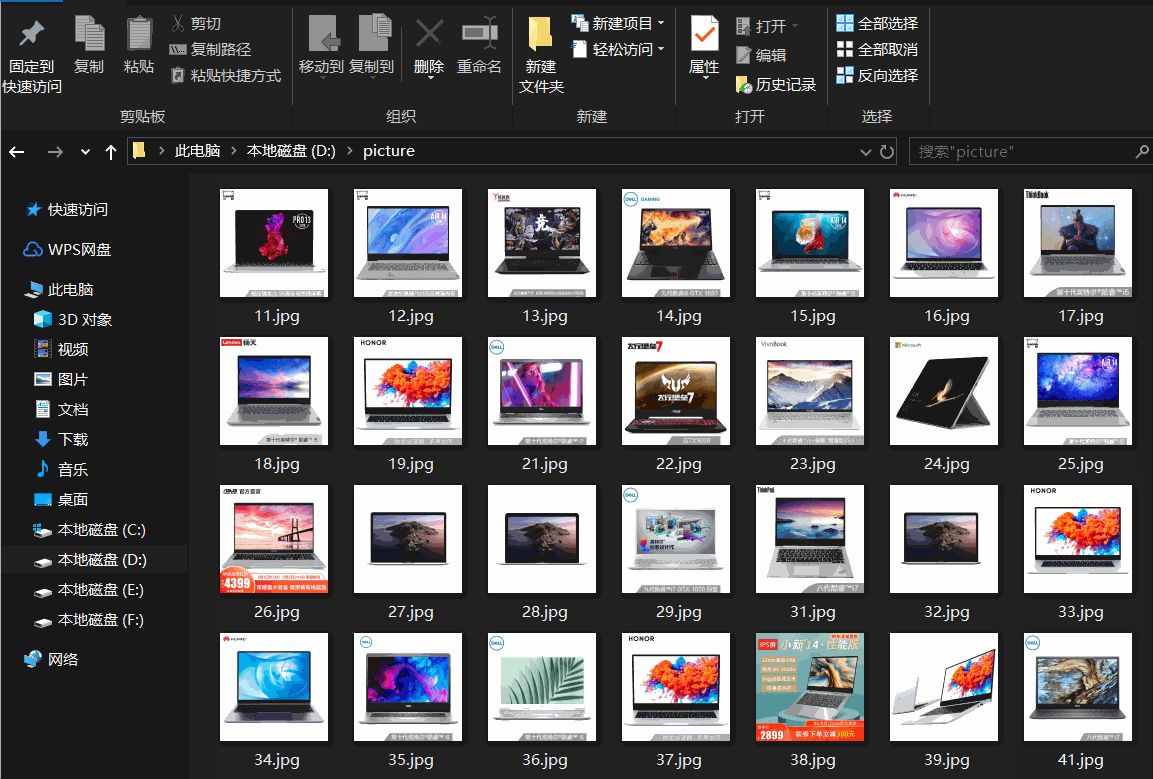
最终代码:
import urllib.request import re import http.client def reptile(url,page): req=urllib.request.Request(url) #创建Request对象 #模拟浏览器,最好用自己的 req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36")# 添加报头信息格式:对象名.add_header() data=urllib.request.urlopen(req).read()#打开网址 data=str(data) #获取标签数据 pattern1='<img width="220" height="220" data-img="1" src=".+?">' result=re.compile(pattern1).findall(data) result=str(result) #提取src pattern2='<img width="220" height="220" data-img="1" src="//(.+?\.jpg)">' result1=re.compile(pattern2).findall(result) x=1 #用于文件命名 #访问每页中的所有图片 for imageurl in result1: imagename="D:/picture/"+str(page)+str(x)+".jpg" imageurl="http://"+imageurl print(imageurl) x=x+1 #异常处理,否则一出问题程序就会终止 try: urllib.request.urlretrieve(imageurl,filename=imagename) except urllib.error.URLError as e: if hasattr(e,"code"): x+=1 if hasattr(e,"reason"): x+=1 except http.client.InvalidURL as f: #url异常 x+=1 for i in range(1,8): url="https://list.jd.com/list.html?cat=670,671,672&page="+str(i) reptile(url,i)成果: