文章目录
遍历文档树
演示文档(爱丽丝梦游仙境的一段内容)
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
"""
tag.contents
tag的 contents 属性可以将tag的子节点以列表的方式输出
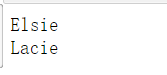
print(soup.body.contents)

可以通过列表的方法来获取某个元素的属性
print(soup.body.contents[1].name)
tag.children
获取tag的所有子节点并返回一个生成器,可用于迭代
for child in soup.body.children:
print(child)
print('------------------------------')

tag.descendants
获取tag的所有子孙节点
tag.strings
如果tag中包含多个字符串,即子孙节点中的内容可以用此获取后进行遍历
tag…stripped_strings
与tag.strings 用法一致,不同的是会去除多余的空白
tag.parent
获取tag的父节点
tag.parents
获取tag的父辈元素的所有节点,返回一个生成器
tag.previous_sibling
获取当前tag的上一节点,真实结果是当前标签与上一个标签之间的顿号和换行符
tag.next_sibling
获取tag的下一个节点,结果是当前标签与下一标签之间的顿号或换行符
tag.previous_siblings
获取tag的兄弟节点,返回一个生成器(用法见
tag.children)
tag.next_siblings
获取当前Tag的下一节点的所有兄弟节点,返回一个生成器**
tag.previous_element
获取解析过程中上一个被解析的对象(字符串或tag)
tag.next_element
获取解析过程中下一个被解析的对象(字符串或tag)
tag.previous_elements
向前访问文档的解析内容,返回一个生成器
tag.next_elements
向后访问文档的解析内容,返回一个生成器
tag.has_attr
判断tag是否有含有属性
搜索文档树
常用于搜索文档中的某些内容
演示文档(爱丽丝梦游仙境的一段内容)
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
"""
find_all(name,attrs,recursive,string,limit,**kwargs)
搜索当前节点的所有子节点,孙子节点等
-
name:查找所有名字为 name 的tag,name可接受的参数为字符串、正则表达式、列表、True
传入一个字符串参数,Beautiful Soup会查找与字符串完整匹配的内容
#字符串 find_a=soup.find_all('a') print(find_a)
如果传入正则表达式作为参数,Beautiful Soup会通过正则表达式的 match() 来匹配内容
#正则表达式 import re for tag in soup.find_all(re.compile("^b")): print(tag.name)
如果传入列表参数,Beautiful Soup会将与列表中任一元素匹配的内容返回
#列表 soup.find_all(["a", "p"])
可以匹配所有tag
#True for tag in soup.find_all(True): print(tag.name)
-
attrs:有些tag属性在搜索不能使用,比如HTML5中的 data-* 属性,定义一个字典参数来搜索包含特殊属性的tag
直接查询data-*属性会报错
t_list = soup.find_all(data-foo="value")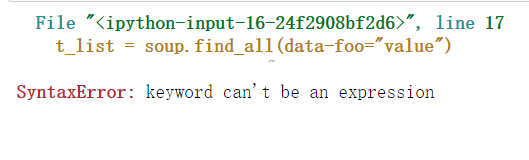
使用attr参数定义字典查找data-*属性
t_list = bs.find_all(attrs={"data-foo":"value"}) for item in t_list: print(item) -
recursive:调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False .
find_a=soup.find_all('title') print(find_a) find_a=soup.find_all('title',recursive=False) print(find_a)
-
string:通过 string 参数可以搜索文档中的字符串内容.与 name 参数的可选值一样, string 参数接受 字符串 , 正则表达式 , 列表, True
#字符串 print(soup.find_all(string="Elsie"))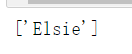
#列表 print(soup.find_all(string=["Tillie", "Elsie", "Lacie"]))
#正则表达式 print(soup.find_all(string=re.compile("sisters")))
#True print(soup.find_all(string=True))
-
limit:参数限制返回结果的数量
print(soup.find_all('a',limit=2))
-
** kwargs:如果一个指定名字的参数不是find_all()内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索
print(soup.find_all(id='link1'))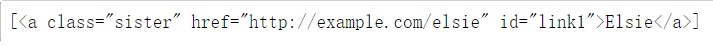
find_all(name,attrs,recursive,string,**kwargs)
find()与find_all()用法一致,唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回符合条件的第一个Tag
find_parents( name , attrs , recursive , string , **kwargs )
搜索当前节点的父辈节点,返回结果是值包含一个元素的列表
a_string = soup.find(string="Lacie")
print(a_string.find_parents('p'))

find_parent( name , attrs , recursive , string , **kwargs )
搜索当前节点的父辈节点,直接返回第一个结果
a_string = soup.find(string="Lacie")
print(a_string.find_parent('p'))

CSS选择器
Beautiful Soup支持大部分的CSS选择器,在 Tag 或 BeautifulSoup 对象的 .select() 方法中传入字符串参数, 即可使用CSS选择器的语法找到tag
演示文档(爱丽丝梦游仙境的一段内容)
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
"""
通过标签名查找
print(soup.select('title'))
print(soup.select('p'))

通过id名查找
print(soup.select("#link1"))
print(soup.select('#link2'))

通过class名查找
print(soup.select(".sister"))
print(soup.select("[class~=sister]"))

通过标签逐层查找
print(soup.select("html head title"))
print(soup.select('body a'))

查找某标签的直接子标签
print(soup.select("head > title"))
print(soup.select('p > b'))

查找某标签的兄弟节点标签
#匹配所有
print(soup.select("#link1 ~ .sister"))
#匹配一个
print(soup.select("#link1 + .sister"))

混合查找:匹配其中一个即可
print(soup.select("#link1,#link2"))

查询是否存在某属性,没有的返回空列表
print(soup.select('a[href]'))
print(soup.select('a[mm]'))

通过属性值来查找
print(soup.select('a[href="http://example.com/elsie"]'))
print('--------------------------------------')
print(soup.select('a[href^="http://example.com/"]'))
print('--------------------------------------')
print(soup.select('a[href$="tillie"]'))
print('--------------------------------------')
print(soup.select('a[href*=".com/el"]'))

获取标签内容
print(soup.select(".sister")[0].get_text())
print(soup.select(".sister")[1].get_text())