多线程爬虫介绍
- 在之前博客里(链接如下)爬取京东商品图片时,爬取流程是依次进行的,这种执行流程称为单线程结构,单线程结构的爬虫称为单线程爬虫
- 爬虫实战 爬取京东商城图片
- 多线程爬虫:爬虫中某部分程序可以并行执行,即多线程结构的执行流程称为多线程爬虫
多线程介绍
python中可以通过导入threading模块来使用多线程
import threading
定义类并继承threading.Thread类,则该类就是一个线程
#定义线程A
class Thread_A(threading.Thread):
def _init_(self):#初始化线程
threading.Thread._init_(self)
def run(self):#线程A需要做的事
pass
使用线程
a1=Thread_A () #实例化线程A
a1.start() #启动线程
不懂_init_()可以去看我之前的博客 python 继承、多态、特殊方法讲解
多线程爬虫实战
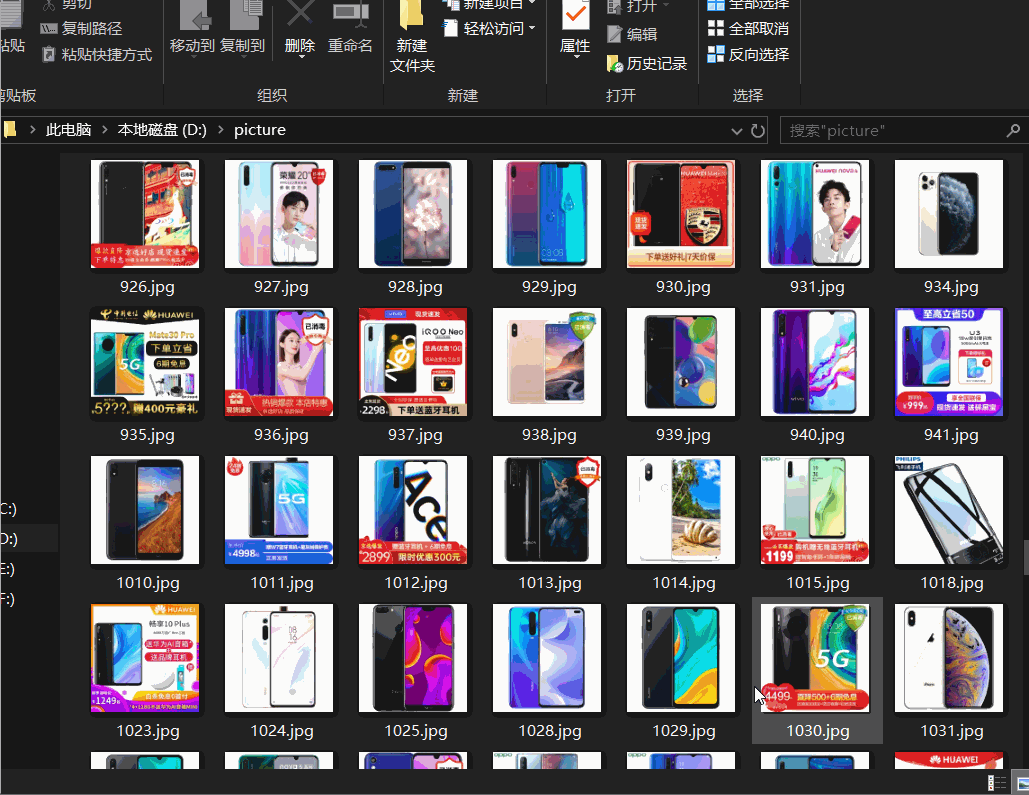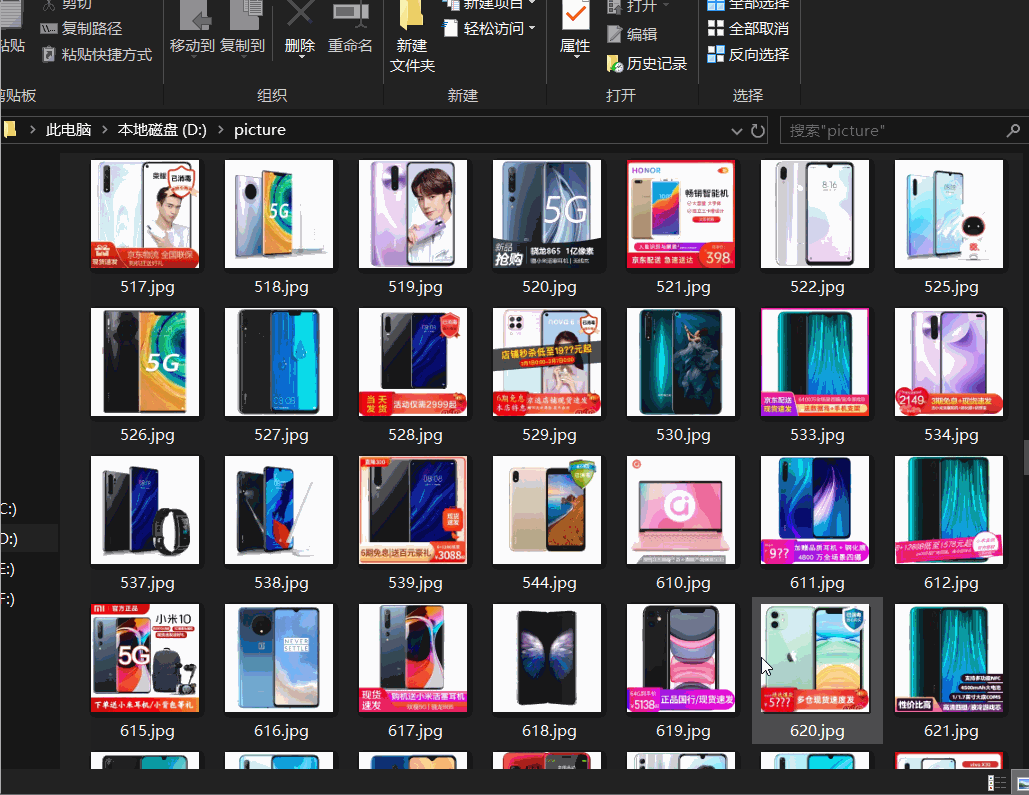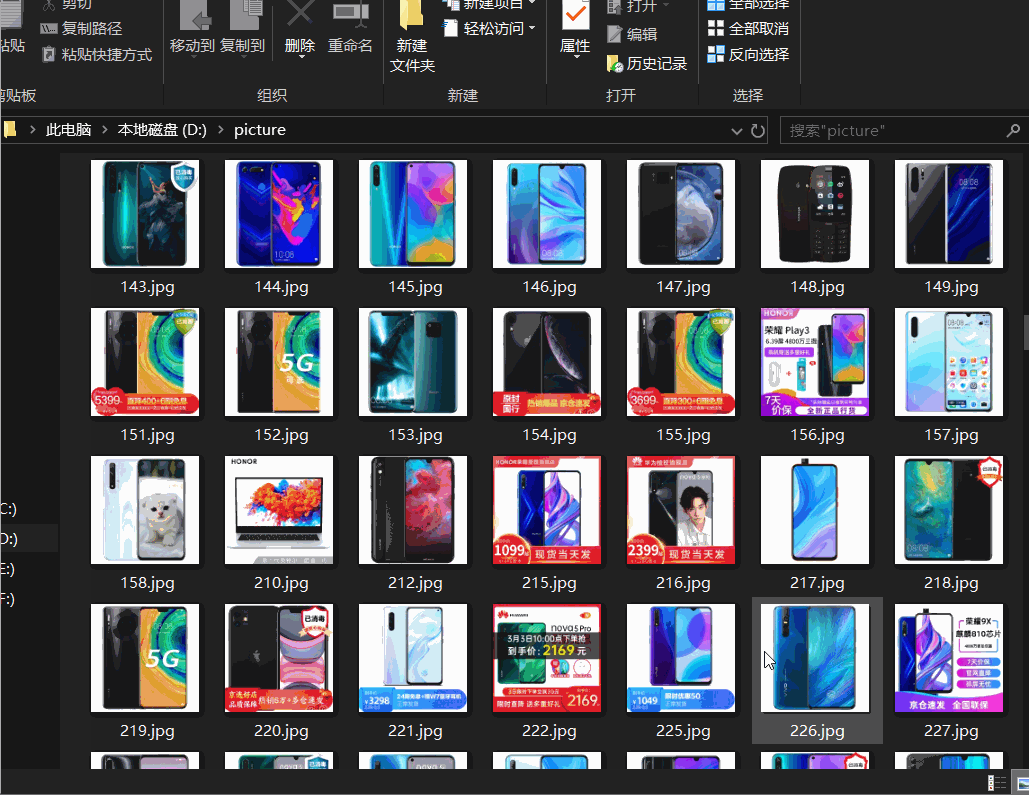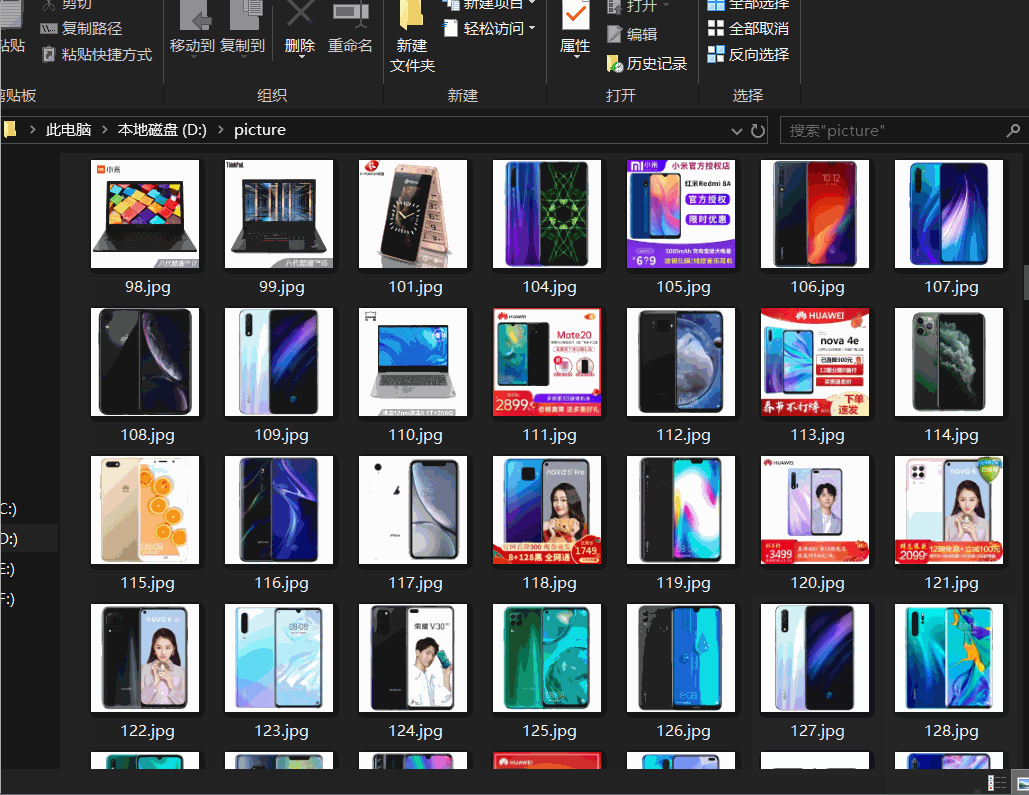
如果需要爬取京东商城40页手机图片,我们可以用四个线程分别来爬取8页,这就是常用的多线程.
这里我就只开两个线程进行爬取16页京东手机图片
import urllib.request
import re
import threading
import http.client
def reptile(url,page):
req=urllib.request.Request(url) #创建Request对象
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36")# 添加报头信息格式:对象名.add_header()
data=urllib.request.urlopen(req).read()#打开网址
data=str(data)
# pattern1='<a target="_blank" href=".+?">'
pattern1='<img width="220" height="220" data-img="1" data-lazy-img=".+?">'
result=re.compile(pattern1).findall(data)
result=str(result)
pattern2='<img width="220" height="220" data-img="1" data-lazy-img="//(.+?\.jpg)">'
result1=re.compile(pattern2).findall(result)
# print(result1)
x=1
print(result1)
for imageurl in result1:
imagename="D:/picture/"+str(page)+str(x)+".jpg"
imageurl="http://"+imageurl
x+=1
try:
urllib.request.urlretrieve(imageurl,filename=imagename)
except urllib.error.URLError as e:
if hasattr(e,"code"):
x+=1
if hasattr(e,"reason"):
x+=1
except http.client.InvalidURL as f: #url异常
x+=1
#线程A
class Thread_A(threading.Thread):
def _init_(self):#初始化线程
threading.Thread._init_(self)
def run(self):#线程A需要做的事
for i in range(1,8):
url="http://list.jd.com/list.html?cat=9987,653,655&page="+str(i)
reptile(url,i)
#线程B
class Thread_B(threading.Thread):
def _init_(self):#初始化线程
threading.Thread._init_(self)
def run(self):#线程A需要做的事
for i in range(9,16):
url="http://list.jd.com/list.html?cat=9987,653,655&page="+str(i)
reptile(url,i)
a1=Thread_A() #实例化线程A
a1.start() #启动线程
b1=Thread_B() #实例化线程B
b1.start() #启动线程
成果展示,因为之前爬取了一些电脑图片,所以有几张电脑图片在里面