概述
- 初阶数据库访问的步骤是【创建连接=>执行SQL=>关闭连接】,有如下不足:
1、创建数据库连接会浪费时间
2、大量访问时,频繁 GC 会导致CPU负载过高
3、如果改为不关闭连接,则会长期占用内存 - 对此,引入“缓冲池”思想:
在“缓冲池”中预备一定数量的数据库连接
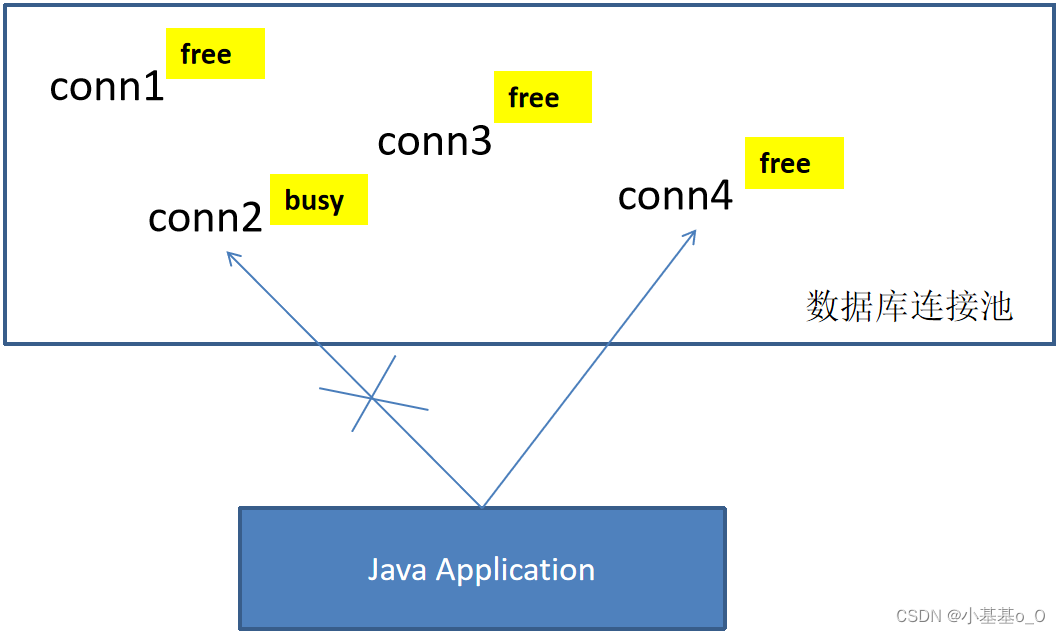
当需要访问数据库时,就从“缓冲池”中取出一个,用完后放回
当大量访问时,“缓冲池”中的数据库连接不够,就新建数据库连接
当访问量变少,就关闭部分数据库连接,减少到初始(下限)数量 - 数据库连接池(connection pool)
负责分配、管理和释放数据库连接
允许应用程序重复使用一个现有的数据库连接,而不是新建一个 - 数据库连接的数量下限:
连接池将保证一定数量的连接,即使它们没被使用 - 数据库连接的数量上限:
当 请 求 数 > 最 大 连 接 数 请求数>最大连接数 请求数>最大连接数 时,后面请求将被加入 等待队列 - 数据库连接池优点:
1、提高反应速度
2、充分而均衡地利用CPU和内存,降低 CPU高负载 或 内存泄漏 的风险
数据库连接池
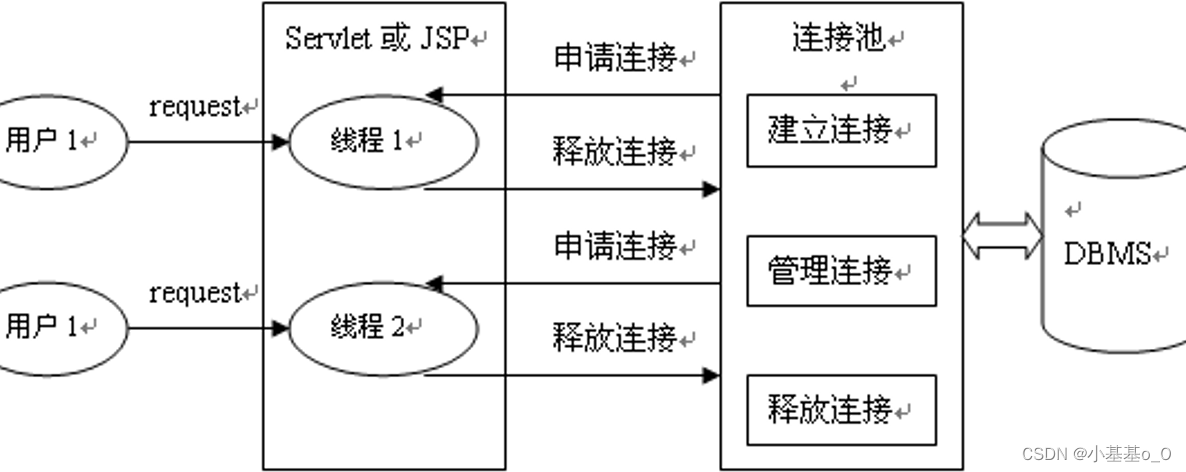
获取空闲的数据库连接
DRUID
DRUID是阿里巴巴开源平台上一个数据库连接池实现,代码如下
pom.xml
<!-- MySQL的JDBC -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.31</version>
</dependency>
<!-- 数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.15</version>
</dependency>
入门代码
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.pool.DruidPooledConnection;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Statement;
public class Hello {
public static void main(String[] args) throws SQLException {
//TODO 1 创建数据库连接池
DruidDataSource d = new DruidDataSource();
//TODO 2 设置MySQL基本连接参数
d.setDriverClassName("com.mysql.cj.jdbc.Driver"); //驱动全类名
d.setUrl("jdbc:mysql://localhost:3306"); //JDBC的URL
d.setUsername("root"); //数据库用户名
d.setPassword("123456"); //数据库密码
//TODO 3 设置缓冲池参数
d.setInitialSize(1); //初始化时的连接数
d.setMaxActive(2); //同时活跃的最大连接数
d.setMinIdle(1); //空闲时的最小连接数
d.setMaxWait(3000L); //用户等待最大毫秒数
//TODO 4 访问数据库
DruidPooledConnection c = d.getConnection();
//用于执行静态SQL并返回结果的对象
Statement s = c.createStatement();
//执行SQL(默认情况下,每个Statement对象只能同时打开一个ResultSet对象)
ResultSet r = s.executeQuery("SELECT 8 AS a,'x' AS b UNION ALL SELECT 9 AS a,'y' AS b");
//获取元数据
ResultSetMetaData m = r.getMetaData();
System.out.println(m.getColumnName(1) + "\t" + m.getColumnName(2));
//获取数据
while (r.next()) {
System.out.println(r.getInt(1) + "\t" + r.getString(2));
}
//释放ResultSet,释放Statement,归还数据库连接
r.close();
s.close();
c.close();
//TODO 5 连接数测试
(new MyThread()).start();
for (int i = 0; i < 3; i++) {
d.getConnection();
} //上面设置了最大连接数2,第3个连接超时3秒后报错
}
static class MyThread extends Thread {
@Override
public void run() {
for (int i = 1; i < 5; i++) {
try {
Thread.sleep(999L);
System.out.println("过了" + i + "秒");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
代码运行结果打印

封装数据库连接池工具类
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.pool.DruidPooledConnection;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Statement;
public class DatabaseConnectionPool {
private final DruidDataSource druidDataSource;
public DatabaseConnectionPool() {
druidDataSource = new DruidDataSource();
//始化时的连接数量
druidDataSource.setInitialSize(5);
//同时活跃的最大连接数
druidDataSource.setMaxActive(20);
//空闲时的最小连接数
druidDataSource.setMinIdle(1);
//获取连接等待的最大毫秒数,超时抛出异常,设-1表示一直等待
druidDataSource.setMaxWait(-1L);
//借出连接时 是否测试,false不测试 提升性能
druidDataSource.setTestOnBorrow(false);
//归还连接时 是否测试
druidDataSource.setTestOnReturn(false);
//每隔30秒运行一次 空闲连接回收器
druidDataSource.setTimeBetweenEvictionRunsMillis(30 * 1000L);
//池中 空闲30分钟的连接将被回收
druidDataSource.setMinEvictableIdleTimeMillis(30 * 60 * 1000L);
}
public void setDBCP(String driverClass, String jdbcUrl) {
druidDataSource.setDriverClassName(driverClass);
druidDataSource.setUrl(jdbcUrl);
}
public void setDBCP(String driverClass, String jdbcUrl, String user, String pwd) {
setDBCP(driverClass, jdbcUrl);
druidDataSource.setUsername(user);
druidDataSource.setPassword(pwd);
}
public void selectPrint(String sql) throws SQLException {
DruidPooledConnection c = druidDataSource.getConnection();
//获取 用于执行静态SQL并返回结果的对象
Statement s = c.createStatement();
//执行SQL(默认情况下,每个Statement对象只能同时打开一个ResultSet对象)
ResultSet r = s.executeQuery(sql);
//获取元数据
ResultSetMetaData m = r.getMetaData();
//获取列数
int columnCount = m.getColumnCount();
//打印列名
System.out.print("行号");
for (int i = 1; i <= columnCount; i++) {
System.out.print("\t|\t" + m.getColumnName(i));
}
System.out.println();
//打印数据
while (r.next()) {
System.out.print(r.getRow());
for (int i = 1; i <= columnCount; i++) {
System.out.print("\t|\t" + r.getObject(i));
}
System.out.println();
}
//释放ResultSet,释放Statement,归还数据库连接
r.close();
s.close();
c.close();
}
public static void main(String[] args) throws SQLException {
//测试
DatabaseConnectionPool d = new DatabaseConnectionPool();
d.setDBCP("com.mysql.cj.jdbc.Driver", "jdbc:mysql://localhost:3306", "root", "123456");
d.selectPrint("SELECT 8 AS a,'x' AS b UNION ALL SELECT 9 AS a,'y' AS b");
}
}