摘要:
深度学习作为一种新的资源密集型workload, 已在计算机视觉、语音、自然语言处理等方面得到了成功的应用。分布式深度学习已成为应对不断增长的数据和模型规模的必要手段。它的计算通常以简单的张量数据(Tensor)抽象为特征, 用于模型多维矩阵、数据流图到模型计算以及具有相对频繁同步的迭代执行, 从而使其大大不同于map/reduce的大数据计算。RPC 是常用的通信基元, 已被流行的深层学习框架 (如使用 gRPC 的 TensorFlow) 所采用。我们的工作表明, RPC 是分布式深度学习计算的子优化, 特别是在 RDMA 网络上。张量抽象和数据流图, 加上一个 RDMA 网络, 提供了减少不必要的开销 (如内存拷贝) 而不牺牲可编程性和通用性的机会。特别是, 从数据访问的角度来看, 远程计算机被抽象为 RDMA 通道上的 "设备", 具有用于分配、读取和写入内存区域的简单内存接口。我们的图形分析器同时查看数据流图和张量, 以优化内存分配和远程数据访问。结果在代表性的深度学习benchmark达到25×加速,对标准 gRPC 在 TensorFlow 上多达169% 改进, 对 RPC 实现优化为 RDMA, 使训练过程能更快的收敛。
2.背景和问题
2.2 RPC抽象

远程过程调用 (RPC) [8] 是跨服务器通信的常见抽象。它允许用户实现一个可以远程调用的过程, 就像在本地调用一样。使用 RPC, 用户只需关注远程过程的功能逻辑的实现, 而不用关心通信细节。此外, RPC 通常用于传递结构化消息, 因为它通常集成了序列化和反序列化为功能。有许多现有的设计和 (开放来源) 的 RPC [2, 4, 6, 19] 实现从业界和社区。它们已广泛应用于许多分布式系统 [35、33、9、7、21]。RPC 抽象通常假定一端到端之间的通信通道,该通道可以用于在运行时的任意时刻传输与数据架构和大小有关的任意类型的消息。由于主要数据抽象是张量(Tensor), 其元数据只包含具有形状和元素类型信息的简单架构, 所以这种方便在深层学习方案中并不特别有用。提供这一普遍的便利性有一个内在的成本: 它使得通信库很难事先知道接收到的消息应该直接传递到哪个用户缓冲区。有一种常见的方法是使用固定的库内缓冲区从操作系统层接收消息, 然后将数据复制到相应的用户缓冲区。
2.3 远程DMA
Remote Direct Memory Access
RDMA是Remote Direct Memory Access的缩写,通俗的说可以看成是远程的DMA技术,为了解决网络传输中服务器端数据处理的延迟而产生的。RDMA允许用户态的应用程序直接读取或写入远程内存,而无内核干预和内存拷贝发生。起初,只应用在高性能计算领域,最近,由于在大规模分布式系统和数据中心中网络瓶颈越来越突出,逐渐走进越来越多人的视野。
远程直接内存访问 (RDMA) 是一种新兴的快速网络技术, 它允许一台计算机直接访问任何主机上涉及操作系统的远程计算机的内存。随着技术的成熟和成本的竞争, RDMA 已经找到了它的方式进入数据中心, 并获得很大知名度 [26]。发出 RDMA 操作的用户界面是通过称为谓词的函数。有两种类型的谓词语义、内存谓词和消息传递谓词。内存谓词包括片面的 RDMA 读取、写入和原子操作。这些谓词指定在不涉及远程 CPU 的情况下操作的远程内存地址。远程端 CPU 开销的不足使它们具有吸引力。消息传递谓词包括发送和接收谓词, 其中涉及远程端 CPU。谓词由应用程序过帐到在 RDMA NIC 内维护的队列。队列始终存在于与发送队列和形成队列对的接收队列对之间。每个队列对都有一个关联的完成队列 (RDMA), 在谓词执行完成后, 它将填充它。RDMA 传输可以是可靠的或不可靠的, 或者连接或无关 (也称为数据报)。在我们的工作中, 我们总是使用可靠的连接运输。RDMA 网络提供了高带宽和低滞后时间: 具有 100 Gbps 带宽的 NIC 和∼2μs 的往返滞后时间是商业上可用的。RDMA 的高带宽及其绕核特性使通信相关的计算开销显著。我们观察到, 删除消息数据的额外拷贝可以明显提高通信效率。只需在 RDMA 上构建一般的 RPC 抽象, 就很难避免这些数据复制开销。例如, 在场[16] RPC 中使用的消息传递机制在接收方的每个通道上采用,
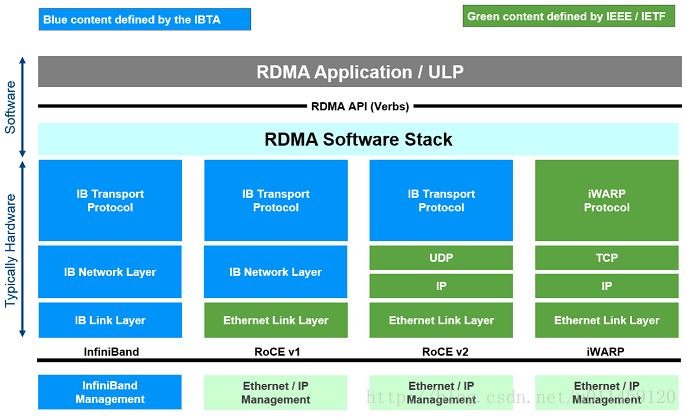
- Infiniband,支持RDMA的新一代网络协议。 由于这是一种新的网络技术,因此需要支持该技术的NIC和交换机。
- RoCE,一个允许在以太网上执行RDMA的网络协议。 其较低的网络标头是以太网标头,其较高的网络标头(包括数据)是InfiniBand标头。 这支持在标准以太网基础设施(交换机)上使用RDMA。 只有网卡应该是特殊的,支持RoCE。
- iWARP,一个允许在TCP上执行RDMA的网络协议。 IB和RoCE中存在的功能在iWARP中不受支持。 这支持在标准以太网基础设施(交换机)上使用RDMA。 只有网卡应该是特殊的,并且支持iWARP(如果使用CPU卸载),否则所有iWARP堆栈都可以在SW中实现,并且丧失了大部分RDMA性能优势。
并可能遭受§2.2 中描述的问题。RDMA 的单侧内存读写语义允许在远程地址已知的情况下跨服务器进行零拷贝通信。在深入学习的计算场景中, 数据流图分析可以帮助安排张量的内存放置, 并将这些信息提供给底层通信层。这使得我们相信, 直接公开简单的内存复制接口是最合适的, 因为张量是在深度学习计算期间需要跨服务器传输的主要数据类型。
3.5 GPUDirect RDMA
GPUDirect RDMA 是一种技术, 允许 RDMA NIC 直接访问 gpu 内存, 从而实现远程直接访问 gpu 内存而不经过主机内存, 进一步减少内存拷贝时, 将被转移的张量数据在 GPU 内存。根据我们工作中的设计原则和方法, 应用 GPUDirect RDMA 很简单, 因为在用户级, 它同样需要通过 CUDA API [1] 在映射固定模式中分配一个 GPU 内存空间, 并向 RDMA NIC 注册, 并且图形分析器可以根据§3.4 中的描述, 确定需要以这种方式分配的张量。在 GPU 内存中有效地轮询一个值是相对困难的。在某个地址进行轮询时, 发布 GPU 内核可能会招致内核启动的大量开销, 并且使用内核函数反复轮询地址, 直到状态就绪, 才会浪费宝贵的 GPU 计算资源。因此, 我们总是采用3.3 节中描述的动态分配机制, 通过 GPUDirect RDMA 进行张量传递。具体地说, 可以在主机内存中维护张量的元数据, 因此轮询只发生在 CPU 端, 而实际张量数据可以存储在 GPU 内存中, 并通过片面的 RDMA 读取来传输。
4.实现
我们在 TensorFlow (r1.2) [3] 中实施我们的技术, 这是社区和工业中流行的开放源码的深入学习框架。我们的实现包含约4000行 c++ 代码, 其中 RDMA 通信库 (使用 Linux 上的 libibverbs API) 大约需要1800行, 其余的是对 TensorFlow 包括图形分析器的修改。TensorFlow 将深度学习计算作为数据流图进行组织。用户首先通过其高级 Python 或 c++ 接口构建一个图形, 然后通过将关系图与运行时会话关联来启动深层学习计算。图由张量和算子组成。运算符引用相应图形节点的计算操作, 而张量表示通过连接节点的边的数据。用户还可以开发定制的操作员, 并添加到图表中。与在图形生成阶段中由用户添加的正常计算运算符不同, 发送和接收运算符 (用于沿图形分区的边缘传输张量数据) 将由框架添加到图表中, 并且是透明的, 以用户。为了实现§3中描述的 RDMA 张量数据的传输机制, 我们开发了两对自定义算子, 并引入了一个扩展调度机制。为了在静态位置上传输张量, 我们实现了 RdmaSend 和 RdmaRecv 算子。在图分析阶段, 接收张量与 RDMAaccessibility 已预分配, 并设置为 RdmaRecv 的性质。这个张量永远不会被释放, 直到整个计算完成, 所以它的地址永远不会改变整个计算。然后将该张量的远程可访问地址传递给保存相应 RdmaSend 运算符并设置为其属性的服务器。一旦 RdmaSend 计划执行, 它会通过单面 RDMA 写入直接更新接收张量的内容。这里不需要一些特殊的机制来通知 RdmaSend, 转移张量已被 RdmaRecv 使用, 因为 RdmaSend 的下一次调度执行自然保证在收到的张量因控制而消耗后发生。关系图中循环的依赖性或多个小批处理迭代的连续执行。同样, 我们还实现了另一对运算符、RdmaSendDyn 和 RdmaRecvDyn, 用于支持在§3中描述的动态分配的张量转移。TensorFlow 最初有两种类型的运算符执行模式: 同步和异步执行。对于这两种类型的运算符, 一旦从就绪队列中弹出一个运算符即可执行, 它只需同步或异步完成其执行, 而无需再次排队到就绪队列中。但是, RdmaRecv 和 RdmaRecvDyn 需要对接收张量的数据或元数据缓冲区中的标志字节进行轮询。如果完全远离调度机制, 则它可能会因周期性睡眠而浪费处理器资源或长时间延迟而遭受繁忙循环。因此, 我们引入了一种新的执行模式, 称为轮询-异步运算。此类运算符的执行包含两个阶段。在轮询阶段执行时, 计划程序检查轮询是否成功。如果没有, 它只是重新 enqueues 这个操作符到准备队列的尾部;否则, 它会将运算符的执行模式更改为异步并重新安排执行。这样, 当有其他准备就绪的操作员执行时, 我们就减少了轮询开销。
未完待续~