一、SVM回归模型的损失函数
SVM不仅可以用于分类模型,也可以用于回归模型。回顾SVM分类模型,目标函数是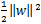 最小,同时让训练集的数据点尽量远离自己类别一边的支持向量,即
最小,同时让训练集的数据点尽量远离自己类别一边的支持向量,即
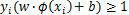 。如果加入松弛变量
。如果加入松弛变量
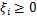 ,则目标函数是
,则目标函数是
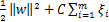 ,对应的约束条件是
,对应的约束条件是
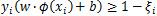
回归模型的优化目标函数可以和SVM分类模型保持一致,为
,但约束条件不是让训练集的数据点尽量远离自己类别一边的支持向量,因为回归模型没有类别,回归模型的目标是让训练集中的每个点尽量拟合到一个线性模型
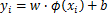 。一般的回归模型用模型输出与真实输出之间的均方差来计算损失,SVM则定义了一个常量偏差ε>0,只有模型输出与真实输出差的绝对值大于ε时才计算损失,相当于以
。一般的回归模型用模型输出与真实输出之间的均方差来计算损失,SVM则定义了一个常量偏差ε>0,只有模型输出与真实输出差的绝对值大于ε时才计算损失,相当于以
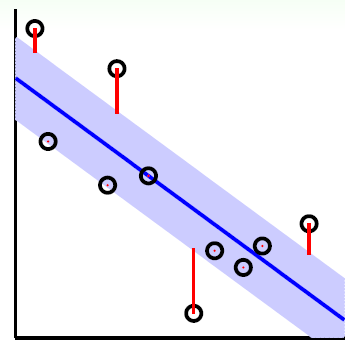
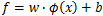 为中心,构建了一个宽度为2ε的间隔带,若样本落入间隔带内,则认为预测正确。如下图所示,在蓝色条带内的点没有损失,外面的点有损失,损失大小为红色线的长度。
为中心,构建了一个宽度为2ε的间隔带,若样本落入间隔带内,则认为预测正确。如下图所示,在蓝色条带内的点没有损失,外面的点有损失,损失大小为红色线的长度。
SVM回归模型的损失函数度量为:

二、SVM回归模型的目标函数
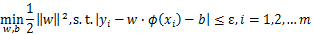
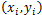 引入松弛变量,绝对值两边都需要松弛变量,定义为
引入松弛变量,绝对值两边都需要松弛变量,定义为
 ,则SVM回归模型的损失函数度量在加入松弛变量后变为:
,则SVM回归模型的损失函数度量在加入松弛变量后变为:
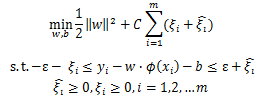
 将目标优化函数变成无约束的形式如下:
将目标优化函数变成无约束的形式如下:
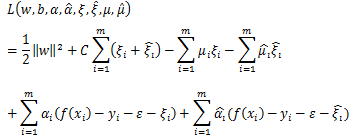


 的极小值,通过偏导数求得:
的极小值,通过偏导数求得:
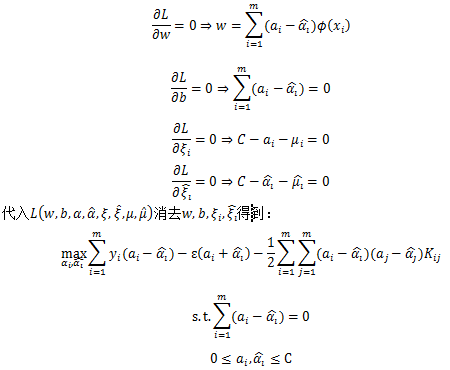
对目标函数求极小值可以得到:

 ,进而求出回归模型系数w,b
,进而求出回归模型系数w,b
三、SVM回归模型系数的稀疏性
