题目:
老师安排我们爬取豆瓣图书,恰好想学,所以把爬取的过程按照顺序写下来,主要是留个痕迹。在文中我会把爬虫所需的所有代码以图片形式一一讲解,图片里的代码就是全部的爬虫代码!!!如果你懒得自己敲的话,我上传了代码在:代码在此处,有需要的可以自取。
步骤一:
引入包。我用的request和beautifulsoup4。request是进行http请求。而有一点前端知识,懂得css样式的人用beautifulsoup4进行页面解析比较方便。

步骤二:
添加header信息。设置header信息,模拟成浏览器或者app欺骗反爬系统,避免418。我刚开始的时候没有设置头部等信息,导致被豆瓣网站识别出来了,给我返回了“<[response418]>”。这个header我是在网上找的,如果想设置自己浏览器的header信息,请自行百度,很简单。

步骤三:
获取网页信息且解析网页,我爬取的是网页是:豆瓣图书—小说。
同学们如果自己想看看解析的网页,可以在得到soup后,“print(soup.text)”打印一下解析后的网页

步骤四:
从解析的文本中通过select选择器定位目标,返回一个列表。通过select()选择,返回的是一个列表!!!我先把代码给出来:
 有同学会疑问select(“h2“)、select(”div.pub“)…这些是怎么来的。1.首先进入刚才的网页:豆瓣图书—小说;2.按下F12键,右侧会弹出边框,该边框的最左上角有一个”选择元素按钮“(快捷键为ctrl+b);3.在点击了”元素选择器”后,将鼠标移到左侧网页上,你可以使用鼠标点击你想要获取的网页模块;4.点击相应的网页模块后,右侧框会定位到你所点击模块的css样式位置,在这儿你可以看到该模块的html中css。5.此时得到的css样式就可以填入select()中,爬虫程序会根据select()中的css样式,定位到待爬取网页的内容,从而爬取数据信息。以下以得到小说的title为例。
有同学会疑问select(“h2“)、select(”div.pub“)…这些是怎么来的。1.首先进入刚才的网页:豆瓣图书—小说;2.按下F12键,右侧会弹出边框,该边框的最左上角有一个”选择元素按钮“(快捷键为ctrl+b);3.在点击了”元素选择器”后,将鼠标移到左侧网页上,你可以使用鼠标点击你想要获取的网页模块;4.点击相应的网页模块后,右侧框会定位到你所点击模块的css样式位置,在这儿你可以看到该模块的html中css。5.此时得到的css样式就可以填入select()中,爬虫程序会根据select()中的css样式,定位到待爬取网页的内容,从而爬取数据信息。以下以得到小说的title为例。
1。按F12键弹出,选择“选择元素“
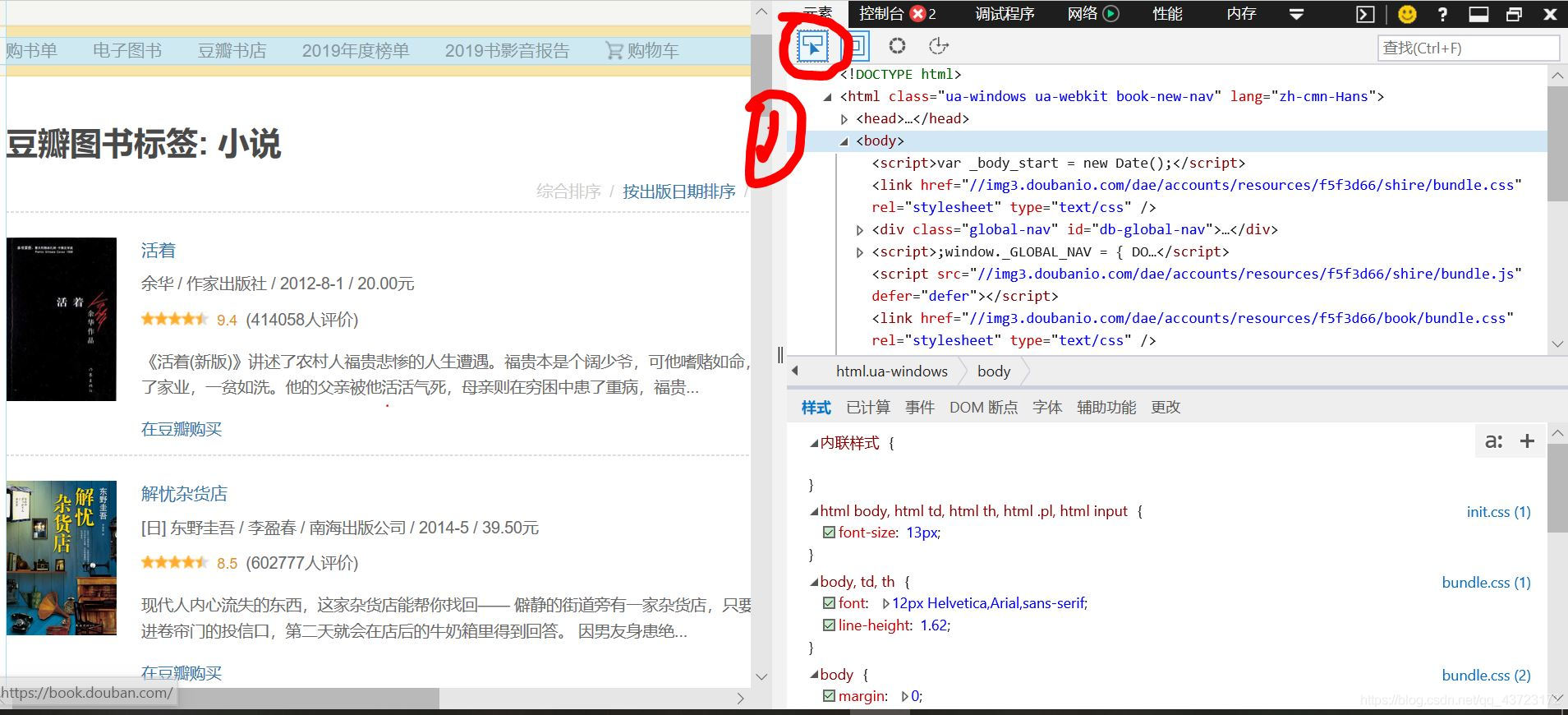
2.点击了”选择元素“后,用鼠标点击左侧想要获取的数据,右侧框中会定位到该位置

3.所以在代码中则有select(“h2”)。只是讲了大概,至于beautifulsoup4中的select()具体用法,里面有组合选择等等,请同学自行百度“BeautifulSoup的select函数的使用”,因为涉及侵权所以不便贴出我所学习的链接。
步骤五:
从列表中将数据一一对应的取出,python中zip()可以把两个或者两个以上的迭代器封装成生成器,strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
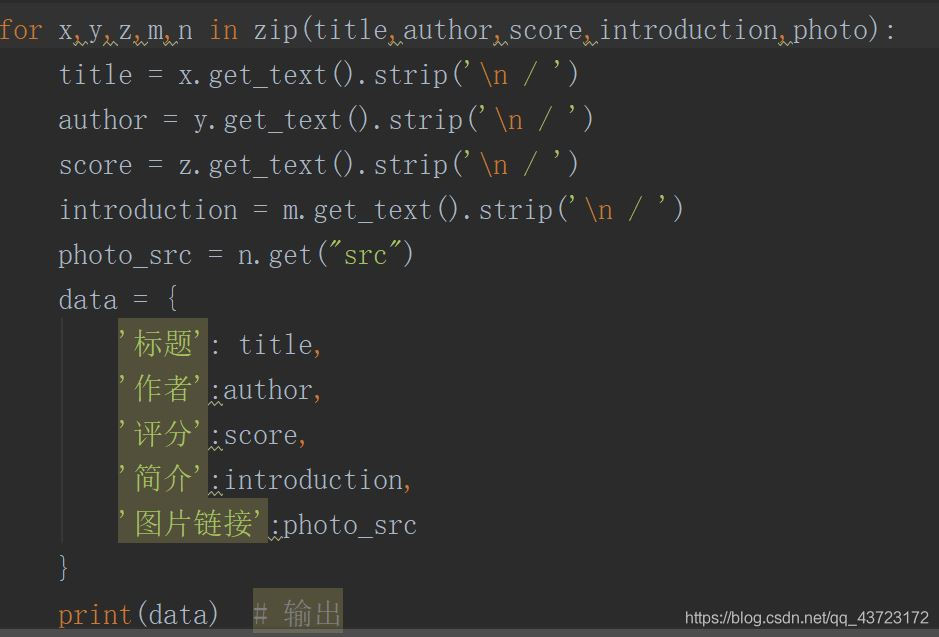
结果:

篇末闲话,这个代码只是爬取了豆瓣图书中标签分类为“小说”的一些数据,如果想自动爬去此页面:https://book.douban.com/tag/?view=type&icn=index-sorttags-all分类中的所有数据。
那么提供一个思路:按照上述的方法解析这个页面,获取每个标签的链接;再将步骤三中从url后的代码到步骤五的所有代码定义为函数,该函数需要传入的参数定义为url,而刚才获取的每个标签的链接传入该函数,这样就能实现自动爬取所有标签内的数据
