一个简单的爬取豆瓣最受关注图书榜的小爬虫,在爬取相关信息后,将结果保存在 mongo 中
整个流程分为以下几步:
(1)构造url
(2)分析网页
(3)编写程序,提取信息
解析,将分别介绍以上几步
一 构造url
首先打开网页,可以看到下面的图片
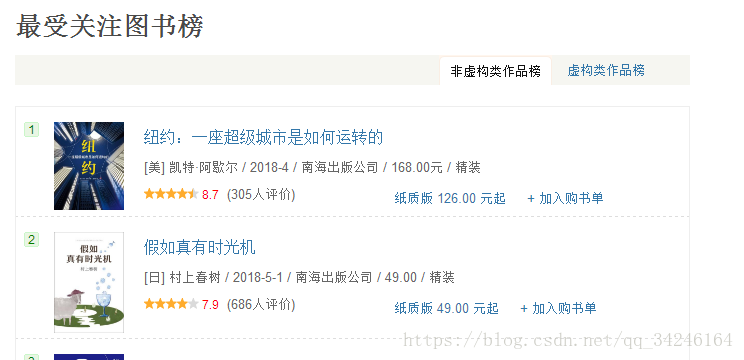
从图片中,可以看到其分为虚构类作品榜和非虚构类作品榜两个榜单,分别点击这两个榜单,可以看到其下面的变化
非虚构类作品榜:

虚构类作品榜:
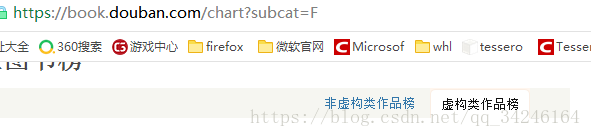
因此,根据这两个变化,可以构造相应的榜单的 url。
接下来分析,源代码页面
二 分析网页
分析源代码页面,可以看到,每一本书的信息,都是包含在
<li class="media clearfix">
因此,便可以提取对应的信息了
三 编写程序,提取信息
经过上面的分析,便可以编写程序,提取信息了。源码如下:
import requests
from pyquery import PyQuery as pq
import pymongo
client = pymongo.MongoClient('mongodb://localhost:27017/')
db = client['douban']
collection = db['douban']
def html_get(url_start, key_list):
for keyword in key_list: #构造url
url = url_start + keyword
headers={'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',\
'Accept-Encoding':'gzip, deflate, sdch, br',\
'Accept-Language':'zh-CN,zh;q=0.8',\
'Cache-Control':'max-age=0',\
'Connection':'keep-alive',\
'Cookie':'ll="129059"; bid=LGKvV4eiPRY; gr_user_id=5e12d333-3fef-4dec-9a13-492827d22a9f; __yadk_uid=mdRyurjdvN9YpaTediph1fGvXm5kFwDv; _pk_ref.100001.3ac3=%5B%22%22%2C%22%22%2C1530035830%2C%22http%3A%2F%2Fwww.so.com%2Flink%3Fm%3DatcFavfrIqqbjFSuBtImGs6LQuG1bzV%252BwXIUv9RvMyu76xYAgQ1zKuR6VXzhExd6NGqKRNCgBJUSrQwjAFlBd9UixoDzpOIwO%22%5D; Hm_lvt_16a14f3002af32bf3a75dfe352478639=1530035976; Hm_lpvt_16a14f3002af32bf3a75dfe352478639=1530035976; viewed="30155720_26830570_30230525"; gr_session_id_22c937bbd8ebd703f2d8e9445f7dfd03=62136c96-12c5-410f-975e-954ef37fe69b_true; _vwo_uuid_v2=DB79F3914C55D5BDCBACD8F77796784E0|a988dff47123f572c5efd29563436c85; _pk_id.100001.3ac3=bca92b247691e53a.1529798027.2.1530037201.1529798070.; _pk_ses.100001.3ac3=*; __utma=30149280.317649996.1529798022.1529798022.1530035826.2; __utmb=30149280.29.10.1530035826; __utmc=30149280; __utmz=30149280.1530035826.2.2.utmcsr=so.com|utmccn=(referral)|utmcmd=referral|utmcct=/link; __utma=81379588.1306981855.1529798027.1529798027.1530035830.2; __utmb=81379588.29.10.1530035830; __utmc=81379588; __utmz=81379588.1530035830.2.2.utmcsr=so.com|utmccn=(referral)|utmcmd=referral|utmcct=/link; ap=1',\
'Host':'book.douban.com',\
'Referer':'https://book.douban.com/chart?subcat=F',\
'Upgrade-Insecure-Requests':'1',\
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',}
try:
r = requests.get(url, headers=headers) #请求网页
html = r.text
except:
print('error')
else:
html_parse(html) #调用提取信息的函数
def html_parse(html):
item = {}
doc = pq(html)
for media in doc.find('.media').items(): #提取信息
item = {
'book_name': media.find('h2').text(),
'abstract': media.find('.subject-abstract').text(),
'score': media.find('.font-small').text(),
'score_people': media.find('.ml8').text().replace('(','').replace(')',''),
}
save_to_mongo(item) #调用存储函数
def save_to_mongo(item):
collection.insert(item) #存储信息
def main():
url_start = 'https://book.douban.com/chart?subcat='
kwy_list = ['I','F'] #关键词
html_get(url_start, key_list)
client.close()
if __name__ == '__main__':
main()