质量、速度、廉价,选择其中两个
这篇文章将会用到上一篇文章所讲的内容,如果没有看过可以去看一下教你用Python写excel
今天我们要做的就是用Python爬取豆瓣图书Top250,先打开网站看一下

今天不谈这豆瓣图书top250垃圾不垃圾的问题,只看看怎么用python把数据爬取下来,首先先来看网页结构,一个界面只有25本书,一共十个界面,点击切换可以发现界面的切换可以通过参数start控制
比如说https://book.douban.com/top250?start=0代表的就是第一页,https://book.douban.com/top250?start=1代表的就是第二页,像这样的界面有10个
那我们要爬取哪些信息呢,有书名 ,点击跳转的超链接 ,作者、出版商、售价,评分,评论人数,介绍
打开网址,chrome浏览器右键检查或者F12,firefox可以右键查看元素,浏览html结构
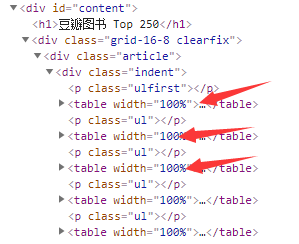
每一个table中就是一本书的信息,我们只要按规则抽取就好了,现在准备一下步骤
- 循环10个网址
- 请求网址
- 抽取数据
- 保存到xlsx里
请求网址可以使用requests来做,直接 requests.get(target_url) 一步到位,主要问题在抽取数据上,在这方面,我们可以使用BeautifulSoup,Beautiful Soup是一个Python包,功能包括解析HTML、XML文档、修复含有未闭合标签等错误的文档。这个扩展包为待解析的页面建立一棵树,以便提取其中的数据,这在网络数据采集时非常有用,该库可以说是爬虫利器啊
book = requests.get(target_url)
soup = BeautifulSoup(book.text, 'lxml')我们使用lxml作为解析器,构建BeautifulSoup对象
table = soup.findAll('table', {"width": "100%"})调用findAll,找到所有符合条件的节点,第一个参数是标签名称,第二个参数是要求,这里是找到所有宽度为100%的table标签,该方法返回的是一个列表
然后我们只需要按步骤取数据就好了,比如书名就是table.div.a.text

网页上有换行和空格,我们需要把这些不需要的东西去掉,可以使用replace方法替换掉
r_name = name.replace('\n', '').replace(' ', '')如果你想取一个标签的一个属性可以通过键值对的形式取,比如数据链接
url = item.div.a['href']要注意一点就是信息并不总是完整的,有时可能空缺,如果你没有做处理依旧去取这个值那么程序便会报错,比如这个书籍描述就不是所有书都有
最后保存xlsx里,上一篇文章说过,直接调用那个方法就可以了

附上一段完整程序
import re
import requests
from bs4 import BeautifulSoup
import xlsxwriter
def save_excel(fin_result, tag_name, file_name):
book = xlsxwriter.Workbook(r'%s.xlsx' % file_name)
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num+2):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-2] # -2是因为当i=2时下标应为0
tmp.write_row(con_pos, content)
book.close()
def book(target_url):
books = []
book = requests.get(target_url) # 使用requests返回网页的整体结构
soup = BeautifulSoup(book.text, 'lxml') # 使用lxml作为解析器,返回一个Beautifulsoup对象
table = soup.findAll('table', {"width": "100%"}) # 找到其中所有width=100%的table标签),即找到所有的书
for item in table: # 遍历table,一个item代表一本书
name = item.div.a.text.strip() # 找到书名
r_name = name.replace('\n', '').replace(' ', '') # 通过看网页的HTML结构,可以发现书名后是有换行以及空格的,将这些全部通过replace替换去除
url = item.div.a['href'] # 获取书的链接
info = item.find('p', {"class": "pl"}).text # 获取书的信息
score = item.find('span', {"class": "rating_nums"}).text.strip() # 获取分数
nums = item.find('span', {"class": "pl"}).text.strip() # 获取评价人数
num = re.findall('(\d+)人评价', nums)[0] # 通过正则取具体的数字
if item.find('span', {"class": "inq"}): # 判断是否存在描述
desc = item.find('span', {"class": "inq"}).text.strip()
else:
desc = 'no description'
books.append([r_name, url, info, score, num, desc]) # 以元组存入列表
return books # 返回一页的书籍
result=[]
for n in range(10):
url1 = 'https://book.douban.com/top250?start=' + str(n*25) #top250的网页,每页25本书,共10页,“start=”后面从0开始,以25递增
result+= book(url1)
title_list=["书名","网址","作者/出版社/售价","评分","评论人数","介绍"]
print(result)
save_excel(result,title_list,"booktop250")