from lxml import etree
import requests
import csv
fp = open('doubanBook.csv', 'wt', newline='', encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(('name', 'url', 'author', 'publisher', 'date', 'price', 'rate', 'comment'))
urls = ['https://book.douban.com/top250?start={}'.format(str(i)) for i in range(0,250,25)]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36'
}
for url in urls:
html = requests.get(url, headers=headers)
selector = etree.HTML(html.text)
infos = selector.xpath('//tr[@class="item"]')
for info in infos:
name = info.xpath('td/div/a/@title')[0]
url = info.xpath('td/div/a/@href')[0]
book_infos = info.xpath('td/p/text()')[0]
author = book_infos.split('/')[0]
publisher = book_infos.split('/')[-3]
date = book_infos.split('/')[-2]
price = book_infos.split('/')[-1]
rate = info.xpath('td/div/span[2]/text()')[0]
comments = info.xpath('td/p/span/text()')
comment = comments[0] if len(comments) != 0 else "空"
writer.writerow((name, url, author, publisher, date, price, rate, comment))
fp.close()
这里爬取书名、书籍豆瓣地址、作者、出版社、出版时间、价格、评分、一句书评。爬取完的效果图如下:
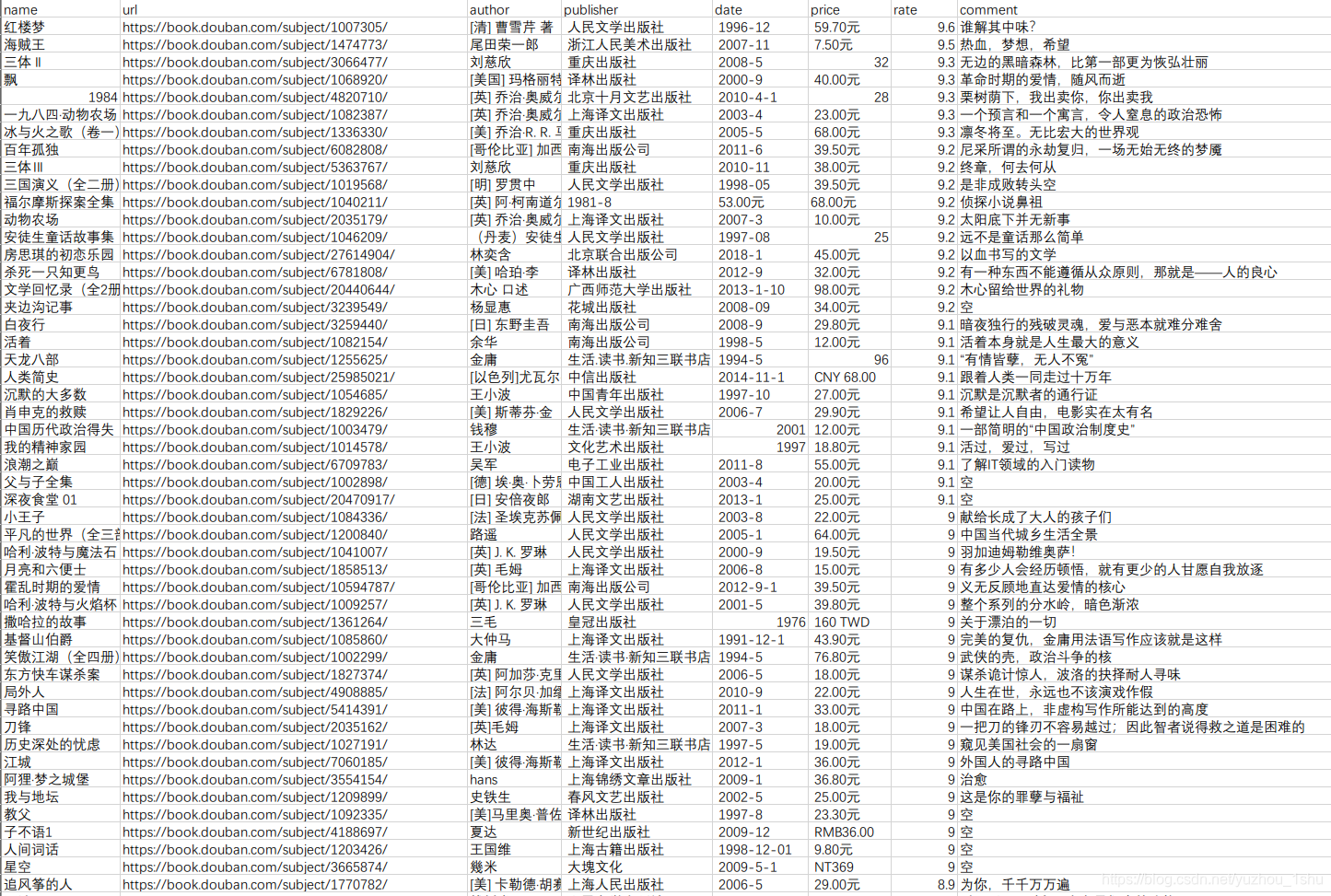
完整爬取完Top250如下图:
