Python爬取豆瓣网图书信息
(一)爬虫思路:
# 爬虫思路汇总:
# ①,https://book.douban.com/tag/ 总书签首页
# 抓取豆瓣图书书签上所有的书签名字,并保存为一个数组
# 当输入一个标签时,根据标签去生成对应的网址。如果标签不存在数组中,提示帮助,然后显示这个标签数组内容
# ②,多线程爬取豆瓣图书信息
# 1,爬取图书名字跟作者
# 2,爬取图书对应的链接
# 3,爬取图书的简介信息
# 4,爬取图书的豆瓣评分
# ③,将数据储存在xls表格中,按标签分类命名xls文件。
# 按一定条件排序:评分或者默认排序
# 项目目的:
# ①,熟悉xpath提取与正则 ②,熟悉threading多线程
# ③,熟悉表格输出操作openpyxl模块操作
# ④,熟悉文件存取操作本次代码通过自主学习 openpyxl 与threading模块,完成了后面部分的要求,爬取了对应的 书名—作者—豆瓣评分—参与评分总人数—地址链接,这里没有对简介信息做操作,考虑到文字太多表格存储不方便。所以就没弄了,影响不大。
(二)源代码讲解:
Ⅰ. 总标签分类的获取
- 由于时间问题,这里就直接给贴上我的源代码,个人觉得代码注释已非常详细,很容易就能看懂。
- 由于没有用 scrapy 框架,而是用的单个文件,所以我把 获取标签的总分类单独用一个文件来写这个程序了。然后把获取书本信息也单独用一个文件来写了。其实这个并不影响。因为我们可以通过导入文件来是两个 .py 文件能够连接起来。具体导入操作:
- 通过 sys模块来完成: 打开计算机–> cmd–>输入一下指令
# 先进入Python环境
>>> ipython
>>> import sys
>>> # 查看所有包路径
>>> sys.path
>>> # 添加刚才自己所写的包的路径
>>> sys.path.append("D://douban/")在完成上面的添加之后,在某一个程序文件中就可以用 import 来导入我们想导入的文件了。给出我获取总分类标签的源码:
''' 将标签信息储存到表格 '''
import urllib.request
import re
from lxml import etree # 使用xpath筛选器
from user_agent.base import generate_user_agent
from openpyxl import Workbook, load_workbook # 用于创建 和 读取 表格文件
from openpyxl.styles import colors, Font, Alignment, Border, Side # 改变字体颜色,大小, 对其方式, 边框
goabal tag_list
tag_list = [] # 用来存储所有分类标签下的子标签
def url_open(url):
head = {"User-Agent": generate_user_agent()}
req = urllib.request.Request(url, headers=head)
response = urllib.request.urlopen(req).read()
return response
# 获取首页书签,并存为表格
def get_mark(url):
response = url_open(url).decode('utf-8')
html = etree.HTML(response, parser=None, )
# 获取标签总分类的列表
categories = html.xpath('//a[@class="tag-title-wrapper"]/@name')
# 获取《文学》下的标签分类
# 匹配出文学分类下包含的所有标签内容
literature_string = re.compile('(<a name="文学" class="tag-title-wrapper">\s(\s|.)*?\s</div>)').findall(response)[0][0]
# 实例化对象为可xpath操作的对象,xpath返回列表
html = etree.HTML(literature_string, parser=None, )
literature_string = html.xpath('//td/a/text()')
# 保存第一个标签分类
yield save_main_mark(row=main_row_start, value=categories[0])
# 保存第一个标签下的子标签
yield save_mark(literature_string)
# 获取《流行》下的标签分类
popular_string = re.compile('(<a name="流行" class="tag-title-wrapper">\s(\s|.)*?\s</div>)').findall(response)[0][0]
html = etree.HTML(popular_string, parser=None, )
popular_string = html.xpath('//td/a/text()')
yield save_main_mark(row=main_row_start, value=categories[1])
yield save_mark(popular_string)
# 获取《文化》下的标签分类
culture_string = re.compile('(<a name="文化" class="tag-title-wrapper">\s(\s|.)*?\s</div>)').findall(response)[0][0]
html = etree.HTML(culture_string, parser=None, )
culture_string = html.xpath('//td/a/text()')
yield save_main_mark(row=main_row_start, value=categories[2])
yield save_mark(culture_string)
# 获取《生活》下的标签分类
life_string = re.compile('(<a name="生活" class="tag-title-wrapper">\s(\s|.)*?\s</div>)').findall(response)[0][0]
html = etree.HTML(life_string, parser=None, )
life_string = html.xpath('//td/a/text()')
yield save_main_mark(row=main_row_start, value=categories[3])
yield save_mark(life_string)
# 获取《经管》下的标签分类
manage_string = re.compile('(<a name="经管" class="tag-title-wrapper">\s(\s|.)*?\s</div>)').findall(response)[0][0]
html = etree.HTML(manage_string, parser=None, )
manage_string = html.xpath('//td/a/text()')
yield save_main_mark(row=main_row_start, value=categories[4])
yield save_mark(manage_string)
# 获取《科技》下的标签分类
technology_string = re.compile('(<a name="科技" class="tag-title-wrapper">\s(\s|.)*?\s</div>)').findall(response)[0][0]
html = etree.HTML(technology_string, parser=None, )
technology_string = html.xpath('//td/a/text()')
yield save_main_mark(row=main_row_start, value=categories[5])
yield save_mark(technology_string)
# 传入分类value,储存主分类,文学,流行...etc
def save_main_mark(row, value):
# 如果是第一次就创建表格
if main_row_start == 1:
wb = Workbook() # 创建工作表
ws1 = wb.active # x选中工作表中的第一个sheet,_active_sheet_index属性默认为 0
ws1.title = "标签" # 更改sheet1的名字为标签
ws1.sheet_properties.tabColor = "1072BA" # sheet1的背景颜色,有RRGGBB确定
else:
wb = load_workbook(filename="豆瓣图书.xlsx",)
ws1 = wb.active # x选中工作表中的第一个sheet,_active_sheet_index属性默认为 0
ws1.merge_cells(start_row=row, start_column=1, end_row=row, end_column=4) # 合并单元格 A1-D1 ,ws1.merge_cells('A1:D4')
ws1.cell(column=1, row=row, value=value).font=Font(color=colors.RED, italic=None, size=18, bold=True,) # 操作单元格,红色,加粗
ws1.cell(column=1, row=row, value=value).alignment = Alignment(horizontal="center", vertical="center")
wb.save(filename="豆瓣图书.xlsx")
row_start = 2 # 从第二行开始
main_row_start = 1 # 标签分类从一行开始
# 存储子分类。
def save_mark(x):
# 定义全局变量方便每次都能按顺序自动存储
global row_start
global main_row_start
tag = 0
wb = load_workbook(filename="豆瓣图书.xlsx",)
ws1 = wb.active
# 设置第row行行高为30
# ws1.row_dimensions[row].height = 30
# 设置第col列列宽为20
for col in 'ABCD':
ws1.column_dimensions[col].width = 20
# 储存为 7*4 的表格
for row in range(row_start, row_start+10):
for col in range(1, 5):
# 设置字体
ws1.cell(row=row, column=col, value=x[tag]).font = Font(color='EE6A50', size=14, bold=True,)
# 设置对其格式
ws1.cell(row=row, column=col, value=x[tag]).alignment = Alignment(horizontal="center", vertical="center")
# 设置边界样式
ws1.cell(row=row, column=col, value=x[tag]).border = Border(
top=Side(color='EE6A50'), left=Side(color='EE6A50'), right=Side(color='EE6A50'), bottom=Side(color='EE6A50'))
tag += 1 # 将标签内容移位
if tag == len(x): # 判断数据是否保存完
main_row_start = row + 1 #
row_start = main_row_start + 1 #
wb.save(filename="豆瓣图书.xlsx")
return None # 用来结束循环
if __name__ == "__main__":
url = "https://book.douban.com/tag/"
save = get_mark(url)
print("正在处理,请稍后...")
for fun in save: # for循环会自动调用 next()方法,和处理StopIteration(溢出)异常
pass
print("--------------Finished!---------------")
个人觉得使用Xpath比使用BeautifulSoup要方便,可能因为用习惯了。还有就是这里频繁的使用了 yield 语句,这样做事我后来改的,因为发现不然在处理表格格式的时候回比较麻烦。
还有一个比较需要注意的地方,就是 Python 如何退出循环语句,一开始以为像 C那样,只要再后面加一个 break 就万事大吉了,然而并没有什么卵用。结束循环的方法有两个:①,通过主动raise一个Error然后对这个Error进行处理。 ②,通过return 语句
这里创建了一个tag_list的数组,用来存储所有的标签,方便另一个程序使用这些标签来生成对应链接。达到前面所说的目的。不过我没有进行这一步,因为这可以留到后面优化程序的时候做。但是,后面出现了个意外,在我调试这个程序的时候 IP被被封了,所以就没弄了。。。等风头过去再来试试。下个准备写个获取代理IP的,这样就不怕了。。。好啦,下面是部分效果图:
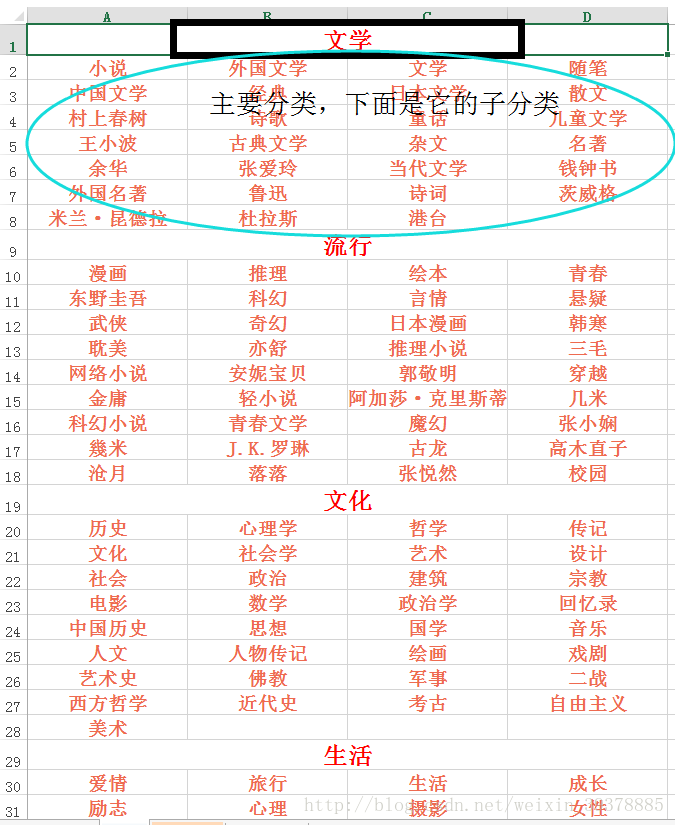
关于表格有关操作,有时间再单独写一篇,这里就不多说了,因为我也是自己一步一步慢慢跟着官方文档摸索的,所以在代码中有关表格的地方都写的很详细。我觉得不能再详细。。。不然全是中文了。有想法的可以去看下openpyxl 的官方文档。openpyxl官方文档
II。书本基本信息的获取
- 这里使用了多线程的另一种形式,那就是创建类,然后用来继承 threading.Thread 这个类,通过重写override它的run方法来实现多线程。
- 这里一个使用了三个类,也就是线程。
-
第一个,Book() 用来获取基本信息,书名,作者,星级.etc
第二个,Save() 用来保存获取到的信息到表格,只保存某一页
第三个,Hanlder() 用来处理保存数据之后的表格,达到美观的效果
其实这里如果爬取某一页的话 开三个线程是没有必要的,因为三个程序都有必然的先后顺序关系,并不能实现并行执行,所以这里只是为了看上去更加直观。当然,如果要爬去所有的页面数据的话,还是可以实现伪并行的。为什么叫伪并行呢…具体看代码就知道了。中间我使用了 queue队列来储存信息,这样方便数据的提取。跟前面一样,代码的注释非常详细,所以这里给出代码:
'''
表格格式为:title,author,rating_nums, comment_nums, link
'''
import urllib.request, urllib.parse
import urllib
from user_agent.base import generate_user_agent
import threading
from lxml import etree
from openpyxl import Workbook, load_workbook # 导入创建和加载工作簿的库文件
from openpyxl.styles import Font, colors, Alignment # 导入工作簿样式所需的库文件,字体,颜色,对齐方式
from openpyxl.worksheet.table import Table, TableStyleInfo # 导入工作表中制作表格所需的库文件,table, 表格风格
import queue # 产生队列,先进先出.Queue()
information = queue.Queue()
url_queue = queue.Queue()
import time
import re
# 获取内容标签下某一页内容
class Book(threading.Thread):
def __init__(self, url, queue):
super().__init__()
self.url = url
self.queue = queue
def url_open(self, url):
head = {"User-Agent" : generate_user_agent()}
req = urllib.request.Request(url, headers=head)
response = urllib.request.urlopen(req).read()
return response
def run(self):
print("正在获取网站信息...\n地址:%s\n" % self.url)
response = self.url_open(self.url).decode('utf-8')
# 使用HTML解析网页
response = etree.HTML(response, parser=None)
book_name = response.xpath('//h2/a/@title')
# 对获取的数据进行格式处理
book_author = []
book_authors = response.xpath('//div[@class="pub"]/text()')
for each in book_authors:
temp = each.replace(' ','').strip()
book_author.append(temp.split("/")[0])
rating_num = []
rating_nums = response.xpath('//span[@class="rating_nums"]/text()')
for each in rating_nums:
rating_num.append(float(each))
comment_num = []
comment_nums = response.xpath('//span[@class="pl"]/text()')
for each in comment_nums:
comment_num.append(int(''.join(re.findall(r'[0-9]', each))))
book_link = response.xpath('//h2/a/@href')
info_zip = list(zip(book_name, book_author, rating_num, comment_num, book_link))
self.queue.put(info_zip,timeout=None,)
self.queue.task_done()
# 用来保存某一页的内容
class Save(threading.Thread):
def __init__(self, queue, filename, sheetname):
super().__init__()
self.queue = queue
self.filename = filename
self.sheetname = sheetname
def run(self):
i = 2
wb = load_workbook(filename=self.filename) # 打开已有表格
ws2 = wb.create_sheet(title=self.sheetname)
# 添加第一行数据
ws2.merge_cells("E1:I1")
ws2.append(("书名", "作者", "豆瓣评分", "评价人数", "链接地址"))
# 判断数据是否存完,True则等待,False 则继续
while self.queue.empty() is False:
print("正在保存数据到表格,请稍后...")
content = self.queue.get() # 从队列中取数据
print("此页包含 %d 个数据" %len(content))
for row in content:
ws2.merge_cells(start_column=5, start_row=i, end_column=9, end_row=i)
i += 1
ws2.append(row) # 添加行数据
wb.save(filename=self.filename)
print("数据保存完成!")
hanlder.start()
hanlder.join()
# 用来处理文档的格式
class Hanlder(threading.Thread):
def __init__(self, queue, filename, sheetname):
super().__init__()
self.queue = queue
self.filename = filename
self.sheetname = sheetname
def run(self):
try:
if self.queue.empty() is True: # 若数据已保存完毕
wb = load_workbook(filename=self.filename) # 打开已有表格
print("正在处理表格样式,请稍后...")
ws2 = wb[self.sheetname] # 选择某一个工作表 ws2 = wb.worksheets[1] 通过索引获取或名字wb["name"]
ws2.sheet_properties.tabColor = "DDA0DD" # 设置工作表背景色
# 设置列宽
ws2.column_dimensions['A'].width = 20
ws2.column_dimensions['B'].width = 28
ws2.column_dimensions['C'].width = 12
ws2.column_dimensions['D'].width = 15
ws2.column_dimensions["E"].width = 20
# 设置对齐与字体
for cells in ws2["A1:E1"]:
for cell in cells:
cell.alignment = Alignment(horizontal="center", vertical="center") # 第一行对齐
cell.font = Font(size=16, color="A020F0", bold=True)
row_length = (ws2.max_row) # 获得包含数据的总行数int sheet.rows 为返回所有行(含数据)可用来迭代
col_length = ws2.max_column # 获取总列数
for row in range(2, row_length+1):
for col in range(1, col_length+1):
ws2.cell(row=row, column=col).alignment = Alignment(horizontal="center", vertical="center") # 居中对齐
ws2.cell(row=row, column=col).font = Font(size=12, color="B452CD", bold=True) # 字体
ws2.cell(row=row, column=col_length).alignment = Alignment(horizontal="left", vertical="center") # 最后一列左对齐
'''
因为 表中包含数字,而openpyxl规定,ref过滤器范围必须始终包含字符串,否则Excel会报错并删除表格,应该是这样
# 制作成表格
# Add a default style with striped rows and banded columns
style = TableStyleInfo(name="TableStyleMedium9", showFirstColumn=False,
showLastColumn=False, showRowStripes=True, showColumnStripes=True)
tab = Table(displayName="书名信息表", ref="A1:C21",tableStyleInfo=style)
ws2.add_table(tab)
'''
wb.save(self.filename)
print("格式处理完成!")
except PermissionError as e:
print("表格已被打开,请先关闭! %s" %e)
if __name__ == "__main__":
tag = "小说"
tag_encode = urllib.parse.quote(tag) # 编码中文
filename = "豆瓣图书.xlsx"
sheetname = tag
for page in range(0, 1000, 20):
url = "https://book.douban.com/tag/{tag}?start={int}".format(tag=tag_encode, int=page)
Book(url=url, queue=information).start()
save = Save(queue=information, filename=filename, sheetname=sheetname)
hanlder = Hanlder(queue=information, filename=filename, sheetname=sheetname)
time.sleep(1)
save.start()
这里要注意的是,小说分类下的网站是含有中文名的,所以需要处理,对中文进行编码。通过 urllib.parse.quote()。
目标获取 小说 标签下的1000本图书,不过实际过得为997本,发下部分效果图吧:
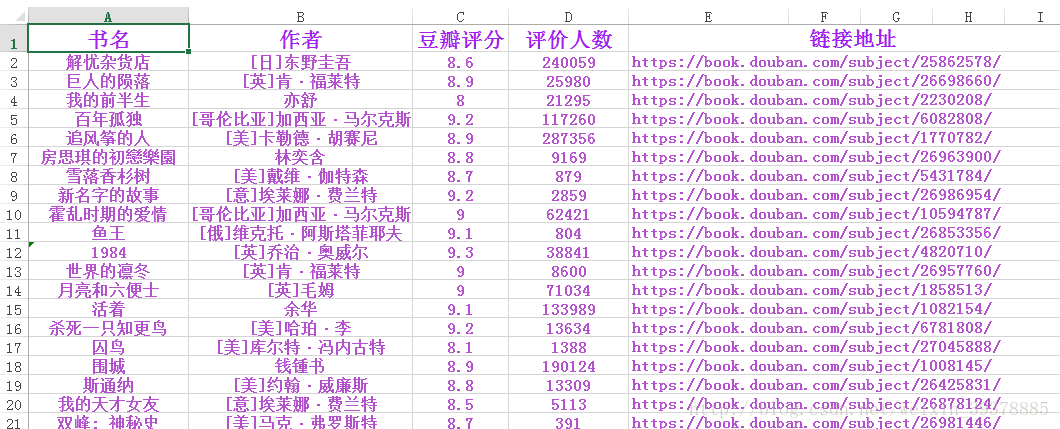
还有就是,上面 Book()中 获取到的数据都通过了处理,这里看下网页结构就明白了,感觉该说的代码里都已经注释了,写的不好,还请指正。