

先来看看页面长啥样的:https://book.douban.com/top250
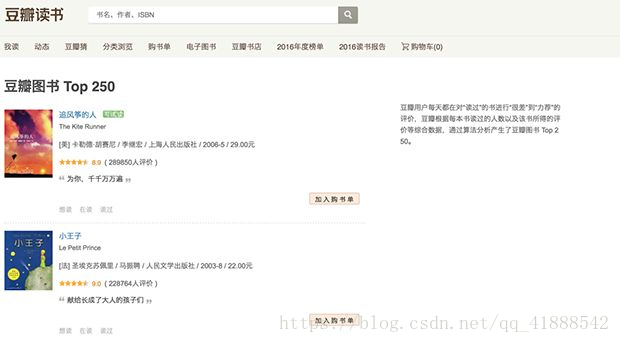
我们将要爬取哪些信息:书名、链接、评分、一句话评价……
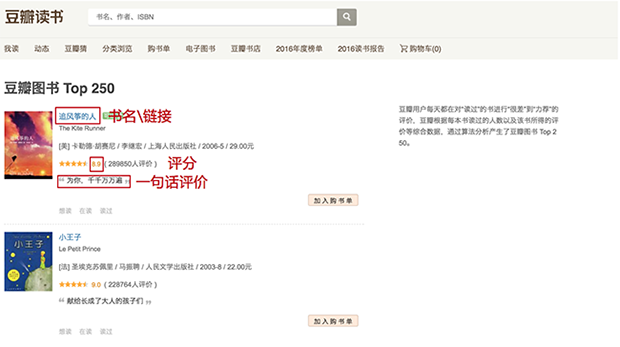
1. 爬取单个信息
我们先来尝试爬取书名,利用之前的套路,还是先复制书名的xpath:
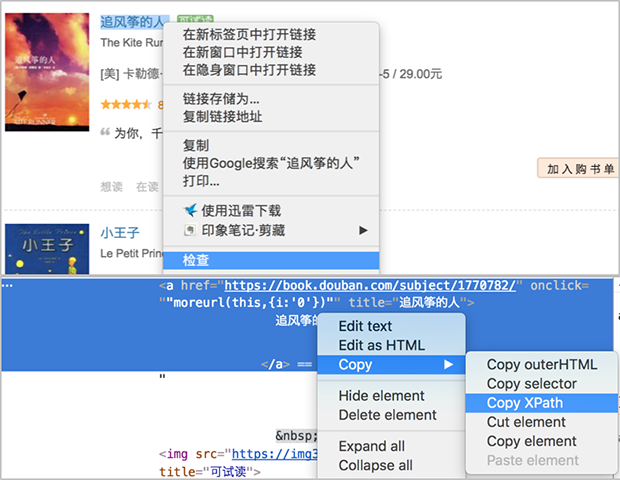
得到第一本书《追风筝的人》的书名xpath如下:
//*[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/div[1]/a
得到xpath,我们就可以按照之前的方法来尝试一下:
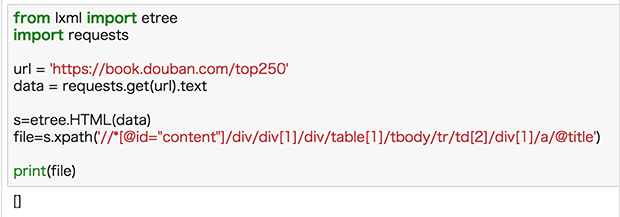
返回的竟然是空值,这就很尴尬了。
这里需要注意,浏览器复制的 xpath 信息并不是完全可靠的,浏览器经常会自己在里面增加多余的 tbody 标签,我们需要手动把这些标签删掉。

修改 xpath 后再来尝试,结果如下:
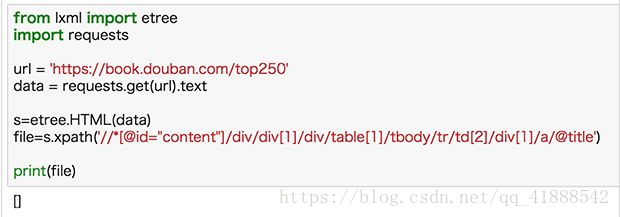
切记:浏览器复制 xpath 不是完全可靠,看到 tbody 标签特别要注意。

分别复制《追风筝的人》、《小王子》、《围城》、《解忧杂货店》的 xpath 信息进行对比:
//*[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/div[1]/a
//*[@id="content"]/div/div[1]/div/table[2]/tbody/tr/td[2]/div[1]/a
//*[@id="content"]/div/div[1]/div/table[3]/tbody/tr/td[2]/div[1]/a
//*[@id="content"]/div/div[1]/div/table[4]/tbody/tr/td[2]/div[1]/a
比较可以发现书名的 xpath 信息仅仅 table 后的序号不一样,并且跟书的序号一致,于是去掉序号(去掉 tbody),我们可以得到通用的 xpath 信息:
//*[@id=“content”]/div/div[1]/div/table/tr/td[2]/div[1]/a
好了,我们试试把这一页全部书名爬下来:
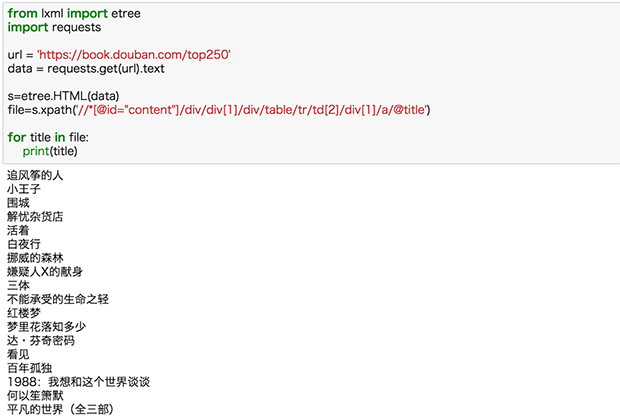
2.爬取多个信息

分别复制《追风筝的人》、《小王子》、《围城》、《解忧杂货店》评分的 xpath 信息进行对比:
//*[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/div[2]/span[2]
//*[@id="content"]/div/div[1]/div/table[2]/tbody/tr/td[2]/div[2]/span[2]
//*[@id="content"]/div/div[1]/div/table[3]/tbody/tr/td[2]/div[2]/span[2]
//*[@id="content"]/div/div[1]/div/table[4]/tbody/tr/td[2]/div[2]/span[2]
相信你已经可以秒写出爬取全部评分的xpath了:
//*[@id=“content”]/div/div[1]/div/table/tr/td[2]/div[2]/span[2]
把评分的xpath放入之前的代码,运行:
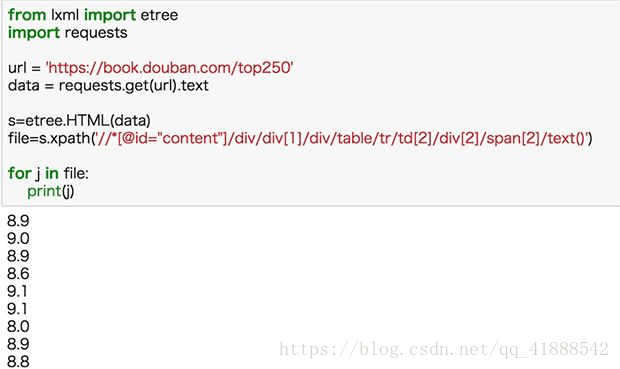
现在我们再把书名和评分同时爬取下来:
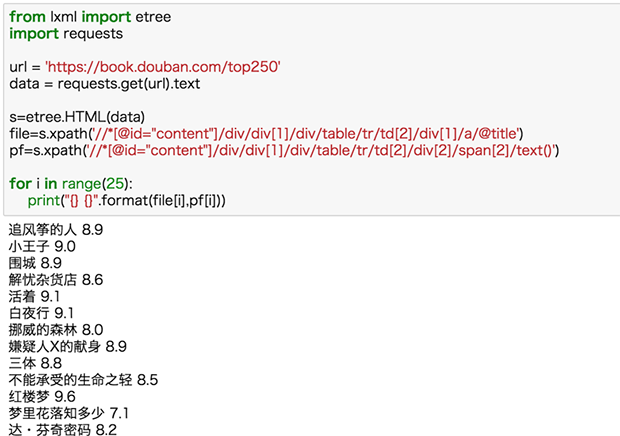
这里我们默认书名和评分爬到的都是完全的、正确的信息,这种默认一般情况没问题,但其实是有缺陷的,如果我们某一项少爬或多爬了信息,那么两种数据的量就不一样了,从而匹配错误。比如下面的例子:
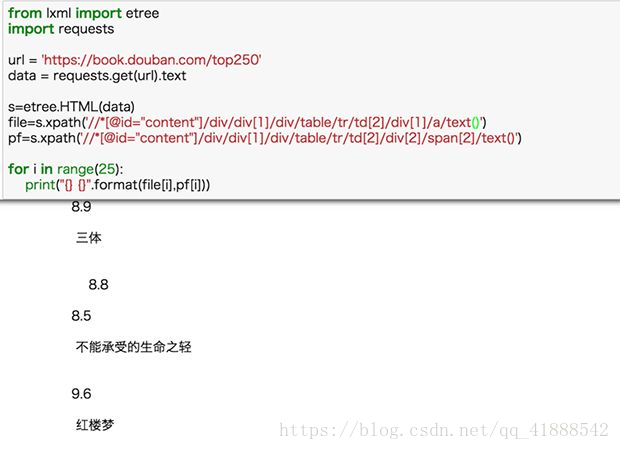
书名xpath 后的@title 改为 text(),获取的文本数量与评分数量不一致,出现匹配错位。
如果我们以每本书为单位,分别取获取对应的信息,那肯定完全匹配。
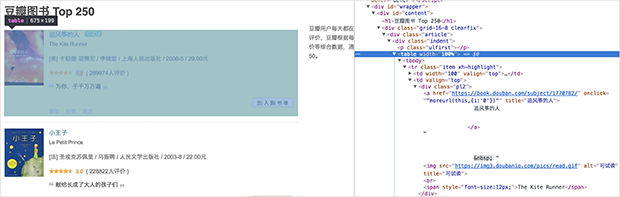
书名的标签肯定在这本书的框架内,于是我们从书名的标签向上找,发现覆盖整本书的标签(左边网页会有代码包含内容的信息),把xpath 信息复制下来:
//*[@id="content"]/div/div[1]/div/table[1]
我们将整本书和书名的xpath进行对比
//*[@id=“content”]/div/div[1]/div/table[1] #整本书
//*[@id=“content”]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a #书名
//*[@id=“content”]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[2] #评分
不难发现,书名和评分 xpath 的前半部分和整本书的 xpath 一致的,
那我们可以通过这样写 xpath 的方式来定位信息:
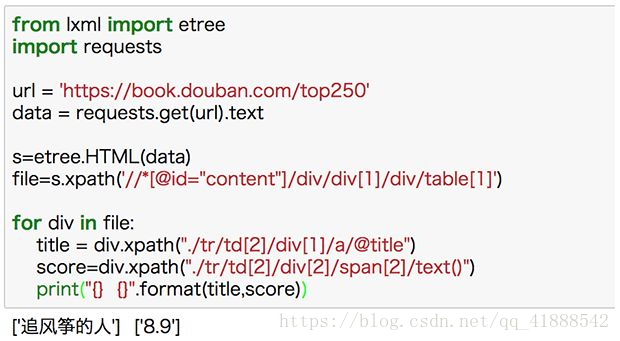
file=s.xpath(“//*[@id=“content”]/div/div[1]/div/table[1]”)
title =div.xpath(“./tr/td[2]/div[1]/a/@title”)
score=div.xpath(“./tr/td[2]/div[2]/span[2]/text()”)
在实际的代码中来看一下:
刚刚我们爬了一本书的信息,那如何爬这个页面所有书呢?很简单啊,把 xpath 中<table>后面定位的序号去掉就ok。
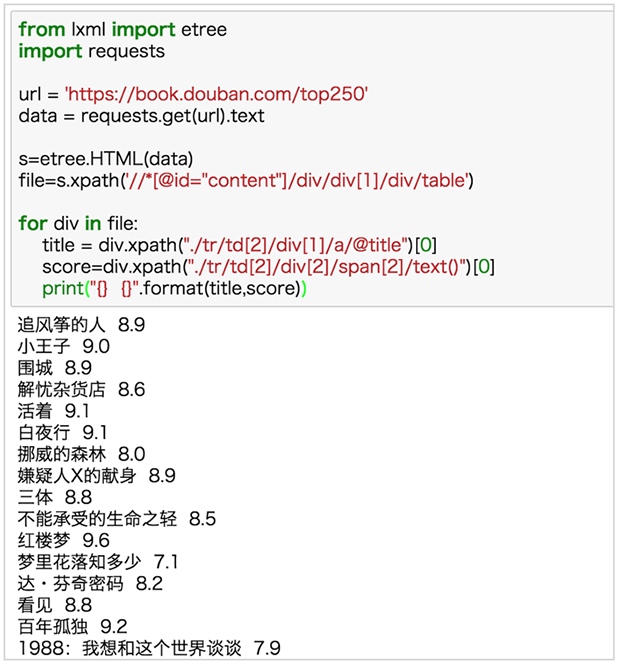
终于看到庐山真面目了,不过,等等~
title = div.xpath("./tr/td[2]/div[1]/a/@title")[0]
score=div.xpath("./tr/td[2]/div[2]/span[2]/text()")[0]
为什么这两行后面多了个 [0] 呢?我们之前爬出来的数据是列表,外面带个方框,看着非常难受,列表只有一个值,对其取第一个值就OK。如果不熟悉列表的知识,可以回去补补。
接下来就是按照这样的方式多爬几个元素啦!

有一个点需要注意的是:
num=div.xpath("./tr/td[2]/div[2]/span[3]/text()")[0].strip("(").strip().strip(")")
这行代码用了几个 strip() 方法,()里面表示要删除的内容,strip(“(”) 表示删除括号, strip() 表示删除空白符。
嗯,已经把一个页面搞定了,接下来需要,把所有页面的信息都爬下来。
3.翻页,爬取所有页面信息
先来看一下翻页后url是如何变化的:
https://book.douban.com/top250?start=0 #第一页
https://book.douban.com/top250?start=25 #第二页
https://book.douban.com/top250?start=50 #第三页
url 变化的规律很简单,只是 start=() 的数字不一样而已,而且是以每页25为单位,递增25,这不正是每页的书籍的数量吗?于是,我们只需要写一个循环就可以了啊。
for a in range(10):
url = 'https://book.douban.com/top250?start={}'.format(a*25)
#总共10个页面,用 a*25 保证以25为单位递增
这里要强调一下 Python range() 函数
基本语法:range(start, stop, step)
start:计数从 start 开始。默认是从 0 开始。例如 range(5) 等价于range(0,5);
end:计数到 end 结束,但不包括 end。例如:range(0,5)是 [0,1,2,3,4] 没有5
step:步长,默认为1。例如:range(0,5) 等价于 range(0,5,1)
>>>range(10) #从 0 开始到 10 (不包含)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> range(1, 11) #从 1 开始到 11 (不包含)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> range(0, 30, 5) #从0到30(不包含),步长为5
[0, 5, 10, 15, 20, 25]
加上循环之后,完整代码如下:
from lxml import etree
import requests
import time
for a in range(10):
url = 'https://book.douban.com/top250?start={}'.format(a*25)
data = requests.get(url).text
s=etree.HTML(data)
file=s.xpath('//*[@id="content"]/div/div[1]/div/table')
time.sleep(3)
for div in file:
title = div.xpath("./tr/td[2]/div[1]/a/@title")[0]
href = div.xpath("./tr/td[2]/div[1]/a/@href")[0]
score=div.xpath("./tr/td[2]/div[2]/span[2]/text()")[0]
num=div.xpath("./tr/td[2]/div[2]/span[3]/text()")[0].strip("(").strip().strip(")").strip()
scrible=div.xpath("./tr/td[2]/p[2]/span/text()")
if len(scrible) > 0:
print("{},{},{},{},{}\n".format(title,href,score,num,scrible[0]))
else:
print("{},{},{},{}\n".format(title,href,score,num))
来运行一下:

请务必要自己练习几遍,你觉得自己看懂了,还是会出错,不信我们赌五毛钱。
Python 的基础语法很重要,没事的时候多去看看:字符串、列表、字典、元组、条件语句、循环语句……
编程最重要的是实战,比如你已经能够爬TOP250的图书了,去试试TOP250电影呢。
好了,这节课就到这里!
 如果你也在学习Python,现在正走在学习Python开发的路上,自学迷茫?没有学习规划和建议,那么我建议你可以加下我的Python学习交流群:663033228 群里有海量学习资料,每天固定分享直播学习。欢迎你的加入,
如果你也在学习Python,现在正走在学习Python开发的路上,自学迷茫?没有学习规划和建议,那么我建议你可以加下我的Python学习交流群:663033228 群里有海量学习资料,每天固定分享直播学习。欢迎你的加入,