昨天临时有事没学习
聚类分析实例:
数据依旧是31个省市自治区2012年城镇居民生活消费的分布规律,根据调查资料做区域消费类型划分。
d3.8=read.table(“clipboard”,header = T)
d3.8
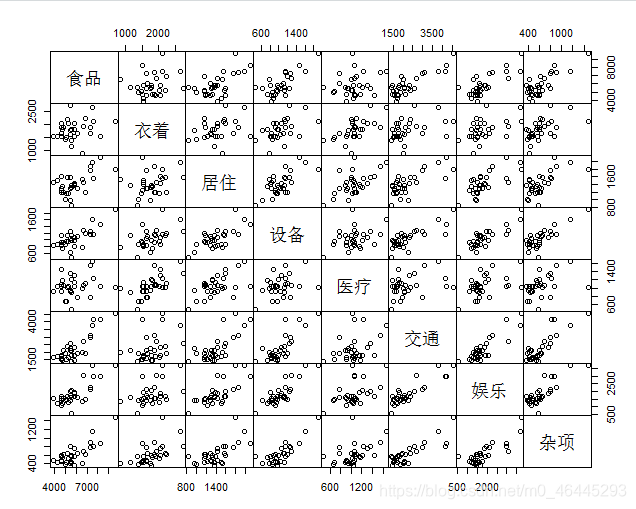
plot(d3.8,gap=0)
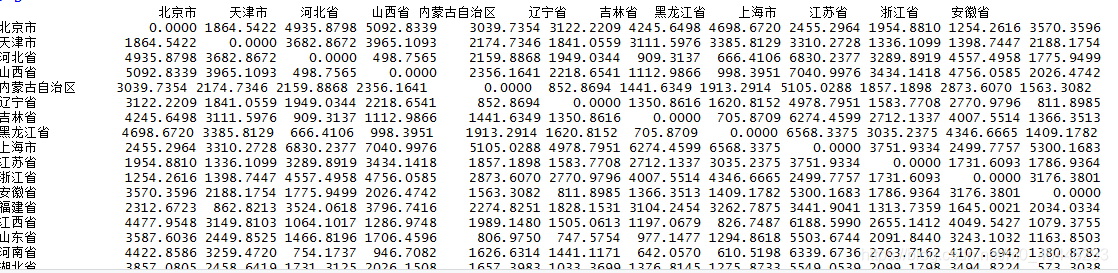
D=dist(d3.8,diag = T,upper = T)
D
初步了解之后,用不同方法聚类
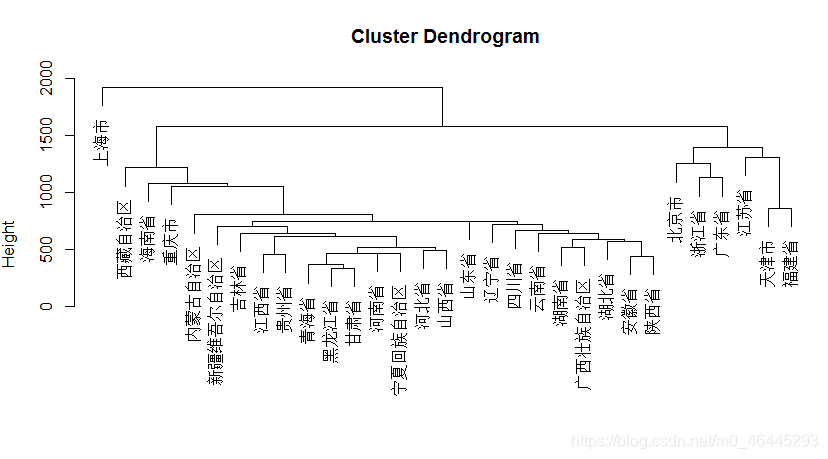
plot(hclust(D,‘single’))最短距离法
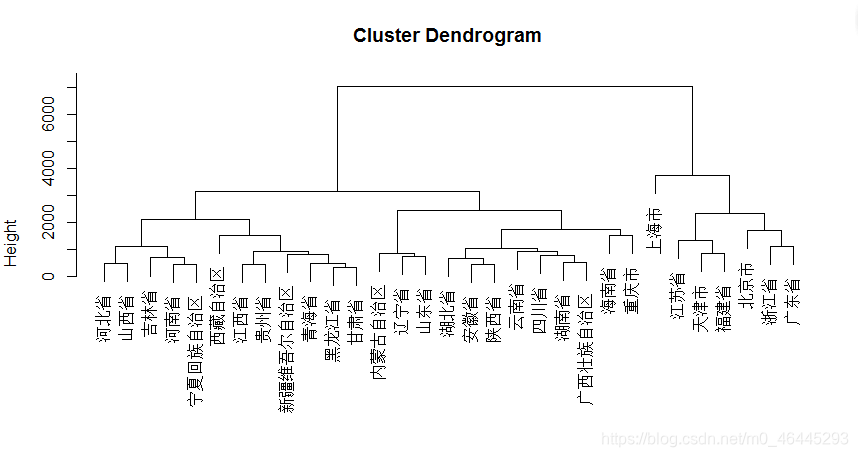
plot(hclust(D,‘complete’))最长距离法
plot(hclust(D,‘median’))中间距离法
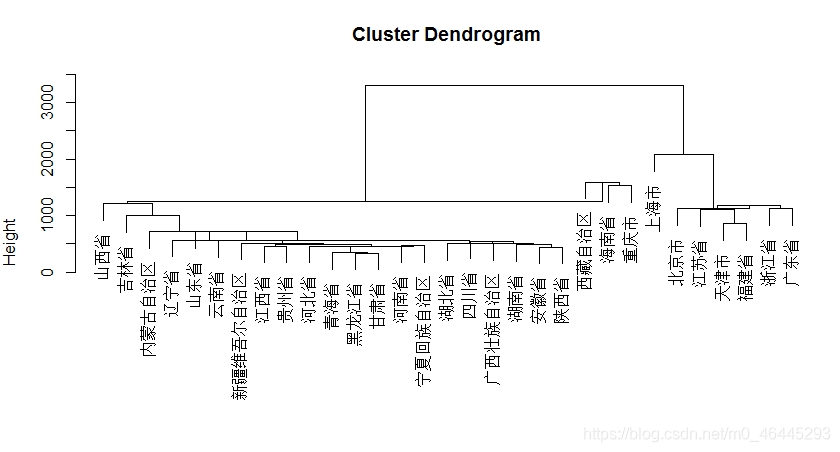
plot(hclust(D,‘average’))类平均法
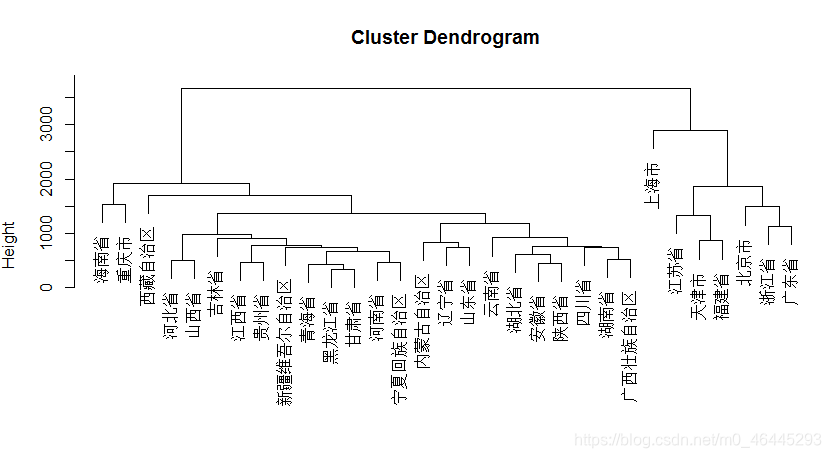
plot(hclust(D,‘centroid’))重心法
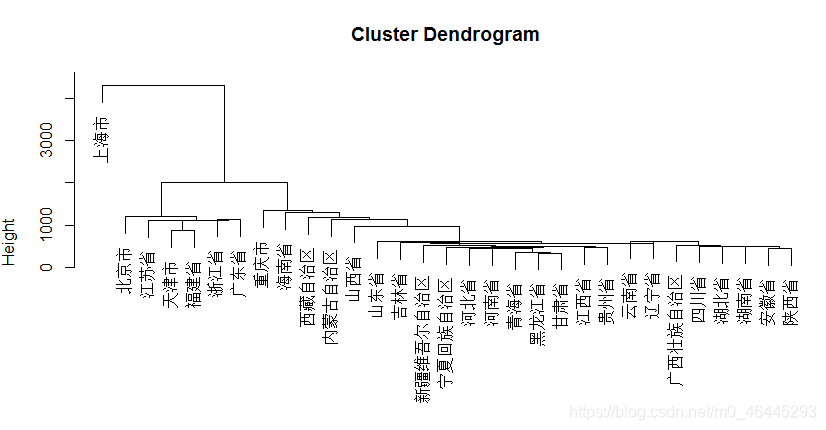
plot(hclust(D,‘ward.D’)) ward.D法
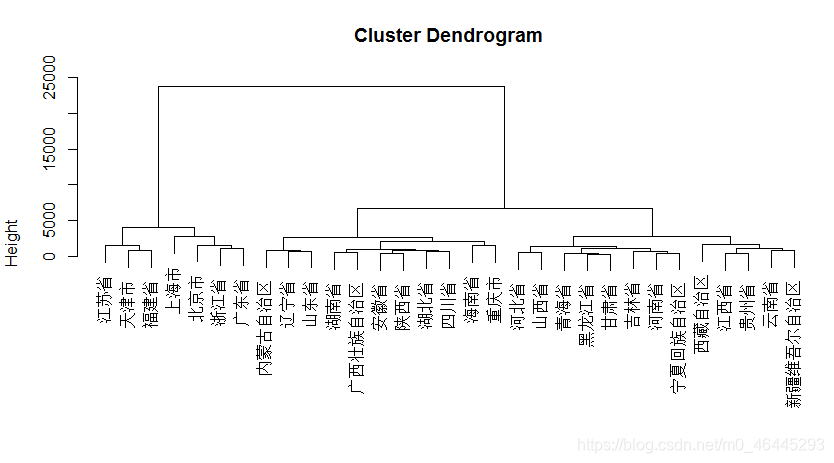
H=hclust(D,‘ward.D2’)
plot(H)
rect.hclust(H,2) 加二类框
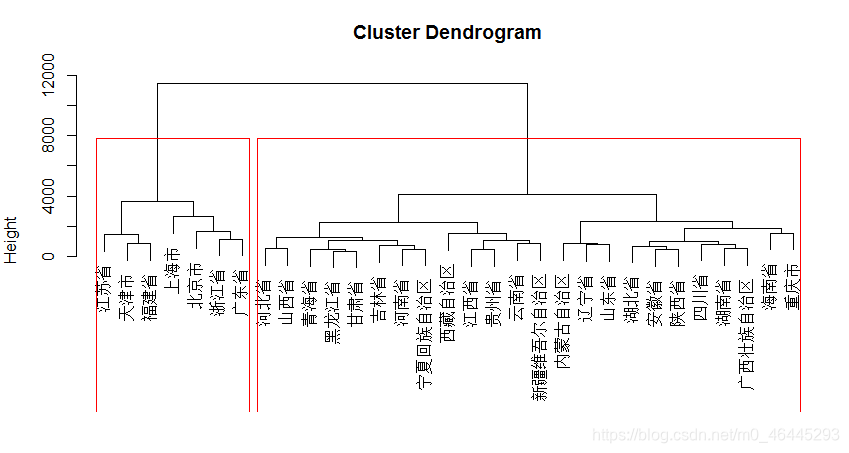
cutree(H,2) 分二类

H=hclust(D,‘ward.D2’)
plot(H)
rect.hclust(H,3) 加三类框
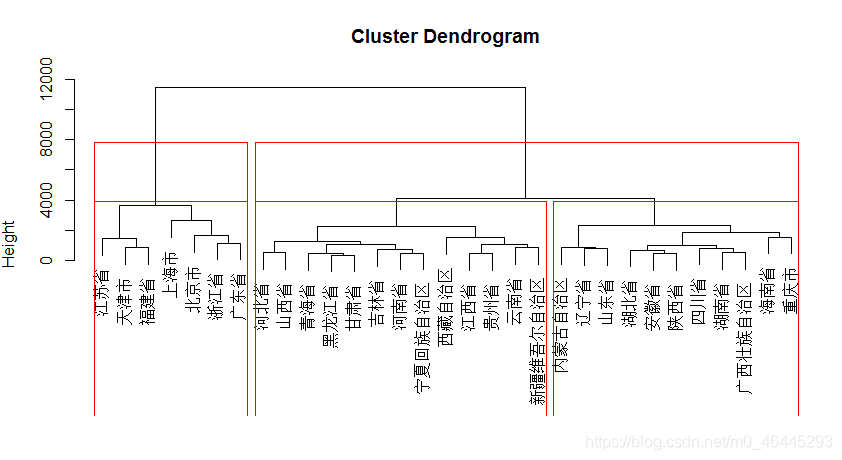
cutree(H,3) 分三类

以此类推,分四类…
新内容:
K均值聚类法
kmeans法是一种快速聚类法,这种算法的基本思想是将每一个样品分配给最近中心(均值)的类中。
原理:kmeans算法以k为参数,把n个对象分为k个类,使类内具有较高的相似度,类间的相似度较低。相似度计算是根据类中对象的均值mean来进行。
kmeans的用法:
kmeans(x,centers,…),x数据矩阵或数据框,centers聚类数或初始聚类中心。eg在下一篇

R语言3.8 聚类分析2

猜你喜欢
转载自blog.csdn.net/m0_46445293/article/details/104717153
今日推荐
周排行