# Load data
data("USArrests")
my_data <- USArrests
# Remove any missing value (i.e, NA values for not available)
my_data <- na.omit(my_data)
# Scale variables
my_data <- scale(my_data)
# View the firt 8 rows
head(my_data, n = 8)
set.seed(123)
km.res <- kmeans(my_data, 8, nstart = 54)
library("factoextra")
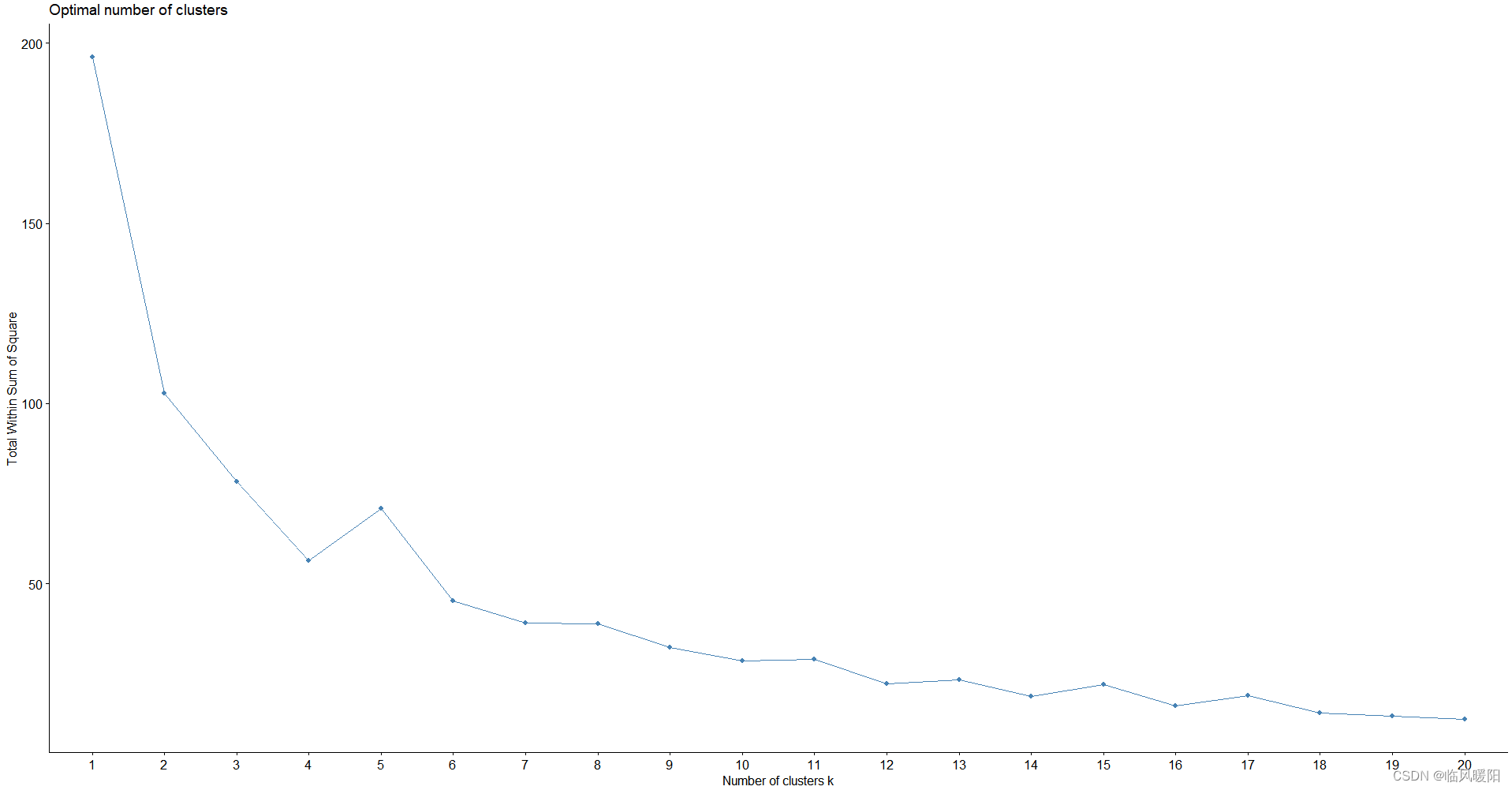
fviz_nbclust(my_data, kmeans,method = "wss" ,k.max = 20,
nboot = 100,
verbose = interactive())
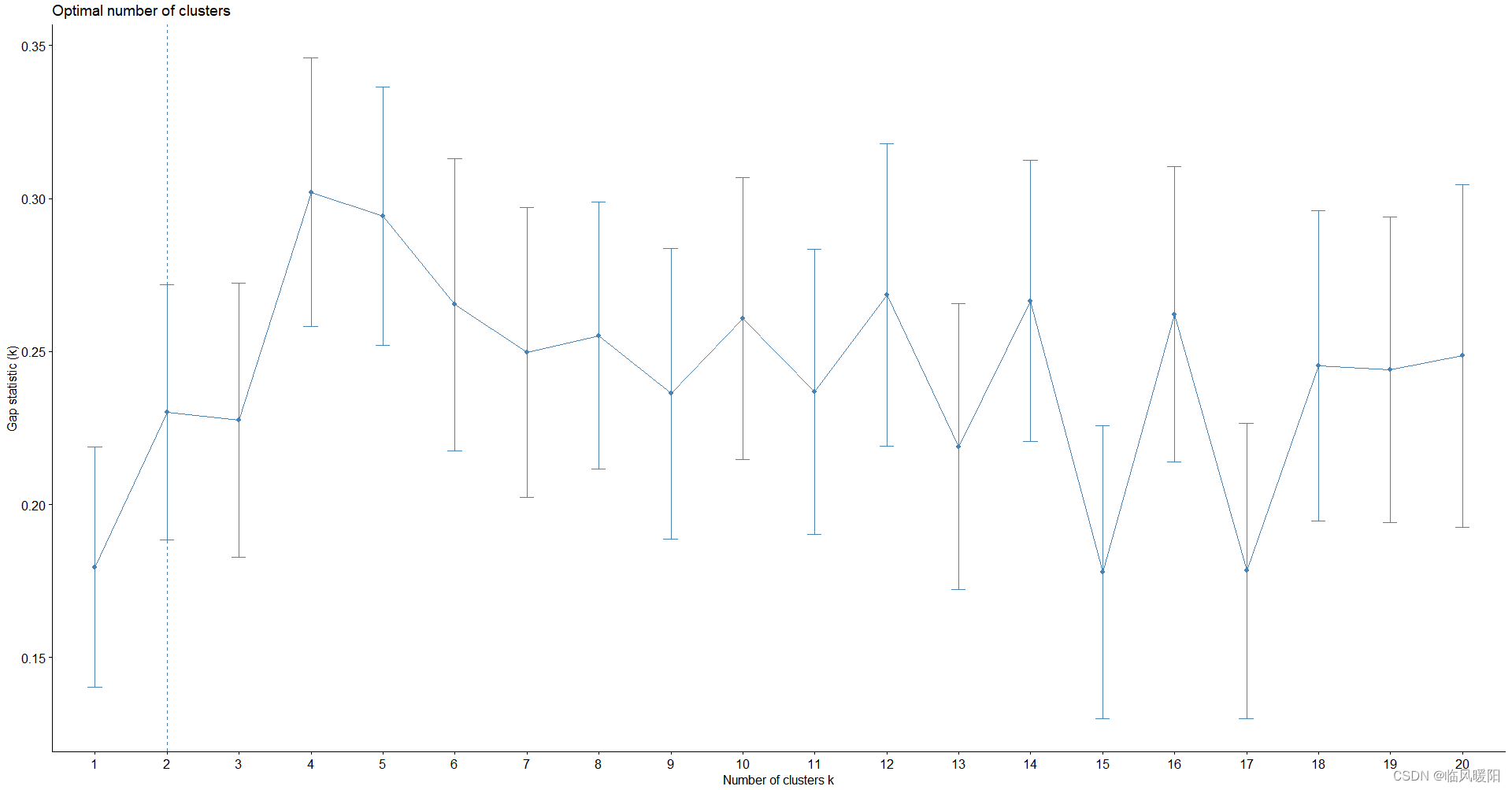
fviz_nbclust(my_data, kmeans,method = "gap_stat" ,k.max = 20,
nboot = 100,
verbose = interactive())
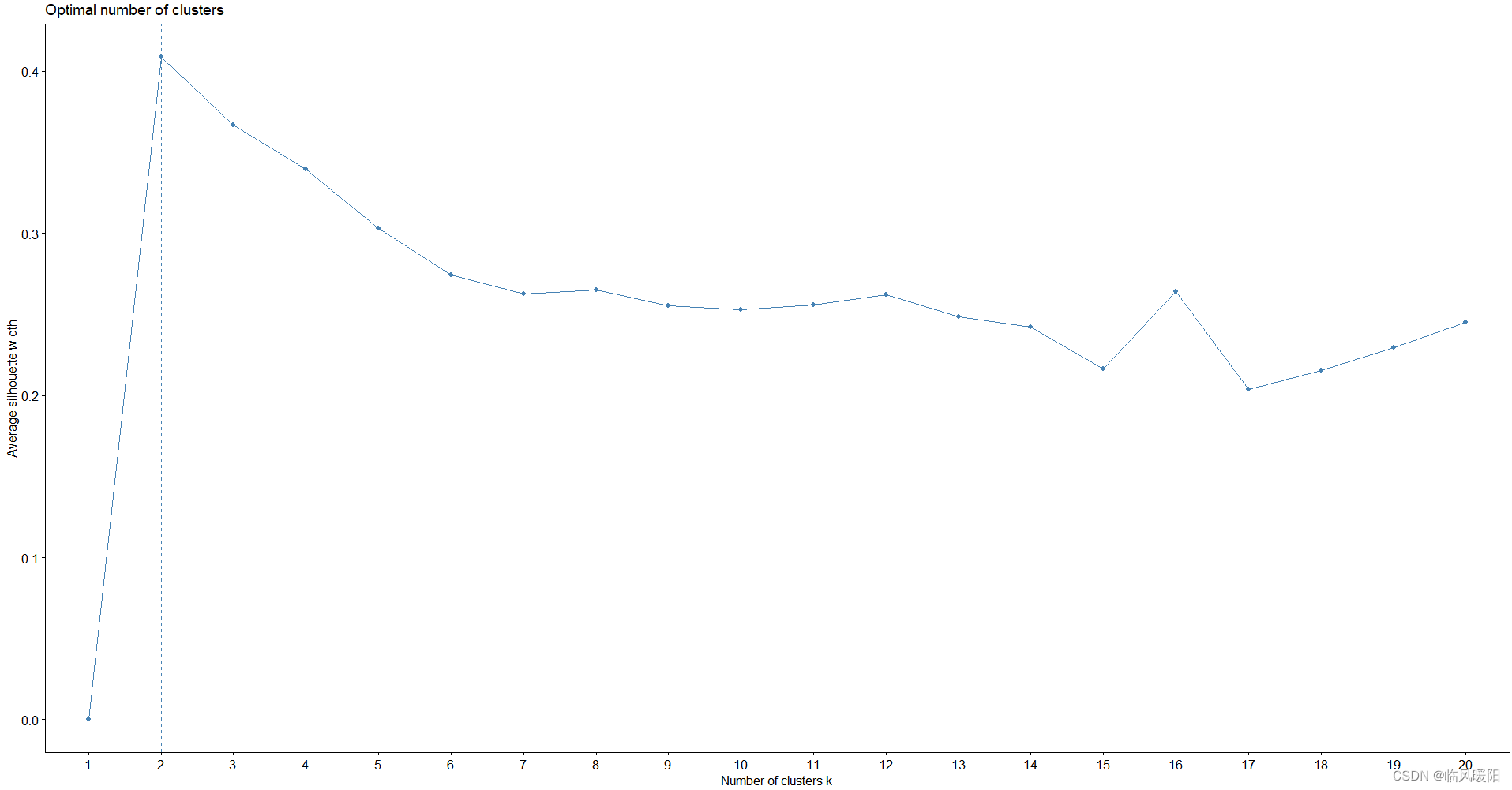
fviz_nbclust(my_data, kmeans,method = "silhouette" ,k.max = 20,
nboot = 100,
verbose = interactive())
参考文献:https://www.rdocumentation.org/packages/factoextra/versions/1.0.7/topics/fviz_nbclust;
https://www.datanovia.com/en/courses/partitional-clustering-in-r-the-essentials/;
开发工具:RStudio和微信Alt+A截屏工具