吵架,英语,考研,论文,烦死了!
聚类分析
聚类分析方法:系统聚类法、快速聚类法
聚类分析的类型:Q型聚类(对样品的聚类)、R型聚类(对变量的聚类)
距离矩阵计算函数dist的用法
dist(X,method=“euclidean”,diag=FALSE,upper=FALSE,p=2)
X数据矩阵,数据框架
method包括"euclidean",“maximum”,“manhattan”,“canberra”,“binary”,“minkowski”,默认为“enclidean”距离
diag是否包含对角线元素,默认为无对角线元素
upper是否需要上三角,默认为下三角矩阵
p Minkowski距离的幂次,默认为p=2(欧式距离)
相关系数矩阵
cor(X)
dist用法:


曼哈顿距离(Manhattan Distance)是种使用在几何度量空间的几何学用语,用以标明两个点在标准坐标系上的绝对轴距总和,想象你在曼哈顿要从一个十字路口开车到另外一个十字路口,驾驶距离是两点间的直线距离吗?显然不是,除非你能穿越大楼。实际驾驶距离就是这个“曼哈顿距离”。而这也是曼哈顿距离名称的来源, 曼哈顿距离也称为城市街区距离(City Block distance)。
系统聚类法的基本思想:
先将个样品分成类,每个样品自成一类,然后每次将具有最小距离的两类合并,合并后重新计算类与类之间的距离,这个过程一直继续到所有的样品归为一类为止,并把这个过程做成一张系统聚类图。
类间距离计算方法:最短,最长,中间距离法,类平均法,重心法,离差平方和法
系统聚类函数hclust
hclust(D,method=“complete”,…)
D相似矩阵,通常为距离矩阵。
method包括“single”最短距离,“complete”最长距离,“average”类平均法,“mcquitty”,“median”,“centroid”重心法,“ward”,默认为“complete”
eg
d3.6=read.table(“clipboard”,header = T)
d3.6
X=data.frame(d3.6$ x1,d3.6$ x2)
X
D=dist(X,diag = T,upper = T)
dist(X)
dist(X,method = “manhattan”)
hc=hclust(D,“single”)最短距离法
hc
names(hc)
data.frame(hc$ merge,hc$ height)
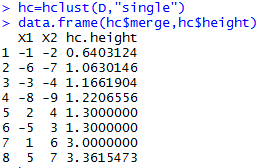
第一个样品和第二个样品距离最小0.6403,第六个样品和第七个样品距离1.063并为一类,带符号表示样品合并,不带符号表示类别合并。
画图看聚类情况:
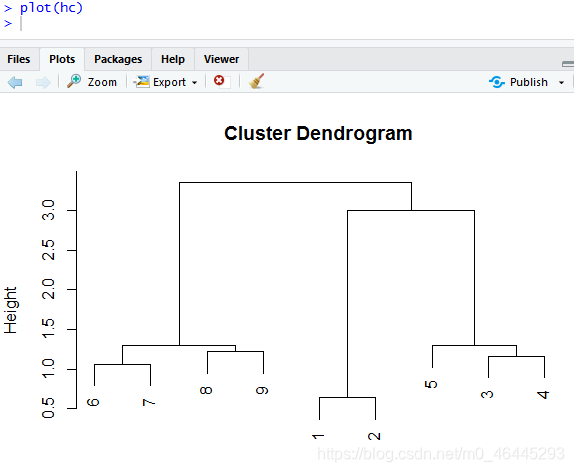
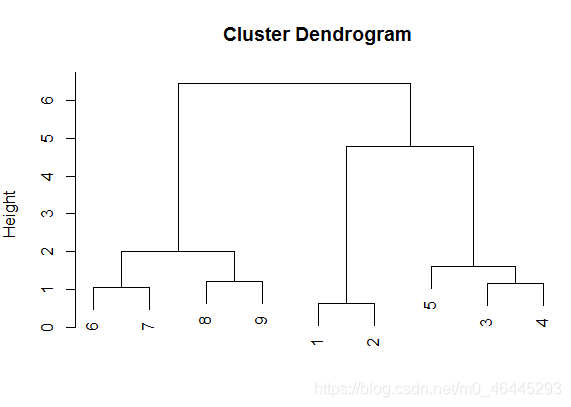
hc<-hclust(D)最长距离法
data.frame(hc m e r g e , h c merge,hc merge,hcheight)
plot(hc)
聚类过程

rect.hclust(hc,3)加3分框
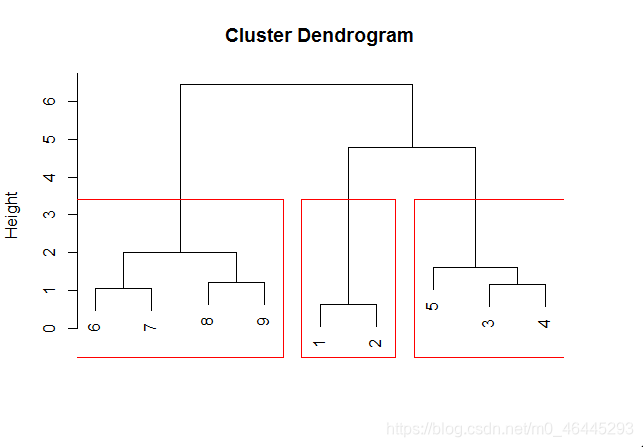
显示分类结果

总结系统聚类R语言步骤:
1.计算距离阵:dist
2.进行系统聚类:hclust
3.绘制聚类图:plot
4.画分类框:rect.hclust
5.确认分类结果:cutree