聚类分析是在没有给定划分类别的情况下,根据数据相似度进行样本分组的一种方法。
与分类模型需要使用有类标记样本构成的训练数据不同,聚类模型可以建立在无类标记的数据上,是一种非监督的学习算法。
聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度将它们划分为若干组,划分的原则是组内距离最小化,而组间距离最大化。
常用聚类分析算法
| 算法名称 | 算法描述 |
| K-Means | K-均值聚类也叫快速聚类法,在最小化误差函数的基础上将数据划分为预定的类数K。 该算法原理简单并便于处理大量数据。 |
| K-中心点 | K-均值算法对异常值是敏感性的,而K-中心点算法不采用簇中对象的平均值作为簇中心,而选用簇中离平均值最近的对象作为簇中心 |
| 系统聚类 | 系统聚类也叫多层次聚类,分类的单位由高到低呈树形结构,且所处的位置越低,其过包含的对象就越少,但这些对象间的共同特征越多。 该聚类方法只适合在小数据量时使用,数据量大时速度回非常慢。 |
聚类分析结果评价
1、purity评价法
计算正确聚类数占总数的比例。
2、RI评价法
R为被聚在一类的两个对象被正确分类了;W指不应该被聚在一类的两个对象被正确分开了;M指不应该被聚在一类的对象被错误地放在了一类;D指不应该分开的对象被错误地分开了。
3、F值评价法
基于RI评价法衍生出的一个方法,
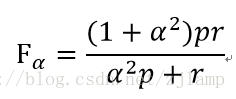
其中,,
实际上,RI方法是把准确率p和召回率r看得同等重要。我们可能需要某一特性多一些,这时候就适合用F值方法。
本文以K-Means算法举例:
根据以下数据将客户分类成不同客户群,并评价这些客户的价值。
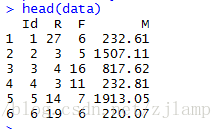
1、建立聚类模型
km = kmeans(data,centers = 3) #k-means聚类分析,分为三类
print(km)输出结果如下:
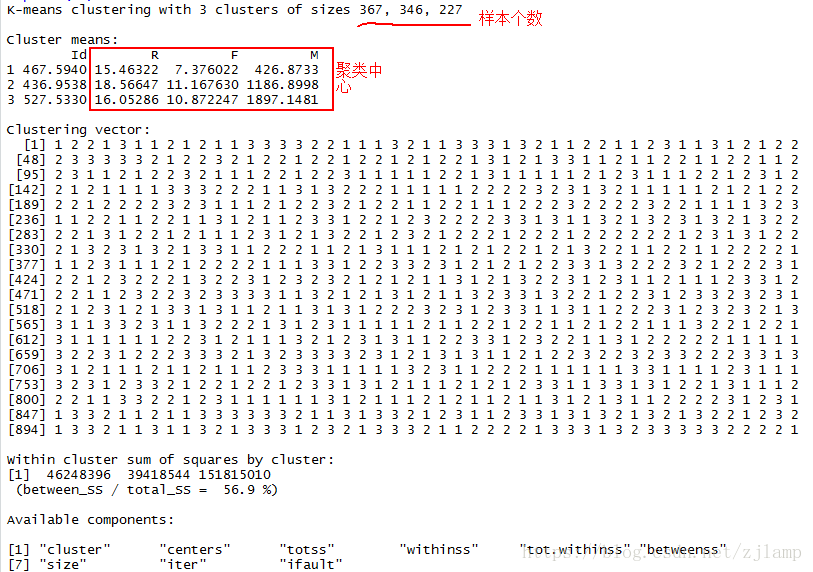
可以看到样本已经被分为三类,每一类的数目分别为367,346,227。
2、将样本根据聚类分析的结果,分为3组:
aaa = data.frame(data,km$cluster)
data1 = data[which(aaa$km.cluster == 1),]
data2 = data[which(aaa$km.cluster == 2),]
data3 = data[which(aaa$km.cluster == 3),] #将样本分组3、作图
par(mfrow = c(3,3))
plot(density(data1[,2]),col = "red",main="R")
plot(density(data1[,3]),col = "red",main="F")
plot(density(data1[,4]),col = "red",main="M")
plot(density(data2[,2]),col = "red",main="R")
plot(density(data2[,3]),col = "red",main="F")
plot(density(data2[,4]),col = "red",main="M")
plot(density(data3[,2]),col = "red",main="R")
plot(density(data3[,3]),col = "red",main="F")
plot(density(data3[,4]),col = "red",main="M")图形如下:
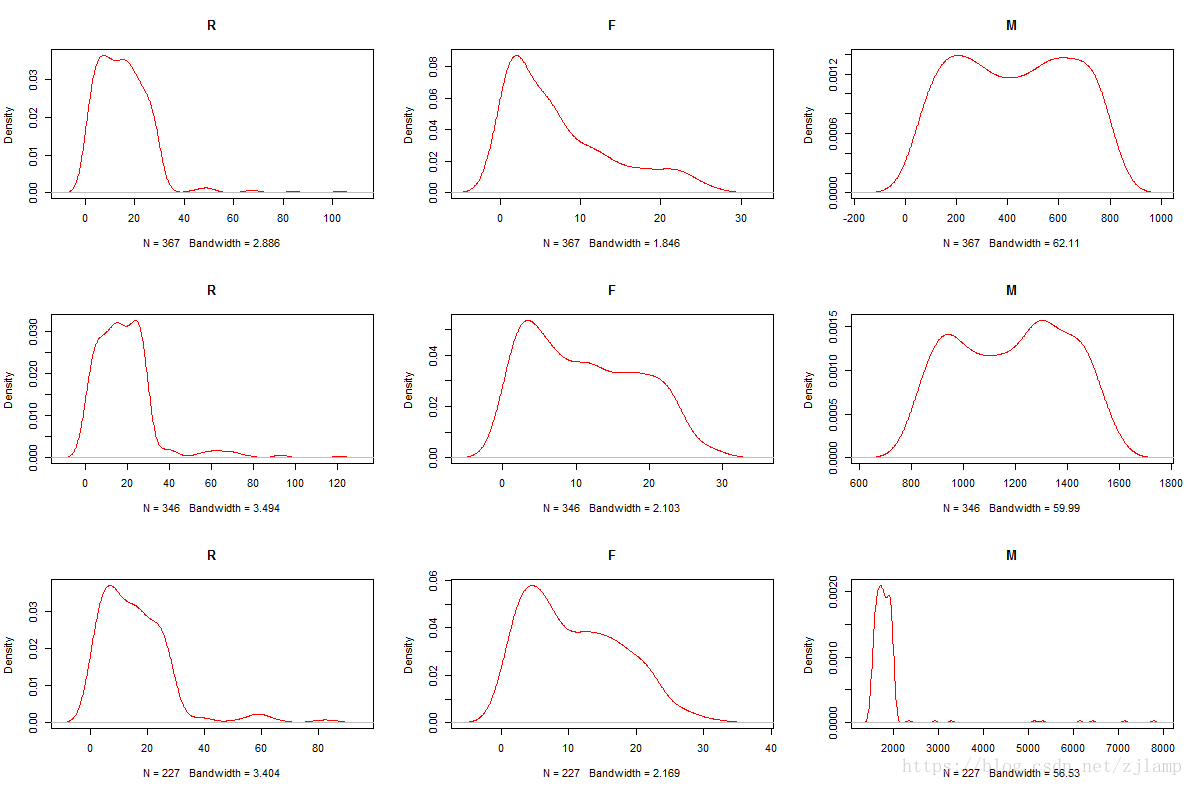
分析图形可知:
分群1特点:R分布在0-20天,F分布在1-10次,M分布在200-600元,属于较低价值的客户群体;
分群2特点:R分布在10-30天,F分布在1-20次,M分布在900-1500元,属于中等水平的客户群体;
分群3特点:R分布在0-20天,F分布在1-15次,M分布在1600-2000元,属于高价值的客户群体。