R语言算法之聚类分析
Kmeans聚类
先以已知的鸢尾花数据集为例(它的类已知,为三类)
加载数据集
data(iris)
# 查看数据集结构
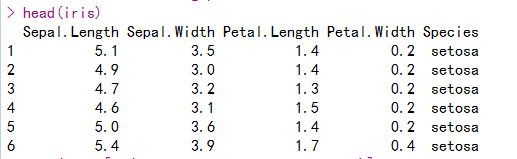
head(iris)
数据处理:
图中可以看出,数据的单位差不了多少,不需要对数据集进行标准化处理,但是在进行聚类分析的时候,我们是通过对其他的标量进行分析判断,所以对于分的类(iris里面的Species在新数据集中不需要)
原数据保留,在新建的数据中“动刀动枪”
iris1 <- iris
iris1$Species <- NULL #删除iris中的Species
library(stats)
set.seed(1234)
模型的建立
kmeans.result <- kmeans(iris1,3) # kmeans(data,k)
kmeans.result$cluster
table(iris$Species,kmeans.result$cluster) #对原先数据的分类与模型预测后的分类做交叉表,
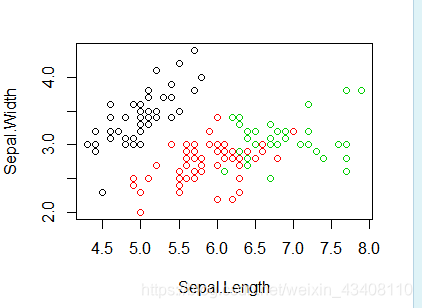
plot(iris1[,c("Sepal.Length","Sepal.Width")],col=kmeans.result$cluster) # 画图,以x轴为Sepal.Length,y轴为Sepal.Width的散点图,其中他们的颜色以Kmeans聚类后的组进行颜色区分,如图所示
模型分类所得的结果,其中主对角线为分正确的组,其他的有数的均为分错了的。可见模型中错分的有16个,总的为150,模型还行。

问题来了,如果对于不知道分多少类的数据呢,k取多少比较合适呢?
有以下几种方法判断
碎石图
# 先构建函数
sstplot <- function(data,nc=15,seed=1234){
sst <- (nrow(data)-1)*apply(data,2,var)
for (i in 2:nc){
sst[i] <- sum(kmeans(data,centers=i)$withinss)
plot(1:nc,sst[1:nc],type="b",xlab="Number df Clusters",ylab="Within group sum of squares"
}
}
投票
library(NbClust)
set.seed(1234)
nc <- NbClust(nutrient[-1],min.nc=2,max.nc=15,method="kmeans")
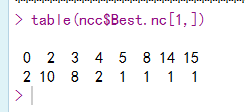
table(nc$Best.nc[1,])
根据投票的结果,2,最多,3次之。所以分为2类效果最好。三类也不错
K中心聚类法:不易受极端值影响
# K中心聚类点:不易受极端值影响
library(cluster)
set.seed(1234)
fit.pam <- pam(wine[-1],k=3,stand=T)#stand=T:标准化,即使用这个模型,你可以减少一些麻烦
fit.pam$medoids # 中心点
clusplot(fit.pam)
ct.pam <- table(wine$Type,fit.pam$clustering)
ct.pam
install.packages("flexclust")
randIndex(ct.pam) # 这个指标取值在-1~1.越接近一越好,越接近-1越不好。
这个交叉表出来,以及指标显示为0.6994957,以中心聚类的效果不是很好。
层次聚类法
data("nutrient",package="flexclust") # 数据导入
head(nutrient) #查看数据前几行
d <- dist(nutrient)
head(d) # 数据显示是一行一行的,我们看着不舒服,做转换
as.matrix(d)[1:4,1:4]
# 数据中心化处理
nutrient.scale <- scale(nutrient)
d <- dist(nutrient.scale)
fit.average <- hclust(d,method="average")
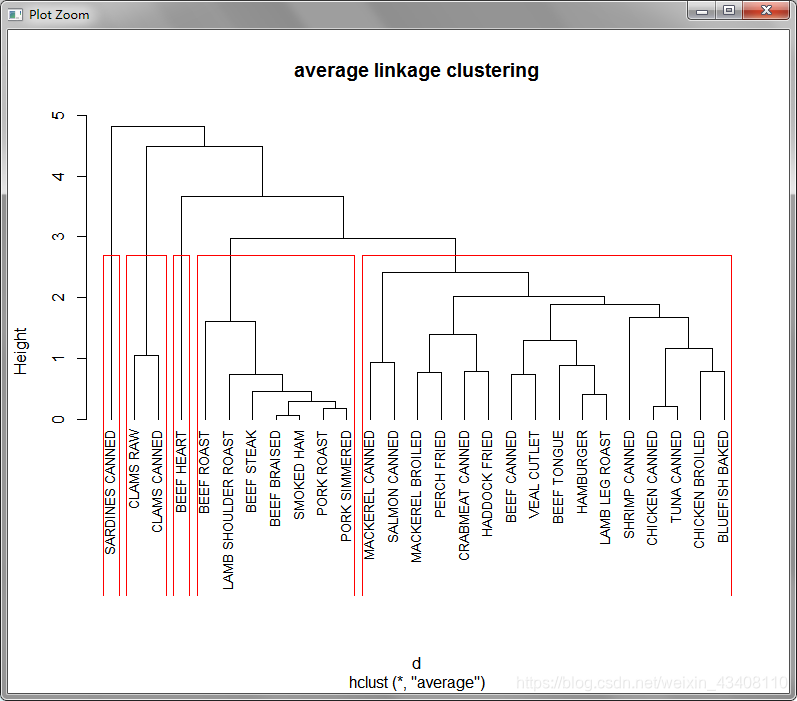
plot(fit.average,hang=1,cex=0.8,main="average linkage clustering")

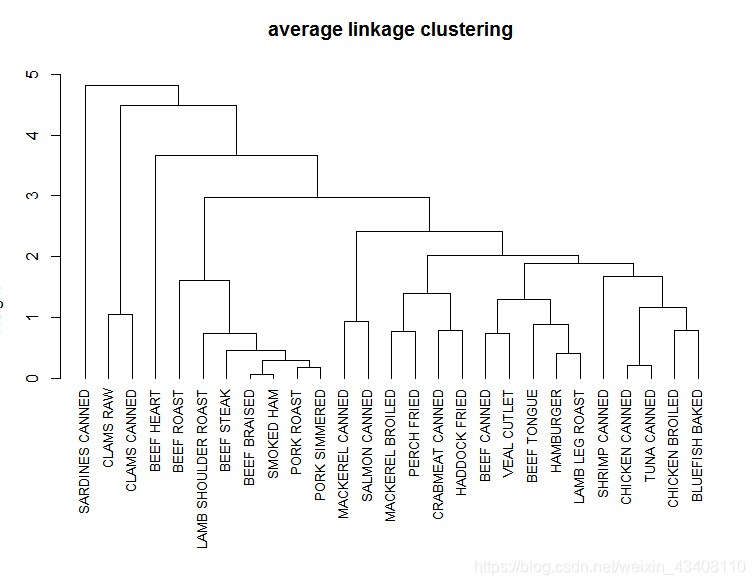
谱系图已经出来了,那我们应该划分为几类呢?
对了,用之前学习过的方法,投票
nc2 <- NbClust(nutrient.scale,max.nc=15,min.nc=2,method="average",distance="euclidean")
table(nc2$Best.nc[1,])
# 结果得知k取2,3,5,15都是得票最高的
# 由于上图层次聚类优点繁多,我们可以进行切割处理(剪切树)
fit.average1<-cutree(nc2,k=5)
rect.hclust(fit.average,k=5)