数据分析学习总结笔记02:聚类分析及其R语言实现
1. 聚类分析概述
1.1 聚类分析简介
聚类分析(cluster analysis)是一组将研究对象分为相对同质的群组的统计分析技术。聚类分析也称群分析或点群分析,它是研究多要素事物分类问题的数量方法。在科学研究、社会调查或日常生活中,通过观察个体的特征,将群体中的个体归为不同的族群/簇(Cluster)1。
1.2 聚类分析原理
根据样本自身的属性,用数学方法按照某种相似性或差异性指标,定量地确定样本之间的亲疏关系,并按这种亲疏关系程度对样本进行聚类。
1.3 聚类&分类
- 分类分析中,个体的类别标签固有存在,只是对于新观测个体暂时未知,分类过程旨在根据其特征预测类别,后续可知是否预测准确。属于有监督学习(supervised learning)。例如,银行征信分类。
- 聚类分类中,类别的个数及个体标签本身并不存在,只是根据个体特征的相似性形成“合理”的聚集,并无“正确答案”参考。属于无监督学习(unsupervised learning),较为主观。例如,精准营销。
1.4 如何刻画相似度?
合理的聚类方式应当使得同一族群内的观测尽可能相似,但不同的族群之间有明显区分。
刻画相似度的方式——距离,距离越小越相似月可能聚为同一类。主要有以下几种常见的方式度量:
- 欧式距离(Euclidean distance):
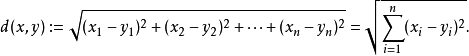
- 马氏距离(Mahalanobis distance)
- Minkowski 测度
- Canberra 测度
2. 聚类分析的方法
传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等。采用K-均值、k-中心点等算法的聚类分析工具已被加入到许多常用的统计分析软件包中,如SPSS、SAS等。
2.1 层次聚类
2.1.1 层次聚类步骤
(1)建立n个初始族群,每个族群中只有一个个体;
(2)计算n个族群间的距离矩阵;
(3)合并距离最小的两个族群,计算新族群间的距离矩阵;
(4)如果组别数为1,转步骤(5),否则转步骤(3);
(5)绘制系统树图;
(6)选择族群个数。
2.1.2 简介
考虑所有的群组组合几乎无法实现,所以一种最常用的聚类方法为层次聚类/系统聚类(hierarchical cluster)。主要有两种方式:
- 凝聚法(Agglomerative clustering)由单个个体开始,逐步合并最“相似”的个体,直到所有个体都合并为一个族群。再进一步考虑该族群和其他族群的距离。
- 分离法(Divisive clustering)即为凝聚法的相反方向。
层次聚类过程的结果可以利用图表展示为系统树图(Dendrogram),用来展示层次聚类的每一个步骤及其结果,包括合并族群带来的距离的变化。
2.1.3 层次聚类的类型
本节主要介绍凝聚法。凝聚法每一步需要合并“距离最小的两个族群”,不同族群间距离的定义方法决定了不同的聚类结果。
(1)连接法
- 简单连接法/最近邻法:定义族群间的距离为两族群中相隔最近的两个个体间的距离。
- 完全连接法/最远邻法:定义族群间的距离为两组别中相隔最远个体之间的距离。
- 平均连接法:定义族群间的距离为nA个A集合点和nB个B集合点产生的所有nA nB个距离的平均值。
- 质心连接法:定义族群间的距离为两族群各自的质心,即样本均值向量,之间的欧式距离。每次合并都会重新计算新族群的质心,该方法可能存在倒置现象,即,如果两个族群合并之后,下一步合并时的距离反而减小,这种情况称为倒置,在系统树图中表现为交叉现象。由于在简单连接、完全连接和平均连接中距离的度量是单调的,倒置在这些层次聚类方法中不可能发生。倒置可以通过基于中点的质心法进行解决。
(2)Ward法
Ward法/方差平方和增量法,由合并前后的族群内方差平方和的差异定义距离:
I(AB) = SSE(AB) - ( SSE(A) + SSE(B) )
2.1.4 层次聚类族群个数的选择
可以通过树图的两个族群间的距离进行划分,选择较大距离的点进行划分。同时,需要结合对数据的经验和理解,看聚成多少类更加符合实际情况,或者更易于理解。总结为以下思路:
- 根据经验或业务理解预先设定;
- 数据驱动:从系统树图中于给定距离水平下“切分”树图得到对应族群。通常寻找合并组别时较大的距离变化的节点。
2.1.5 层次聚类R语言实践
简单连接聚类/完全连接聚类/平均连接聚类:
library(EXAMPLE)
measure
dm <- dist(measure[,c(“x”,“y”,“z”)])
round(dm,2)
layout(matrix(1:3,nr=1),height=c(2,1))
plot(cs<-hclust(dm,method=“single/complete/average”,main=“single”)
abline(h=3.8, col=“lightgrey”)
为了显示聚类效果,可以画出带族标签的主成分散点图。
plot(body_pc scores[,1:2], labels=lab, cex=1)
简单连接法存在“链式”问题,倾向于将新的个体归入已存在的族群,而不是创建新的族群。
完全连接聚类和平均连接聚类的结果相似。
2.2 非层次聚类——K-Means
层次聚类的缺陷:一旦个体被分为一个族群,它将不可再被归入另一个族群,只可能达到局部最优而非全局最优。
非层次聚类:分割法。分割法中最常用的方法为K-means法。
2.2.1 K-means聚类简介
K-均值法试图寻找k个族群的划分方式,使得划分后的族群内方差(Within group sum of square, WGSS)最小。
2.2.2 K-means聚类步骤
(1)选定k个“种子”(cluster seeds)作为初始种群代表;
(2)将每个个体归入距离其最近的种子所在的族群;
(3)归类完成后,将新产生的族群的质心定为新的种子
(4)重复步骤(2)和(3),直到将所有点归类。
2.2.3 k的选取
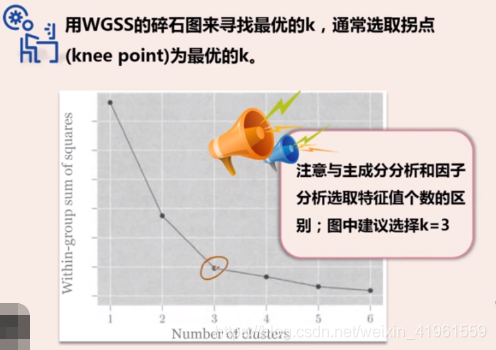
需要选择一个使得WGSS足够小(但不是最小)的k值。
用WGSS的碎石图来寻找最优的k,通常选取拐点为量优的k。
2.2.3 选择初始种子
- 在相互间隔超过某指定最小距离的前提下,随机选取k个个体。
- 选择数据集前k个相互间隔超过某指定最小距离的个体。
- 选择k个相互距离最远的个体。
- 选择k个等距网格点,可能不是数据集的点。
k-均值法对初始种子的选择比较敏感,可尝试在不同的种子选择下多次进行聚类。
如果不同的初始种子造成了聚类结果很大的不同,或是收敛的速度极其缓慢,也许说明数据可能原本并不存在天然的族群。
k-均值法也可以作为层次聚类的一种改进。首先用层次聚类法聚类,以各族群的质心作为k-均值法的初始种子。
2.2.4 K-means聚类R语言实践
pottery_dist
levelplot
绘制WGSS碎石图决定聚类的组别数:
wgss<- rep(0,6)
for (i in 1:6) {wgss[i] <-sum(kmeans(pots,centers =i) KaTeX parse error: Expected 'EOF', got '}' at position 10: withinss)}̲ plot(1:6,wgss,…scores[,1:2],pch =kmeans_3$cluster)
2.3 DBSCAN——基于密度的聚类算法
2.3.1 DBSCAN简介2
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
2.3.2 DBSCAN相关定义
- Ε邻域:给定对象半径为Ε内的区域称为该对象的Ε邻域;
- 核心对象:如果给定对象Ε邻域内的样本点数大于等于MinPts,则称该对象为核心对象;
- 直接密度可达:对于样本集合D,如果样本点q在p的Ε邻域内,并且p为核心对象,那么对象q从对象p直接密度可达。
- 密度可达:对于样本集合D,给定一串样本点p1,p2….pn,p= p1,q= pn,假如对象pi从pi-1直接密度可达,那么对象q从对象p密度可达。
- 密度相连:存在样本集合D中的一点o,如果对象o到对象p和对象q都是密度可达的,那么p和q密度相联。
可以发现,密度可达是直接密度可达的传递闭包,并且这种关系是非对称的。密度相连是对称关系。DBSCAN目的是找到密度相连对象的最大集合。
Eg: 假设半径Ε=3,MinPts=3,点p的E邻域中有点{m,p,p1,p2,o}, 点m的E邻域中有点{m,q,p,m1,m2},点q的E邻域中有点{q,m},点o的E邻域中有点{o,p,s},点s的E邻域中有点{o,s,s1}.
那么核心对象有p,m,o,s(q不是核心对象,因为它对应的E邻域中点数量等于2,小于MinPts=3);
点m从点p直接密度可达,因为m在p的E邻域内,并且p为核心对象;
点q从点p密度可达,因为点q从点m直接密度可达,并且点m从点p直接密度可达;
点q到点s密度相连,因为点q从点p密度可达,并且s从点p密度可达。
2.3.3 DBSCAN聚类步骤
DBScan需要二个参数: 扫描半径 (eps)和最小包含点数(minPts)。 任选一个未被访问(unvisited)的点开始,找出与其距离在eps之内(包括eps)的所有附近点。
如果 附近点的数量 ≥ minPts,则当前点与其附近点形成一个簇,并且出发点被标记为已访问(visited)。 然后递归,以相同的方法处理该簇内所有未被标记为已访问(visited)的点,从而对簇进行扩展。
如果 附近点的数量 < minPts,则该点暂时被标记作为噪声点。
如果簇充分地被扩展,即簇内的所有点被标记为已访问,然后用同样的算法去处理未被访问的点。
具体算法描述如下:
(1)检测数据库中尚未检查过的对象p,如果p未被处理(归为某个簇或者标记为噪声),则检查其邻域,若包含的对象数不小于minPts,建立新簇C,将其中的所有点加入候选集N;
(2)对候选集N 中所有尚未被处理的对象q,检查其邻域,若至少包含minPts个对象,则将这些对象加入N;如果q 未归入任何一个簇,则将q 加入C;
(3)重复步骤2),继续检查N 中未处理的对象,当前候选集N为空;
(4)重复步骤1)~3),直到所有对象都归入了某个簇或标记为噪声。
3. 聚类分析的应用
3.1 市场营销——精准营销
在市场营销中,基于消费者的历史交易信息、消费者背景等对消费者进行划分,从而对不同类型的消费者实施不同的营销策略。
3.2 金融领域——投资组合归类
在金融领域,为获得较为平衡的投资组合,需要首先基于一系列金融表现变量(如回报率、波动率、市场资本等)对投资产品(如股票、基金等)进行归类。
3.3 生物领域
聚类分析被用来对动植物分类和对基因进行分类,获取对种群固有结构的认识。
3.4 保险领域
聚类分析通过一个高的平均消费来鉴定汽车保险单持有者的分组,同时可根据住宅类型、价值、地理位置来鉴定一个城市的房产分组。
相关笔记:
- Python相关实用技巧01:安装Python库超实用方法,轻松告别失败!
- Python相关实用技巧02:Python2和Python3的区别
- Python相关实用技巧03:14个对数据科学最有用的Python库
- Python相关实用技巧04:网络爬虫之Scrapy框架及案例分析
- Python相关实用技巧05:yield关键字的使用
- Scrapy爬虫小技巧01:轻松获取cookies
- Scrapy爬虫小技巧02:HTTP status code is not handled or not allowed的解决方法
- 数据分析学习总结笔记01:情感分析
- 数据分析学习总结笔记02:聚类分析及其R语言实现
- 数据分析学习总结笔记03:数据降维经典方法
- 数据分析学习总结笔记04:异常值处理
- 数据分析学习总结笔记05:缺失值分析及处理
- 数据分析学习总结笔记06:T检验的原理和步骤
- 数据分析学习总结笔记07:方差分析
- 数据分析学习总结笔记07:回归分析概述
- 数据分析学习总结笔记08:数据分类典型方法及其R语言实现
- 数据分析学习总结笔记09:文本分析
- 数据分析学习总结笔记10:网络分析
本文主要根据个人学习(多元统计分析MOOC),并搜集部分网络上的优质资源总结而成,如有不足之处敬请谅解,欢迎批评指正、交流学习!
