版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Cocaine_bai/article/details/80566885
《数据分析实战》–用R做聚类分析
本文参考的是《数据分析实战》的第八章。
背景:针对某公司的产品,现目前需要服务好已有的用户,针对不同的用户群体设计并推广不同的营销策略。
现状:目标用户不明确。
预期:明确目标用户群。
读取数据
读取Dau数据:
> dau <- read.csv('dau.csv',header = T,stringsAsFactors = F)
> head(dau)
log_date app_name user_id
1 2013-05-01 game-01 608801
2 2013-05-01 game-01 712453
3 2013-05-01 game-01 776853
4 2013-05-01 game-01 823486
5 2013-05-01 game-01 113600
6 2013-05-01 game-01 452478读取Dpu数据:
> dpu <- read.csv('dpu.csv',header = T,stringsAsFactors = F)
> head(dpu)
log_date app_name user_id payment
1 2013-05-01 game-01 804005 571
2 2013-05-01 game-01 793537 81
3 2013-05-01 game-01 317717 81
4 2013-05-01 game-01 317717 81
5 2013-05-01 game-01 426525 324
6 2013-05-01 game-01 540544 243读取用户行为数据:
> user.action <- read.csv('action.csv',header = T,stringsAsFactors = F)
> head(user.action)
log_date app_name user_id A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 ... A54
1 2013-10-31 game-01 654133 0 0 0 0 0 0 0 0.00 0 0 0 0 ... 46
2 2013-10-31 game-01 425530 0 0 0 0 10 1 233 58.25 288 230 19 2 ... 71
3 2013-10-31 game-01 709596 0 0 0 0 0 0 0 0.00 0 0 0 0 ... 2
4 2013-10-31 game-01 525047 0 2 0 0 9 0 0 0.00 177 160 0 0 ... 109
5 2013-10-31 game-01 796908 0 0 0 0 0 0 0 0.00 5 30 0 0 ... 64
6 2013-10-31 game-01 776120 0 0 0 0 9 0 0 0.00 325 195 38 8 ... 312其中列A1 ~ A54 表示各种行为的编码,这些行为的编码和行为日志名称是通过另外一份数据表来管理的。
数据处理
1.将Dau和Dpu合并:
# 合并消费额数据
> dau2 <- merge(dau, dpu[, c("log_date", "user_id", "payment"), ],
by = c("log_date", "user_id"), all.x = T)
# 添加消费额标志位
> dau2$is.payment <- ifelse(is.na(dau2$payment), 0, 1)
# 将无消费记录的消费额设为0
> dau2$payment <- ifelse(is.na(dau2$payment), 0, dau2$payment)
> head(dau2)
log_date user_id app_name payment is.payment
1 2013-05-01 1141 game-01 0 0
2 2013-05-01 1689 game-01 0 0
3 2013-05-01 2218 game-01 0 0
4 2013-05-01 3814 game-01 0 0
5 2013-05-01 3816 game-01 0 0
6 2013-05-01 4602 game-01 0 02.按月统计:
# 增加一列表示月份
> dau2$log_month <- substr(dau2$log_date,1,7)
# 按月统计
> mau <- ddply(dau2,
+ .(log_month,user_id),
+ summarize,
+ payment = sum(payment),
+ access_days=length(log_date))
> head(mau)
log_month user_id payment access_days
1 2013-05 65 0 1
2 2013-05 115 0 1
3 2013-05 194 0 1
4 2013-05 426 0 4
5 2013-05 539 0 1
6 2013-05 654 0 1数据分析
现状我们通过聚类来对数据进行分析:
1.确定类的个数:
可以使用k-means 方法,将排行榜得分作为变量,把用户分为3 个类。
k-means 方法可以通过kmeans 函数来执行,但该方法的缺点是结果不稳定。ykmeans 程序包中的ykmeans 函数,在内部将kmeans 函数执行了100 次,因此能够获得稳定的结果。
> library(ykmeans)
> library(ggplot2)
> library(scales)
# A47为排行榜得分
> user.action2 <- ykmeans(user.action,"A47", "A47", 3)
# 每个类的人数
> table(user.action2$cluster)
1 2 3
2096 479 78 对确定好的类进行画图:
# 排行榜得分的分布
> ggplot(arrange(user.action2,desc(A47)),
+ aes(x=1:length(user_id),y=A47,
+ col=as.factor(cluster),
+ shape=as.factor(cluster)))+
+ geom_line()+
+ xlab("user")+
+ ylab("Ranking point")+
+ scale_y_continuous(labels = comma)+
+ ggtitle("Ranking point")+
+ theme(legend.position = "none")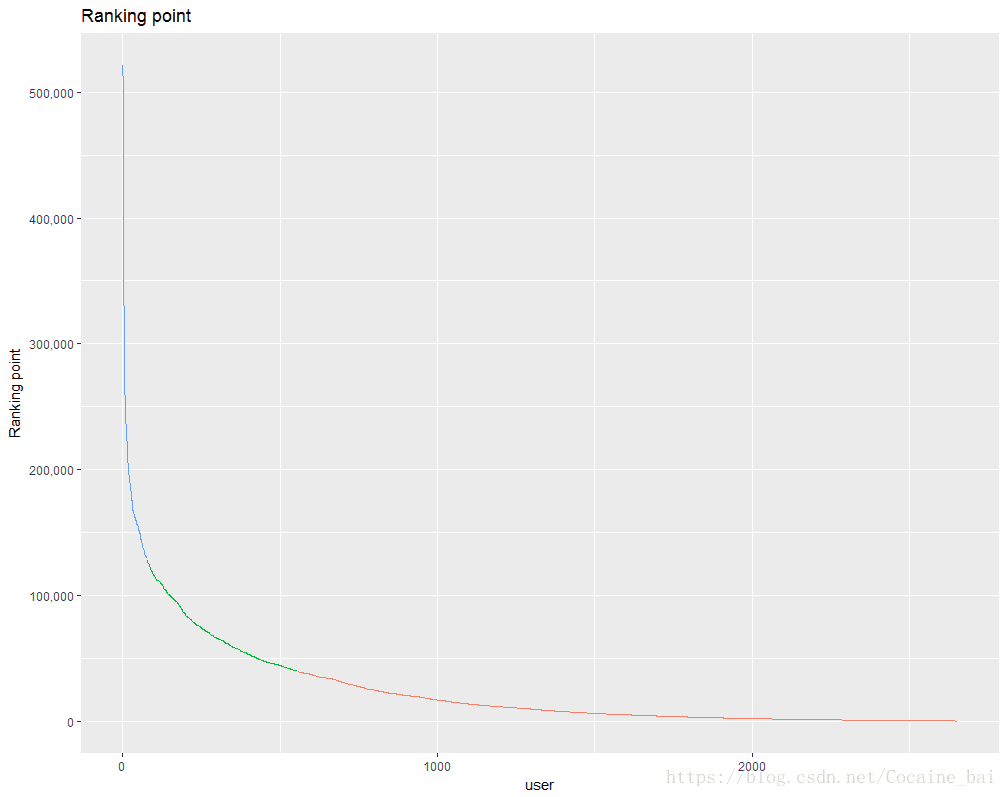
2.限定排名考前的用户:
> user.action.h <- user.action2[user.action2$cluster >= 2,names(user.action)]3.进行主成分分析:
行为日志里保存着用户所有行为的记录,可能存在各个行为之间相互影响的情况。另外,由于用户有的行为并没有发生,因此值为0 的行为记录有很多。所以我们实际上拿到的数据并不会像教科书中的数据那样工整。在这种情况下,很有可能无法执行k-means 方法,因此我们要将数值大都为0 的变量和相关性较高的变量删除掉,然后利用主成分分析进行正交变换。
# 用于机器学习的库
# 利用库中包含的函数进行数据的前期处理
> library(caret)
> user.action.f <- user.action.h[, -c(1:4)]
> row.names(user.action.f) <- user.action.h$user_id
> head(user.action.f)
# 删除那些信息量小的变量
> nzv <- nearZeroVar(user.action.f)
> user.action.f.filterd <- user.action.f[,-nzv]
# 删除那些相关性高的变量
> user.action.cor <- cor(user.action.f.filterd)
> highly.cor.f <- findCorrelation(user.action.cor,cutoff=.7)
> user.action.f.filterd <- user.action.f.filterd[,-highly.cor.f]
# 进行主成分分析
# pca
> user.action.pca.base <- prcomp(user.action.f.filterd, scale = T)4.进行聚类:
> user.action.pca <- data.frame(user.action.pca.base$x)
> keys <- names(user.action.pca)
> user.action.km <- ykmeans(user.action.pca, keys, "PC1", 3:6)
> table(user.action.km$cluster)
1 2 3 4 5
23 228 88 164 54 结果如下图:
> ggplot(user.action.km,
+ aes(x=PC1,y=PC2,col=as.factor(cluster), shape=as.factor(cluster))) +
+ geom_point()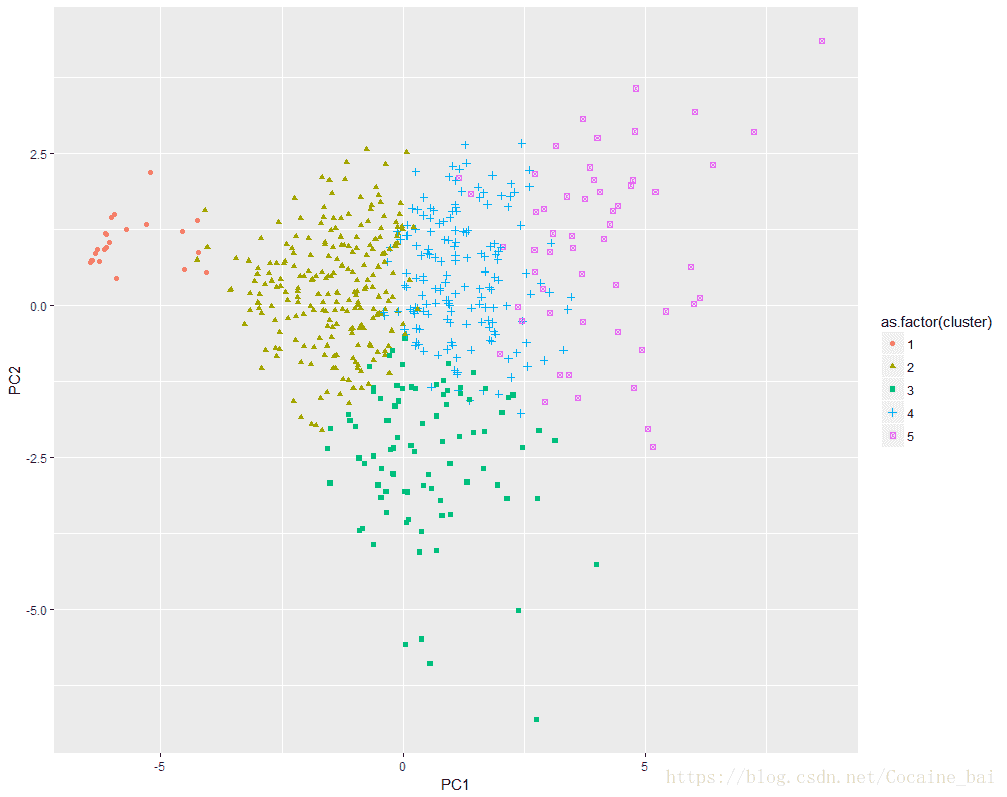
5.形成雷达图:
df.filterd <- createRadarChartDataFrame(scale(df.filterd))
names(df.filterd)
radarchart(df.filterd, seg = 5, plty = 1:5, plwd = 4, pcol = rainbow(5))
legend("topright", legend = 1:5, col = rainbow(5), lty = 1:5)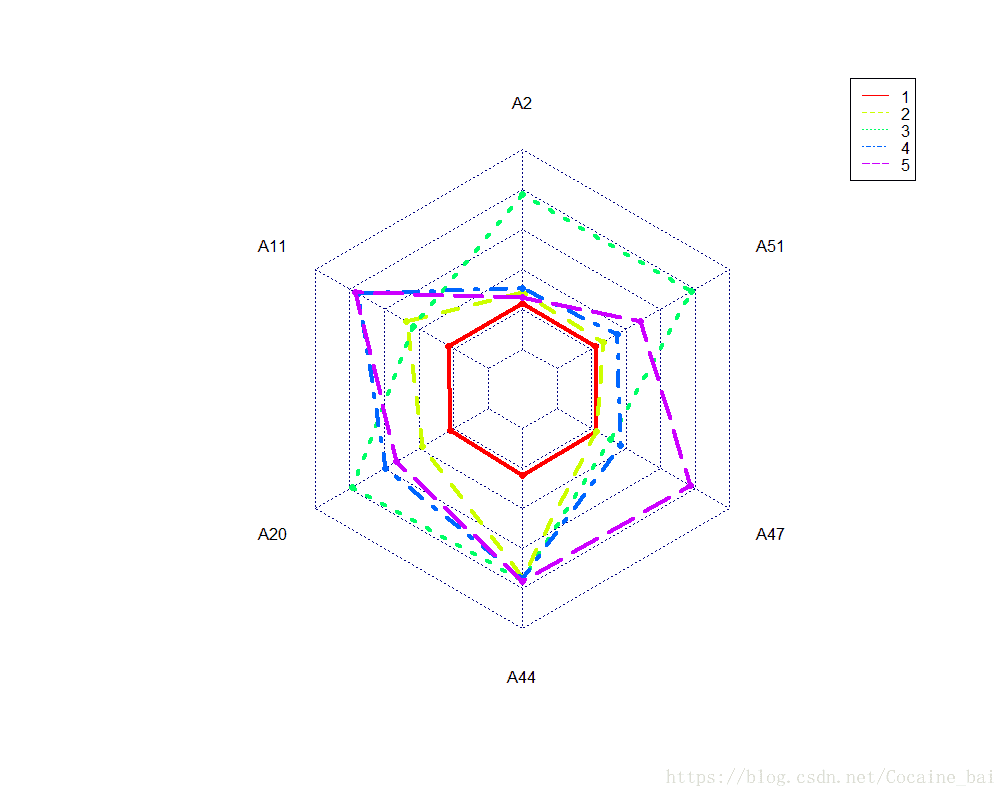
具体结果如上图,至此,数据分析结束~