这次分享的是在工作中经常用到的聚类分析,只要是工作中涉及到客户分群,哪能不用到聚类分析呢?聚类分析涉及的方法有层次聚类、kmeans聚类、密度聚类等,这里主要介绍最容易上手的kmeans聚类算法,上手就是王道!
kmeans聚类原理:基于原型的、划分的距离技术,它试图发现用户指定个数(K)的簇。统计学原理请大家自觉完成自学~~
实战一:
老板的需求:将17家门店分成3类,依据指标是销售金额和客户数量,其中要求销售金额权重(60%),客户数量权重(40%)
需求解析:很幸运,这是一个具体的要求,恩!这里已经指定分类数量,并且要求对各个指标赋权重,那么就需要对各个指标依次进行聚类,得到分组后,对各组值赋一个分数,再将分数乘以权重比例相加,就能实现boss的要求~~
#载入cluster
library(cluster)
#读入需要聚类的数据
a<-read.csv("testdata.csv",header=TRUE)
str(a)
'data.frame': 17 obs. of 3 variables:
$ 网点分类: Factor w/ 17 levels "store1","store10",..: 1 10 11 12 13 14 15 16 17 2 ...
$ 销售金额: num 29.41 9.72 6.15 5.72 5.57 ...
$ 客户数量: num 141.3 84.7 95 98.5 58.3 ...
#查看数据前4行
> head(a,n=4)
网点分类 销售金额 客户数量
1 store1 29.408587 141.33560
2 store2 9.719984 84.67674
3 store3 6.154773 95.00602
4 store4 5.721835 98.48247
#将第一个指标划分为3类
res1<-kmeans(a$销售金额,3)
#将第二个指标划分为3类
res2<-kmeans(a$客户数量,3)
#将聚类结果按列合并在数据集中
res3<-cbind(a,res1$cluster,res2$cluster)
#查看前4行数据
> head(res3,n=4)
网点分类 销售金额 客户数量 res1$cluster res2$cluster
1 store1 29.408587 141.33560 3 1
2 store2 9.719984 84.67674 1 2
3 store3 6.154773 95.00602 1 2
4 store4 5.721835 98.48247 1 2
#两个指标的聚类中心
> res1$centers
[,1]
1 5.519207
2 2.566558
3 29.408587
> res2$centers
[,1]
1 123.11407
2 86.39321
3 64.49325
#导出聚类结果
write.csv(res3,file='res3.csv')
因为聚类结果已经划分为3类,因此只要将3类结果赋予对应分值,然后按照权重计算出结果,解释出各个分类群体对应业务含义(其实就是打标签),就完成了门店的分类工作。
实战二:
老板需求:对我们的门店数据集进行分类
需求解析:这是一个很普遍的情况~~这里业务场景没有指定数量,也没有对指标赋予权重,我们要做的是将两个指标:销售金额与客户数量一起作为聚类的指标,参与聚类,得出结果,打出标签!考虑到数据单位不同,建议处理使用数据时进行标准化处理。
#载入factoextra包
library(factoextra)
#读入需要聚类的数据
a<-read.csv("testdata.csv",header=TRUE)
str(a)
#对数据进行标准化处理,需要去掉非数字的列
a1<-a[,-1]
b<-scale(a1)
#设置随机种子,保证试验客重复进行
set.seed(123)
#确定最佳聚类个数,使用组内平方误差和法
fviz_nbclust(b,kmeans,method="wss")+geom_vline(xintercept=4,linetype=2)
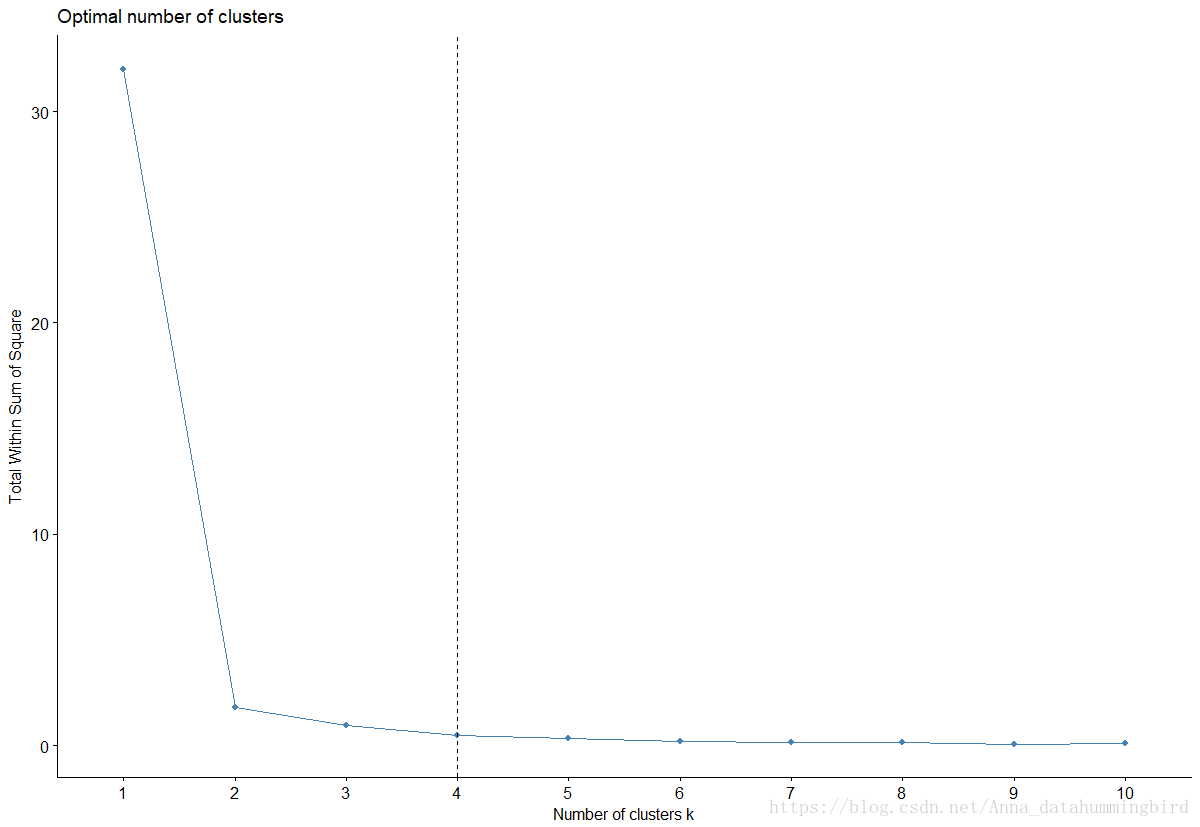
实用!这里函数直观给出最佳分类个数:4
#根据最佳聚类个数,进行kmeans聚类 res<-kmeans(b,4) #将分类结果放入原数据集中 res1<-cbind(a,res$cluster) #导出最终结果 write.csv(res1,file='res1.csv') #查看最终聚类图形 fviz_cluster(res,data=a1)

从图形可以看出fviz_cluster()函数功能还是非常强大,可视化效果很直观清晰,12号门店单独一类,6号门店单独一类,13号、9号等6家门店一类,11号、4号等9家一类,你需要做的是给这四类门店打标签,给出合理的业务描述,那么工作才算完成!
今天的分享就到这里,欢迎交流,下次再见!