1 损失函数
定义:将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。
应用:作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估模型。
分类:回归问题、分类问题
2 回归问题的损失函数
首先创建预测序列和目标序列作为张量
预测序列是(-1,1)的等差数列,目标值为0
sess = tf.Session()
x_vals = tf.linspace(-1.,1.,500)
target = tf.constant(0.)
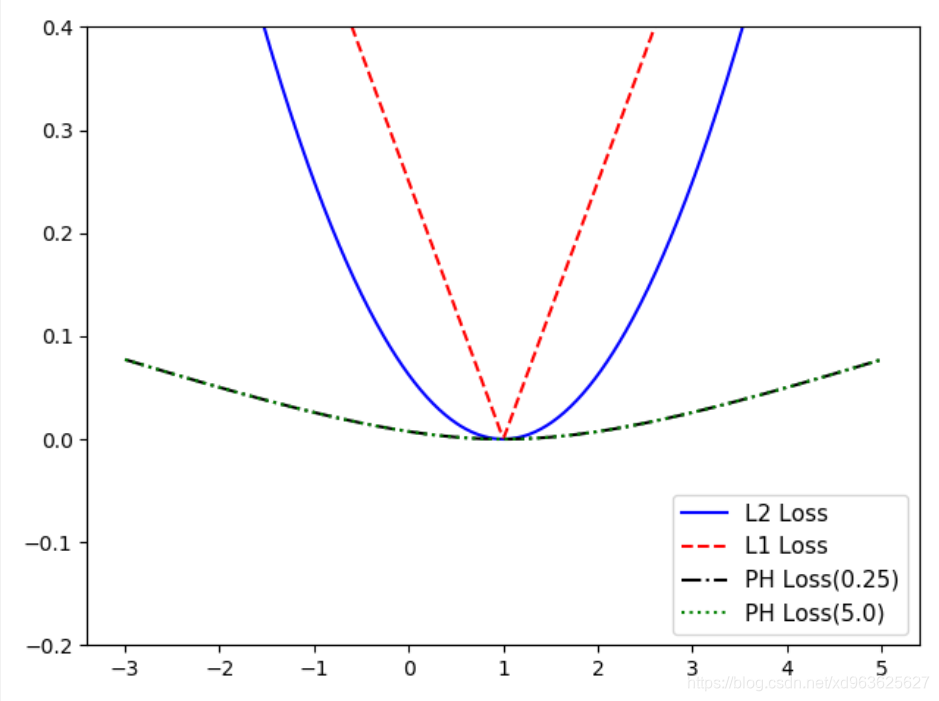
2.1 L2正则损失函数
L2正则损失函数又称欧拉损失函数,是预测值
与目标值
差值的平方和。
L2正则损失函数是非常有用的损失函数,因为它在目标值附近有更好的曲度。
机器学习算法利用这点收敛,并且离目标越近收敛越慢。
l2 = tf.square(target - vals)
2.2 L1正则损失函数
L1正则损失函数又称绝对值损失函数,区别是L2是对差值求绝对值。
L1正则损失函数在目标值附近不平滑,不能很好地收敛。
l1 = tf.abs(target - vals)
2.3 Pseudo-Huber损失函数
Pseudo-Huber损失函数是Huber损失函数的连续、平滑估计。
它试图利用L1和L2正则削减极值处的陡峭,使得目标值附近连续。
这个函数在目标附近是凸的,并且对数据中的游离点较不敏感。
具有上述的两个损失函数的优点。需要一个额外的参数delta决定曲线的斜率。
它的表达式依赖参数
。后面会图示
和
的区别:
delta1 = tf.constant(0.25)
ph_y_vals1 = tf.multiply(tf.square(delta1), tf.sqrt(1. +
tf.square(target - x_vals)/delta1) - 1.)
delta2 = tf.constant(5)
ph_y_vals2 = tf.multiply(tf.square(delta1), tf.sqrt(1. +
tf.square(target - x_vals)/delta1) - 1.)
3 分类问题的损失函数
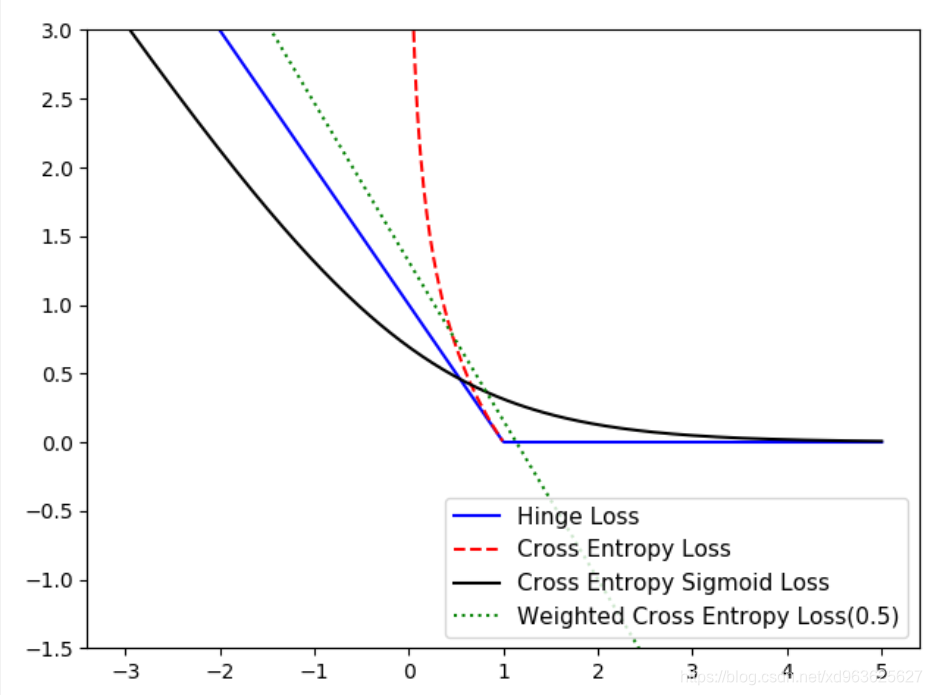
3.1 Hinge损失函数
Hinge损失函数主要用来评估SVM算法,但有时也用来评估神经网络算法。
在本例中是计算两个目标类(-1,1)之间的损失。
下面的代码中,使用目标值1,所以预测值离1越近,损失函数值越小:
hinge_y_vals = tf.maximum(0.,1.-tf.multiply(target,x_vals))
hinge_y_out = sess.run(hinge_y_vals)
3.2 两类交叉熵损失函数
两类交叉熵损失函数又叫逻辑损失函数
当预测两类目标0或者1时,希望度量预测值到真实分类值(0或者1)的距离,
这个距离经常是0到1之间的实数。为了度量这个距离,可以使用信息论中的交叉熵
ce_y_vals = -tf.multiply(target, tf.log(x_vals)-
tf.multiply((1.-target),tf.log(1.-x_vals)))
ce_y_out = sess.run(ce_y_vals)
3.3 sigmoid交叉熵损失函数
sigmoid交叉熵损失函数与上一个损失函数非常类似,
不同的是,它先把x_vals值通过sigmoid函数转换,再计算交叉熵损失
sigmoid_y_vals = tf.nn.sigmoid_cross_entropy_with_logits(
logits=x_vals,labels=targets)
sigmoid_y_out = sess.run(sigmoid_y_vals)
3.4 加权交叉熵损失函数
加权交叉熵损失函数是Sigmoid交叉熵损失函数的加权,对正目标加权。
下面的例子中将正目标加权权重设为0.5
weight = tf.constant(0.5)
ce_weighted_y_vals = tf.nn.weighted_cross_entropy_with_logits(
x_vals, targets, weight)
ce_weighted_y_out = sess.run(ce_weighted_y_vals)
3.5 Softmax交叉熵损失函数
Softmax交叉熵损失函数只针对单个目标分类的计算损失。
通过softmax函数将输出结果转化成概率分布,然后计算真值概率分布的损失。
unscaled_logits = tf.constant([[1.,-3.,10.]])
target_dist = tf.constant([[0.1,0.02,0.88]])
softmax_xentropy = tf.nn.softmax_cross_entropy_with_logits(
logits=unscaled_logits,labels=target_dist)
print(sess.run(softmax_xentropy))
3.6 稀疏Softmax交叉熵损失函数
稀疏Softmax交叉熵损失函数和上一个损失函数类似
它把目标分类为true的转化成index
而Softmax交叉熵损失函数将目标转成概率分布
unscaled_logits = tf.constant([[1.,-3.,10.]])
sparse_target_dist = tf.constant([2])
sparse_xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=unscaled_logits,labels=sparse_target_dist)
print(sess.run(sparse_xentropy))
4 matplotlib绘制损失函数
x_array = sess.run(x_vals)
plt.plot(x_array,l2_y_out,'b-',label='L2 Loss')
plt.plot(x_array,l1_y_out,'r--',label='L1 Loss')
plt.plot(x_array,ph_y_out1,'k-.',label='PH Loss(0.25)')
plt.plot(x_array,ph_y_out2,'g:',label='PH Loss(5.0)')
plt.ylim(-0.2,0.4)
plt.legend(loc='lower right', prop={'size':11})
plt.show()
# 三、matplotlib绘制分类算法的损失函数
plt.plot(x_array,hinge_y_out,'b-',label='Hinge Loss')
plt.plot(x_array,ce_y_out,'r--',label='Cross Entropy Loss')
plt.plot(x_array,sigmoid_y_out,'k-',label='Cross Entropy Sigmoid Loss')
plt.plot(x_array,ce_weighted_y_out,'g:',label='Weighted Cross Entropy Loss(0.5)')
plt.ylim(-1.5,3)
plt.legend(loc='lower right',prop={'size':11})
plt.show()
4.1 回归算法的损失函数图像
4.2 分类算法的损失函数图像