一、均方误差
一般地,在样本量一定时,评价一个点估计的好坏标准使用的指标总是点估计x
与参数真值x' 的距离的函数,最常用的函数是距离的平方,由于估计量
具有随机性,可以对该函数求期望,这就是下式给出的均方误差:
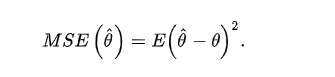
以下例程中拟定 y=x1+x2 为目标函数,随机初始化参数并加入噪声进行迭代,采用均方误差的损失函数进行梯度下降,不断逼近目标。
代码:
SEED = 23455
rdm = np.random.RandomState(seed=SEED) # 生成[0,1)之间的随机数
x = rdm.rand(32, 2)
y_ = [[x1 + x2 + (rdm.rand() / 10.0 - 0.05)] for (x1, x2) in x] # 生成噪声[0,1)/10=[0,0.1); [0,0.1)-0.05=[-0.05,0.05)
x = tf.cast(x, dtype=tf.float32)
w1 = tf.Variable(tf.random.normal([2, 1], stddev=1, seed=1))
epoch = 15000
lr = 0.002
for epoch in range(epoch):
with tf.GradientTape() as tape:
y = tf.matmul(x, w1)
loss_mse = tf.reduce_mean(tf.square(y_ - y))
grads = tape.gradient(loss_mse, w1)
w1.assign_sub(lr * grads)
if epoch % 500 == 0:
print("After %d training steps,w1 is " % (epoch))
print(w1.numpy(), "\n")
print("Final w1 is: ", w1.numpy())结果:

二、交叉熵
交叉熵:表示概率分布之间的距离
交叉熵函数:tf.losses.categorical_crossentropy(x,y)
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。(百度百科)

例:
loss_ce1 = tf.losses.categorical_crossentropy([1, 0], [0.6, 0.4])
loss_ce2 = tf.losses.categorical_crossentropy([1, 0], [0.8, 0.2])
print("loss_ce1:", loss_ce1)
print("loss_ce2:", loss_ce2)结果:

注意:
# 一般而言,softmax于交叉熵结合使用:先计算softmax然后计算损失函数 # 函数为:tf.nn.softmax_cross_entropy_with_logits(x,y) #该函数可以同时计算softmax和交叉熵
如:使用softmax函数和交叉熵函数分别计算和使用softmax_cross_entropy_with_logits单个函数计算的结果应该是相同的。
# 一般而言,softmax于交叉熵结合使用:先计算sftmax然后计算损失函数
# 函数为:tf.nn.softmax_cross_entropy_with_logits(x,y)
y_ = np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1], [1, 0, 0], [0, 1, 0]])
y = np.array([[12, 3, 2], [3, 10, 1], [1, 2, 5], [4, 6.5, 1.2], [3, 6, 1]])
y_pro = tf.nn.softmax(y)
loss_ce1 = tf.losses.categorical_crossentropy(y_,y_pro)
loss_ce2 = tf.nn.softmax_cross_entropy_with_logits(y_, y)
print('分步计算的结果:\n', loss_ce1)
print('结合计算的结果:\n', loss_ce2)
# 输出的结果相同结果:

三、自定义损失函数
例如下边例子中的分段的损失函数,我们可以用where语句来表示这个损失函数:
loss = tf.reduce_sum(tf.where(tf.greater(y, y_), (y - y_) * COST, (y_ - y) * PROFIT))
损失函数表达式:

代码展示:
# 自定义损失函数
SEED = 23455
COST = 99
PROFIT = 1
rdm = np.random.RandomState(SEED)
x = rdm.rand(32, 2)
y_ = [[x1 + x2 + (rdm.rand() / 10.0 - 0.05)] for (x1, x2) in x] # 生成噪声[0,1)/10=[0,0.1); [0,0.1)-0.05=[-0.05,0.05)
x = tf.cast(x, dtype=tf.float32)
w1 = tf.Variable(tf.random.normal([2, 1], stddev=1, seed=1))
epoch = 10000
lr = 0.002
for epoch in range(epoch):
with tf.GradientTape() as tape:
y = tf.matmul(x, w1)
loss = tf.reduce_sum(tf.where(tf.greater(y, y_), (y - y_) * COST, (y_ - y) * PROFIT))
grads = tape.gradient(loss, w1)
w1.assign_sub(lr * grads)
if epoch % 500 == 0:
print("After %d training steps,w1 is " % (epoch))
print(w1.numpy(), "\n")
print("Final w1 is: ", w1.numpy())
# 自定义损失函数
# 酸奶成本1元, 酸奶利润99元
# 成本很低,利润很高,人们希望多预测些,生成模型系数大于1,往多了预测结果:

总之,我们可以自己定义想要的损失函数,而不必完全使用tensorflow所带有的损失函数,这提高了它的灵活性和实用性。
参考链接:
https://baike.baidu.com/item/%E4%BA%A4%E5%8F%89%E7%86%B5/8983241?fr=aladdin