SSD的损失函数包含用于分类的log loss 和用于回归的smooth L1,并对正负样本比例进行了控制,可以提高优化速度和训练结果的稳定性。

总的损失函数是分类和回归的误差的带权加和。α表示两者的权重,N表示匹配到default box的数量
1 loc的损失函数:smooth L1
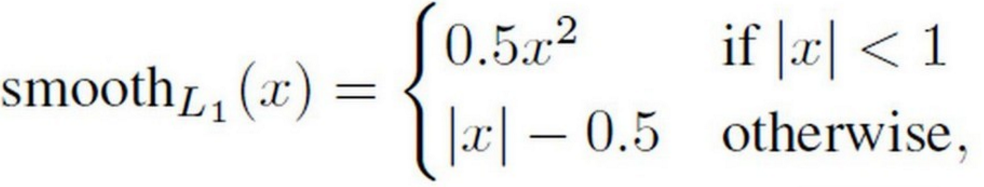
y_true:shape: (batch_size,n_boxes,4) ,最后一个维度包括(xmin, xmax, ymin, ymax)
y_pred的shape应该和y_true保持一致。
但是一张图片中的ground truth就几个到几十个,如何和y_pred保持统一形状
def smooth_L1_loss(self, y_true, y_pred):
absolute_loss = tf.abs(y_true - y_pred)
square_loss = 0.5 * (y_true - y_pred)**2
l1_loss = tf.where(tf.less(absolute_loss, 1.0), square_loss, absolute_loss - 0.5)
return tf.reduce_sum(l1_loss, axis=-1)
2 conf的损失函数:Log loss
y_true shape:(batch_size, n_boxes, n_classes)
def log_loss(self, y_true, y_pred):
# 确保y_pred中不含0,否则会使log函数崩溃的
y_pred = tf.maximum(y_pred, 1e-15)
# Compute the log loss
log_loss = -tf.reduce_sum(y_true * tf.log(y_pred), axis=-1)
return log_loss3 hard negative mining
主要思路:
1.根据正样本的个数和正负比例,确定负样本的个数,negative_keep
2.找到confidence loss最大的negative_keep个负样本,计算他们的分类损失之和
3.计算正样本的分类损失之和,分类损失是正样本和负样本的损失和
4.计算正样本的位置损失localization loss.无法计算负样本位置损失 %>_<%
5. 对回归损失和位置损失之和
def compute_loss(self, y_true, y_pred):
self.neg_pos_ratio = tf.constant(self.neg_pos_ratio)
self.n_neg_min = tf.constant(self.n_neg_min)
self.alpha = tf.constant(self.alpha)
batch_size = tf.shape(y_pred)[0] # Output dtype: tf.int32
n_boxes = tf.shape(y_pred)[1]
# Output dtype: tf.int32, note that `n_boxes` in this context denotes the total number of boxes per image, not the number of boxes per cell.
## 计算每个box的类别和框的损失
classification_loss = tf.to_float(self.log_loss(y_true[:,:,:-12], y_pred[:,:,:-12]))
# Output shape: (batch_size, n_boxes)
localization_loss = tf.to_float(self.smooth_L1_loss(y_true[:,:,-12:-8], y_pred[:,:,-12:-8]))
# Output shape: (batch_size, n_boxes)
## 为正的和负的groud truth 制作mask
#此时需要对y_true提前进行编码。
#对于类别只有所属的类别是1,其他全是0,对于出ground truth之外的box的类别,背景设为1,其余全设为0
negatives = y_true[:,:,0] # Tensor of shape (batch_size, n_boxes)
positives = tf.to_float(tf.reduce_max(y_true[:,:,1:-12], axis=-1))
# Tensor of shape (batch_size, n_boxes)
#统计正样本的个数
n_positive = tf.reduce_sum(positives)
# 掩盖负的box,计算正样本box的损失之和
pos_class_loss = tf.reduce_sum(classification_loss * positives, axis=-1) # Tensor of shape (batch_size,)
# 计算所有负样本的box的损失之和
neg_class_loss_all = classification_loss * negatives # Tensor of shape (batch_size, n_boxes)
#计算损失非零的负样本的个数
n_neg_losses = tf.count_nonzero(neg_class_loss_all, dtype=tf.int32) # The number of non-zero loss entries in `neg_class_loss_all`
# Compute the number of negative examples we want to account for in the loss.
# 至多保留 `self.neg_pos_ratio` 倍于 y_true中正样本的数量, 至少保留 n_neg_min个负样本 per batch.
n_negative_keep = tf.minimum(tf.maximum(self.neg_pos_ratio * tf.to_int32(n_positive), self.n_neg_min), n_neg_losses)
def f1():
'''
当不存在负样本的ground truth时,直接返回0
'''
return tf.zeros([batch_size])
def f2():
'''
获得confidence loss最高的k(n_negative_keep)个负样本。
损失越大说明,越难训练,也就是寻找hard negative
'''
# To do this, we reshape `neg_class_loss_all` to 1D
neg_class_loss_all_1D = tf.reshape(neg_class_loss_all, [-1]) # Tensor of shape (batch_size * n_boxes,)
# ...and then we get the indices for the `n_negative_keep` boxes with the highest loss out of those...
values, indices = tf.nn.top_k(neg_class_loss_all_1D,
k=n_negative_keep,
sorted=False) # We don't need them sorted.
# 对这些选择出来的保留负样本,做一个掩码mask
negatives_keep = tf.scatter_nd(indices=tf.expand_dims(indices, axis=1),
updates=tf.ones_like(indices, dtype=tf.int32),
shape=tf.shape(neg_class_loss_all_1D)) # Tensor of shape (batch_size * n_boxes,)
negatives_keep = tf.to_float(tf.reshape(negatives_keep, [batch_size, n_boxes])) # Tensor of shape (batch_size, n_boxes)
# 计算保留的负样本的损失之和
neg_class_loss = tf.reduce_sum(classification_loss * negatives_keep, axis=-1) # Tensor of shape (batch_size,)
return neg_class_loss
neg_class_loss = tf.cond(tf.equal(n_neg_losses, tf.constant(0)), f1, f2)
class_loss = pos_class_loss + neg_class_loss # Tensor of shape (batch_size,)
# 3: 计算正样本的位置损失之和
# 我们不能计算对于那些预测为负样本的box计算坐标损失,你可能会问,为啥呢?
#因为根本不存在标准的负样本box的坐标啊。对于正样本可以计算是因为存在对应的ground truth
loc_loss = tf.reduce_sum(localization_loss * positives, axis=-1) # Tensor of shape (batch_size,)
total_loss = (class_loss + self.alpha * loc_loss) / tf.maximum(1.0, n_positive) # In case `n_positive == 0`
total_loss = total_loss * tf.to_float(batch_size)
return total_loss完整代码,在这里
刚开始啃这一块,如果有理解的不对的地方,欢迎指出