一、交叉熵损失原理
一般情况下,在分类任务中,神经网络最后一个输出层的节点个数与分类任务的标签数相等。
假设最后的节点数为N,那么对于每一个样例,神经网络可以得到一个N维的数组作为输出结果,数组中每一个维度会对应一个类别。在最理想的情况下,如果一个样本属于k,那么这个类别所对应的第k个输出节点的输出值应该为1,而其他节点的输出都为0,即[0,0,1,0,….0,0],这个数组也就是样本的Label,是神经网络最期望的输出结果,交叉熵就是用来判定实际的输出与期望的输出的接近程度。
二、公式
1.softmax回归
假设神经网络的原始输出为y1,y2,….,yn,那么经过Softmax回归处理之后的输出为:
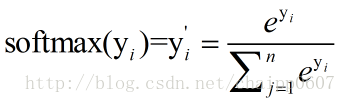
单个节点的输出变成的一个概率值。
2.交叉熵的原理
交叉熵刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。假设概率分布p为期望输出,概率分布q为实际输出,H(p,q)为交叉熵,则:
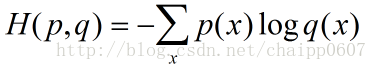
除此之外,交叉熵还有另一种表达形式,还是使用上面的假设条件:
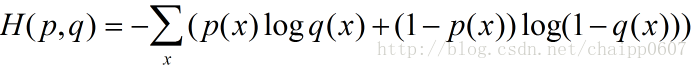
在实际的使用训练过程中,数据往往是组合成为一个batch来使用,所以对用的神经网络的输出应该是一个m*n的二维矩阵,其中m为batch的个数,n为分类数目,而对应的Label也是一个二维矩阵,还是拿上面的数据,组合成一个batch=2的矩阵:
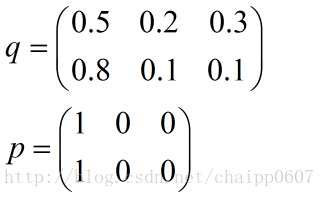
所以交叉熵的结果应该是一个列向量(根据第一种方法):
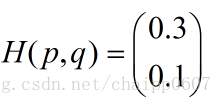
而对于一个batch,最后取平均为0.2。
三、Tensorflow实现
函数定义:def softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, dim=-1, name=None)
示例:计算batch = 2,num_labels = 3的2*3矩阵
实际输出(概率):
[[0.2,0.1,0.9],
[0.3,0.4,0.6]]
期望输出(概率)
[[0,0,1],
[1,0,0]]
计算交叉熵损失,对于一个batch,最后取平均为1.36573195。
import tensorflow as tf
input_data = tf.Variable([[0.2, 0.1, 0.9], [0.3, 0.4, 0.6]], dtype=tf.float32)
output = tf.nn.softmax_cross_entropy_with_logits(logits=input_data, labels=[[0, 0, 1], [1, 0, 0]])
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
print(sess.run(output))
# [1.36573195]