在tensorflow2.0 中,使用模块model.compile时,需要选择损失函数,例如:
model.compile(optimizer=‘Adam’,
loss=‘sparse_categorical_crossentropy’,
metrics=[‘accuracy’])
于是,在tensorflow2.0中有几个损失函数的表示方法?参考文档
下列公式中,
表示预测值。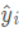
在这里插入图片描述
表示真实值。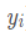
查看相关文档,大概有以下一些参数:
1、mean_squared_error:均方误差函数,又称mse,最基本的损失函数表示法。含义是神经网络计算值(预测值)与标签值的平方误差和,该值越小,模型越准确。
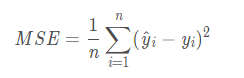
2、mean_absolute_error:平均绝对误差,又称mae,主要用于显著性目标检测。
显著性目标举例:当你看到一副图像的时候,重点潜意识关注的对象,而通过该方法可以检测到。值越小,模型越准确。
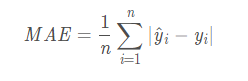
3、mean_absolute_percentage_error:平均绝对百分比误差,又称mape。
需要注意的是样本中不能有0值。当mape=0时,表示模型完美,而当mape=100时,则表示模型很差,不能使用。
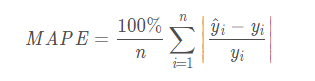
4、Symmetric Mean Absolute Percentage Error:对称平均绝对百分比误差。
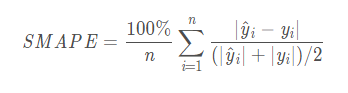
当真实值有数据等于0,而预测值也等于0时,存在分母0除问题,该公式不可用。
5、mean_squared_logarithmic_error:
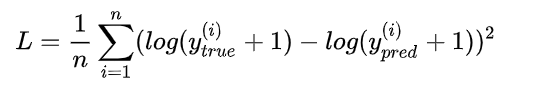
6、hinge loss:折页损失函数或者铰链损失函数,最著名的应用是作为SVM的目标函数。
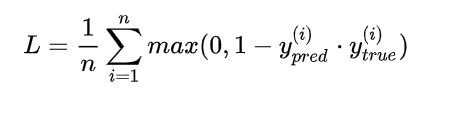
其含义为,ypred的值在 -1到1之间即可,并不鼓励 |y|>1,即让某个样本能够正确分类就可以了,不鼓励分类器过度自信,当样本与分割线的距离超过1时并不会有任何奖励。目的在于使分类器更专注于整体的分类误差。
7、squared_hinge:平方铰链损失函数。
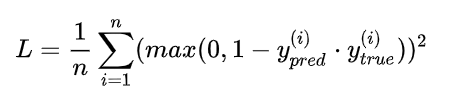
8、categorical_hinge。分类铰链损失函数。
def categorical_hinge(y_true, y_pred):
pos = K.sum(y_true * y_pred, axis=-1)
neg = K.max((1. - y_true) * y_pred, axis=-1)
return K.maximum(0., neg - pos + 1.)
9、categorical_crossentropy loss:交叉熵损失函数。交叉熵是用来评估当前训练得到的概率分布与真实分布的差异情况。它刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。
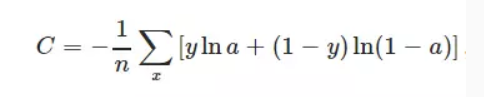
未完待续。
途中公式来源于网络资源。

{kind=link}