本章节主要讲有关神经网络的三个重要部分:激活函数、损失函数、梯度下降。其余学习内容参考:TensorFlow 学习目录。
目录
5. ReLU变种函数:Noisy relus、Leaky relus、Elus
1. 均值平方差(Mean Squared Error,MSE)
一、激活函数
引入激活函数的目的是用来加入非线性因素,以解决线性模型表达不足的问题,在整个神经网络中起到了重要的作用。因为神经网络的数学基础是处处可微的,所以选取的激活函数,要保证输入和输出也是可微的。
1. Sigmoid函数
<1>函数表达式
<2>函数曲线

<3>TensorFlow调用方式
tf.nn.sigmoid(x, name=None)2. Tanh函数
<1>函数表达式
<2>函数曲线

<3>TensorFlow调用方式
tf.nn.tanh(x, name=None)3. ReLU函数
<1>函数表达式
<2>函数曲线

<3>TensorFlow调用方式
tf.nn.relu(features, name=None)
tf.nn.relu6(features, name=None) #增加一个上限=64. SoftPlus函数
该函数将比于ReLU更加的平滑
<1>函数表达式
<2>函数曲线
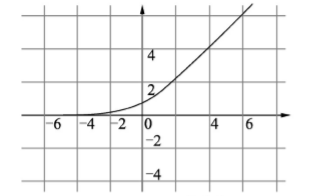
<3>TensorFlow调用方式
tf.nn.softplus(features, name=None)5. ReLU变种函数:Noisy relus、Leaky relus、Elus
<1>函数表达式
<2>用意
- Noisy relus函数给 x 增加了一个随机的扰动
- Leaky relus函数将 x 小于 0 的部分乘上一个很小的数来让其影响变小
- Elus函数将 x 小于 0 的部分让其取一个 0 附近很小的值,让其影响变小
<3>TensorFlow调用方式
tf.nn.elu(features, name=None)
# leaky relus函数
tf.maximum(x, leak*x, name=name)6. Swish函数
该函数是谷歌公司发现的一个效果更优于ReLU的激活函数,经过测试表明,在保持所有的模型参数不变的情况下,只要把原有的ReLU激活函数改为Swish,模型的准确率均有提升。
<1>函数表达式
<3>实现代码
def Swish(x, beta=1)
return x * tf.nn.sigmoid(x*beta)7. softmax函数
该函数用于处理分类问题
<1>函数表达式
<2>TensorFlow调用方式
# 计算softmax
tf.nn.softmax(logits, name=None)
# 对softmax取对数
tf.nn.log_softmax(logits, name=None)8. 激活函数的总结
- 在每次迭代的时候,如果特征相差明显时,使用Tanh函数可以在迭代过程中不断地扩大特征
- 如果每次迭代相差不到,需要进行微调的时候,使用sigmoid函数
- 如果数据是有少数极值,其它基本是 0,可以使用ReLU函数来保证数据的稀疏性
二、损失函数
损失函数定义了BP的源头,其是网络学习质量的关键所在,下面介绍几种常见的loss函数。
1. 均值平方差(Mean Squared Error,MSE)
<1>函数表达式
其中logits表示预测值,labels表示真实标签。
2. 交叉熵(Cross Entropy)
<1>函数表达式
其中 y 表示标签,a 表示预测值。
3. TensorFlow调用方式
# 均方损失
loss = tf.reduce_mean(tf.square(logits-labels))
三、梯度下降
该过程是为了让模型逼近最小偏差,不同的梯度下降优化器具有不同的效果。
1. 优化器

TensorFlow中的使用方法
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)2. 退化学习率
思想是,随着epoch的进行,按照一定的比率去降低学习率大小
- 如果学习率的值比较大,则训练速度会提升,但是结果精度不够
- 如果学习率的值比较小,精度虽然提升了,但是训练时间会非常的大
import tensorflow as tf
global_step = tf.Variable(0, trainable=False)
initial_learning_rate = 0.1
learning_rate = tf.train.exponential_decay(initial_learning_rate,global_step=global_step,decay_steps=10,decay_rate=0.98)
opt = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
add_global = global_step.assign_add(1)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print (sess.run(learning_rate))
for i in range(40):
g, rate = sess.run([add_global, learning_rate])
print (g, rate)输出
0.1
1 0.09979818
2 0.09959676
3 0.099395745
4 0.099195145
5 0.09899495
6 0.09879515
7 0.09859577
8 0.09839677
9 0.09819818
10 0.098
11 0.097802214
12 0.097604826
13 0.09740784
14 0.09721125
15 0.09701505
16 0.09681925
17 0.09662386
18 0.09642884
19 0.096234225
20 0.09604
21 0.095846176
22 0.09565274
23 0.095459685
24 0.09526703
25 0.09507475
26 0.09488287
27 0.094691366
28 0.094500266
29 0.094309546
30 0.094119206
31 0.09392925
32 0.09373968
33 0.09355049
34 0.09336169
35 0.09317326
36 0.09298521
37 0.09279755
38 0.09261026
39 0.09242335
40 0.09223682