基本的统计学概念
描述性统计分析
统计量
-
均值 --表示一种数据集中趋势的量数
-
标准差 --反应数据的离散程度,数据平均值的分散度量
-
中位数 --一种不受极大值极小值影响、衡量集中趋势的办法
-
分位数-- 将一个随机变量的概率分布范围分为几个等份的数值点
-
众数 – 统计分布上具有明显集中趋势点的数值
-
极差 —数据的最大值-数据的最小值 反应变量分布的离散程度
-
四分位差 --上四分位差-下四分位差 反应中间50%数据的离散程度
-
方差–标准差的平方,反映数据离散程度的度量
-
变异系数 --数据的标准差/数据的均值 消除度量和量纲的影响,比较不同数据的离散程度
-
点估计 一种估计方式 用样本统计量去估计总体
-
区间估计 90%的可能性确定增长率在区间3%到5%,3%到5%是置信区间, 90%是置信度
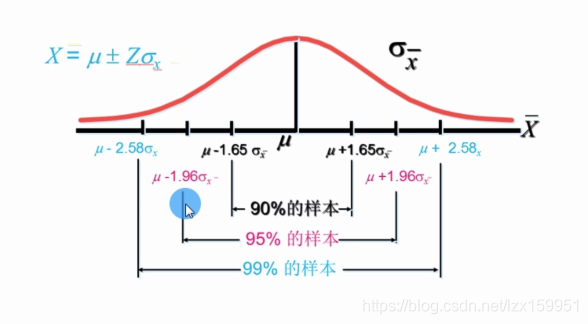
记一个结论:
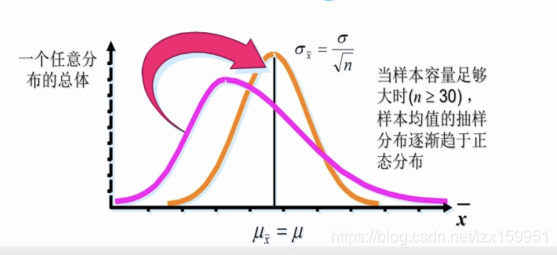
样本均值近似正太分布。多次对数据抽样,产生的多个样本均值服从正态分布。若样本数量足够大,产生的均值是近似符合正态分布的。
中心极限定理:
设从均值μ,方差为σ2的一个任意总体中抽取容量为n的样本,当n充分大时,样本均值的抽样分布近似服从均值为μ、方差为α/√n的正态分布。
接下来咱们使用python代码来实现这些统计函数
首先导入我们所需要的包
from scipy import stats
import pandas as pd
import numpy as np
导入数据以及计算输出
#导入数据
tips = pd.read_csv('tips.csv')
#均值
tips_mean = tips['tip'].mean()
#标准差
tips_std = tips['tip'].std()
#方差
tips_var = tips['tip'].var()
#变异系数
tips_c = tips_std/tips_mean
#中位数
tips_median = tips['tip'].median()
#分位数
tips_q1 = tips['tip'].quantile(0.25)
tips_q2 = tips['tip'].quantile(0.75)
#四分位差
tips_q3 = tips_q2-tips_q1
#众数
tips_m = tips['tip'].mode()
#计算样本均值标准误差 -自带方法
se = stats.sem(tips['tip'])
#使用公式自己计算
#数据长度
n = len(tips['tip'])
se1 = tips_std/np.sqrt(n)
#se 和se1 这两个值是一样的。
print(se,se1)
#求百分之95的置信区间 -使用自带方法
interval = stats.norm.interval(0.95,tips_mean,se)#参数分别表示 百分比,均值,样本均值标准误差
#使用公式进行计算
interval1 = tips_mean-1.96*se
interval2 =tips_mean+1.96*se
#(interval1,interval2) 与interval 的值相同
print("均值:%f,标准差:%f,方差:%f,变异系数:%f,中位数:%f,分位数:%f,四分位差:%f,众数:%f" % \
(tips_mean,tips_std,tips_var,tips_c,tips_median,tips_q1,tips_q3,tips_m))
