文章目录
- (一)概率论数理统计中的概念
- (二)统计分析的常见指标
- (三)统计分析的特点
- (四)统计分析的基本步骤
- (四)数据统计分析pandas工具使用(共12节入门教程)
- pandas学习笔记(一):对象创建(Object creation)
- pandas学习笔记(二):查看数据(Viewing data)
- pandas学习笔记(三):选择(Selection)
- pandas学习笔记(四):数据缺失(Missing data)
- pandas学习笔记(五):操作(Operations)
- pandas学习笔记(六):合并(Operations)
- pandas学习笔记(七):分组(Grouping)
- pandas学习笔记(八):重塑(Reshaping)
- pandas学习笔记(九):时间序列(Time series)
- pandas学习笔记(十):分类(Categoricals)
- pandas学习笔记(十一):绘图(Plotting)
- pandas学习笔记(十二):数据的输入与输出(Getting data in/out)
- 附:参考资料
(一)概率论数理统计中的概念
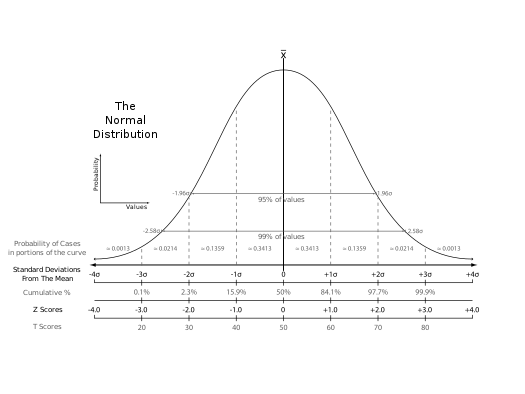
(1)随机分布
随机变量(random variable) 表示随机试验各种结果的实值单值函数。随机事件不论与数量是否直接有关,都可以数量化,即都能用数量化的方式表达。
按照随机变量可能取得的值,可以把它们分为两种基本类型
- 1、离散型随机变量,即在一定区间内变量取值为有限个,或数值可以一一列举出来。例如某地区某年人口的出生数、死亡数,某药治疗某病病人的有效数、无效数等。
- 2、连续型随机变量,即在一定区间内变量取值有无限个,或数值无法一一列举出来。例如某地区男性健康成人的身长值、体重值,一批传染性肝炎患者的血清转氨酶测定值等。

(2)统计分布
统计分布(frequency distribution)亦称“次数(频数)分布(分配)” 。在统计分组的基础上,将总体中的所有单位按组归类整理,形成总体单位在各组间的分布。
分布在各组中的单位数叫做次数或频数。各组次数与总次数(全部总体单位数)之比,称为比率或频率。将各组别与次数依次编排而成的数列就叫做统计分布数列,简称分布数列或分配数列。
(二)统计分析的常见指标
(1)均值,方差,标准差,中位数,众数
- 均值:平均数,统计学术语,是表示一组数据集中趋势的量数,是指在一组数据中所有数据之和再除以这组数据的个数。
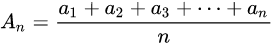
- 方差:方差是在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。

- 标准差:标准差(Standard Deviation) ,是离均差平方的算术平均数的平方根,用σ表示。在概率统计中最常使用作为统计分布程度上的测量。标准差是方差的算术平方根。 标准差能反映一个数据集的离散程度。平均数相同的两组数据,标准差未必相同。
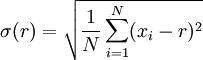
- 中位数:中位数(Median)又称中值,统计学中的专有名词,是按顺序排列的一组数据中居于中间位置的数,代表一个样本、种群或概率分布中的一个数值,其可将数值集合划分为相等的上下两部分。对于有限的数集,可以通过把所有观察值高低排序后找出正中间的一个作为中位数。如果观察值有偶数个,通常取最中间的两个数值的平均数作为中位数。
(2)总量指标
总量指标是用来反映社会经济现象在一定条件下的总规模、总水平或工作总量的统计指标。总量指标用绝对数表示,也就是用一个绝对数来反映特定现象在一定时间上的总量状况,它是一种最基本的统计指标。
(3)相对指标
相对指标亦称“统计相对数”。两个有联系的现象数值相比得到的比率。反映现象的发展程度、结构、强度、普遍程度或比例关系。分为:结构相对数、强度相对数、比较相对数、比例相对数、动态相对数、计划完成相对数等。表现形式是有名数和无名数。
如:甲地职工男职工人数占职工人数的70%
(4)平均指标
平均指标亦称“平均数”。同质总体内各单位某一数量标志的一般水平。平均数的特点是对总体各单位之间标志值的差异抽象化,用一个数字显示其一般水平。因此,它可用来比较不同时间、地点或部门之间同类现象水平的高低,分析现象间的相互关系,估计推算其他有关指标,如用样本平均每亩产量乘收获面积估算农作物总产量。
(5)变异指标
综合反映总体各单位标志值变异程度的指标。简称变异指标。它显示总体中变量数值分布的离散趋势,是说明总体特征的另一个重要指标,与平均数的作用相辅相成
(三)统计分析的特点
- 科学性 : 统计分析方法以数学为基础,具有严密的结构,需要遵循特定的程序和规范,从确立选题、提出假设、进行抽样、具体实施,一直到分析解释数据,得出结论,都须符合一定的逻辑和标准。
- 直观性: 现实世界是复杂多样的,其本质和规律难以直接把握,统计分析方法从现实情境中收集数据,通过次序、频数等直观、浅显的量化数字及简明的图表表现出来,这些数据的处理,将我们的研究与客观世界紧密相连,从而提示和洞悉现实世界的本质及其规律。
- 可重复性: 可重复性是衡量研究质量与水平高低的一个客观尺度,用统计分析方法进行的研究皆是可重复的。从课题的选取、抽样的设计,到数据的收集与处理,皆可在相同的条件下进行重复,并能对研究所得的结果进行验证。
(四)统计分析的基本步骤
- 收集数据: 收集数据是进行统计分析的前提和基础。
- 整理数据: 整理数据就是按一定的标准对收集到的数据进行归类汇总的过程。
- 分析数据: 分析数据指在整理数据的基础上,通过统计运算,得出结论的过程,它是统计分析的核心和关键。
(四)数据统计分析pandas工具使用(共12节入门教程)

pandas学习笔记(一):对象创建(Object creation)
pandas学习笔记(一):对象创建(Object creation)学习链接
pandas学习笔记(二):查看数据(Viewing data)
pandas学习笔记(二):查看数据(Viewing data)学习链接
pandas学习笔记(三):选择(Selection)
pandas学习笔记(三):选择(Selection)学习链接
pandas学习笔记(四):数据缺失(Missing data)
pandas学习笔记(四):数据缺失(Missing data)学习链接
pandas学习笔记(五):操作(Operations)
pandas学习笔记(五):操作(Operations)学习链接
pandas学习笔记(六):合并(Operations)
pandas学习笔记(六):合并(Operations)学习链接
pandas学习笔记(七):分组(Grouping)
pandas学习笔记(七):分组(Grouping)学习链接
pandas学习笔记(八):重塑(Reshaping)
pandas学习笔记(八):重塑(Reshaping)学习链接
pandas学习笔记(九):时间序列(Time series)
pandas学习笔记(九):时间序列(Time series)学习链接
pandas学习笔记(十):分类(Categoricals)
pandas学习笔记(十):分类(Categoricals)学习链接
pandas学习笔记(十一):绘图(Plotting)
pandas学习笔记(十一):绘图(Plotting)学习链接
pandas学习笔记(十二):数据的输入与输出(Getting data in/out)
pandas学习笔记(十二):数据的输入与输出(Getting data in/out)学习链接
附:参考资料
- 百度百科·随机分布
- https://baike.baidu.com/item/%E9%9A%8F%E6%9C%BA%E5%8F%98%E9%87%8F
- 百度百科·统计分布
- https://baike.baidu.com/item/%E7%BB%9F%E8%AE%A1%E5%88%86%E5%B8%83
- 智库百科·统计分析
- https://wiki.mbalib.com/wiki/%E7%BB%9F%E8%AE%A1%E5%88%86%E6%9E%90
- 维基百科·统计学
- https://zh.wikipedia.org/wiki/%E7%BB%9F%E8%AE%A1%E5%AD%A6
- 智库百科·统计分析
- https://wiki.mbalib.com/wiki/%E7%BB%9F%E8%AE%A1%E5%88%86%E6%9E%90