本文是翻译下面论文的一部分,本人不拥有版权,仅供学习交流。
作者所用的split Bregman方法我没找到源码,作者给的过程也不太清楚,难以实现,本人水平有限。
隐语义模型矩阵分解方法
Latent factor model 将评分矩阵分解为用户偏好矩阵和商品的属性特征矩阵,如图所示

求解方法如文章中所述,为了避免过度平滑,采用L1正则化项作约束。代价函数为

总体思路:随机初始化一个V矩阵,对于给定的V,可以使上式最小化,求得U;对于U又可以得到新的V,直到收敛,U和V在循环中更新。
具体方法:
1.对于给定的V,优化问题则变成
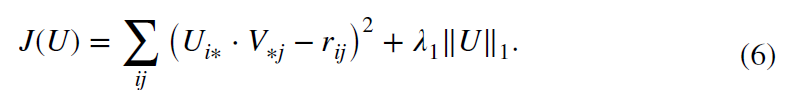
2.引入变量dU, bU, dU = U, bU = dU − U

【我不明白的是8式第一项中怎么出现了下标m,最后一项是什么范数,默认2范数??】
3.将上述算法分成三步,即迭代式
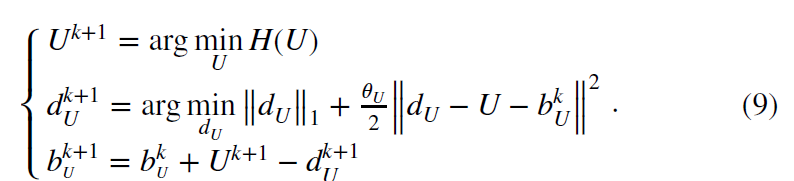
其中第一个可以用梯度下降法来做,α是步长
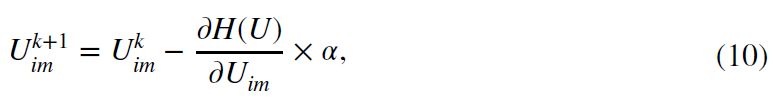
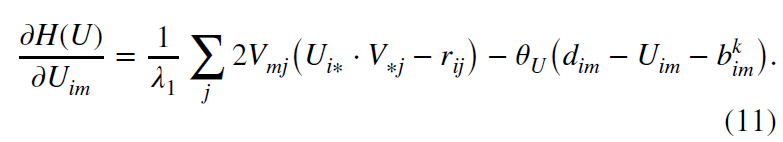
第二个式子可以通过萎缩(shrinkage)来求解
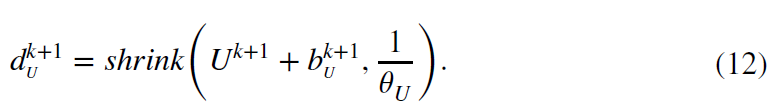
【啥叫萎缩,为何不引用参考资料,或者给出公式,这样让小白一头雾水】
然后求得U。固定U,分裂Bregman迭代方法用于求解J(V),即6式,用θV, dV, bV.替换θU, dU, bU
注意:
正则化参数λ1 ,λ2增大,user和item的特征矩阵,即U和V变得稀疏;
引入的θU , θV征控制在求解过程中的噪声比,可分别设置为β·λ1 ,β·λ2,
作者发现λ1, λ2∈ [10e-3, 10e-2], β∈[1, 2]可以取得好效果
总的方法如下:

【我试试问通信作者要点代码,或请求给点建议,拭目以待,敬候佳音】
另外有相关问题可以加入QQ群讨论,不设微信群
QQ群:868373192
语音图像视频深度-学习群
