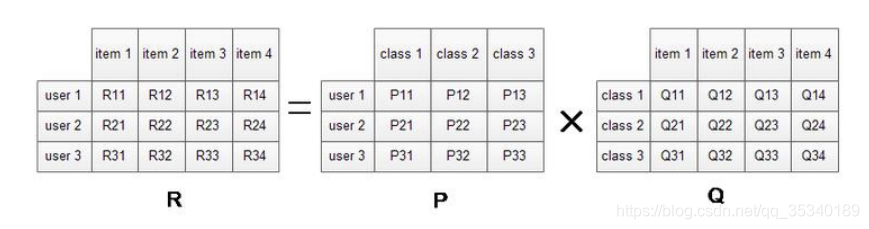
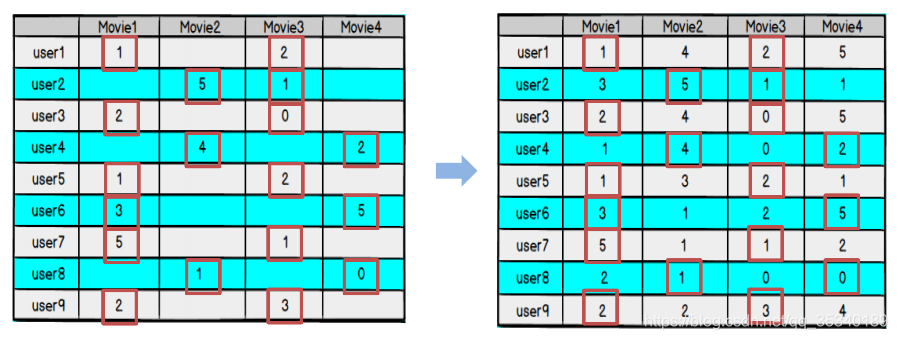
1、LFM(隐语义模型)梯度下降算法实现
import numpy as np
import pandas as pd
R = np.array([[4, 0, 2, 0, 1],
[0, 2, 3, 0, 0],
[1, 0, 2, 4, 0],
[5, 0, 0, 3, 1],
[0, 0, 1, 5, 1],
[0, 3, 2, 4, 1],])
"""
@输入参数:
R:M*N 的评分矩阵
K:隐特征向量维度
max_iter:最大迭代次数
alpha:步长
lambada:正则化系数
@%输出:
分解之后的 P,Q
P:初始化用户特征矩阵 M*K
Q:初始化物品特征矩阵 N*K
"""
K = 5
max_iter = 5000
alpha = 0.0002
lambada = 0.004
def LFM_grad_desc(R, K=2, max_iter=1000, alpha=0.0001, lambada=0.002):
M = len(R)
N = len(R[0])
P = np.random.rand(M, K)
Q = np.random.rand(N, K)
Q = Q.T
for step in range(max_iter):
for user in range(M):
for item in range(N):
if R[user][item] > 0:
eui = np.dot(P[user, :], Q[:, item]) - R[user][item]
for k in range(K):
P[user][k] = P[user][k] - alpha * (2 * eui * Q[k][item] + 2 * lambada * P[user][k])
Q[k][item] = Q[k][item] - alpha * (2 * eui * P[user][k] + 2 * lambada * Q[k][item])
predR = np.dot(P, Q)
cost = 0
for user in range(M):
for item in range(N):
if R[user][item] > 0:
cost += (np.dot(P[user, :], Q[:, item]) - R[user][item]) ** 2
for k in range(K):
cost += lambada * (P[user][k] ** 2 + Q[k][item] ** 2)
if cost < 0.0001:
break
return P, Q.T, cost
P, Q, cost = LFM_grad_desc(R, K, max_iter, alpha, lambada)
print(P)
print(Q)
print(cost)
print(R)
preR = P.dot(Q.T)
preR
[[ 0.77647888 0.63447284 0.80512534 0.55895106 0.96240798]
[ 1.32550446 0.88331475 0.62267974 0.02980579 0.7550383 ]
[ 1.03659297 0.93987934 0.72430912 -0.22346398 -0.4749907 ]
[ 0.77301525 0.49679317 0.57141146 0.693392 1.60075878]
[ 0.57612612 0.63976908 1.49718539 0.77990291 -0.03548665]
[ 0.50209193 0.92510101 0.89396375 0.69306917 1.07528177]]
[[ 0.85738419 0.73837126 0.69663037 1.09029338 1.75496549]
[ 0.07742206 0.60860856 1.0905473 0.54186881 0.92432084]
[ 1.25494006 0.96409017 -0.01302121 -0.32074926 0.63812769]
[ 1.2074824 1.52394386 1.92146259 0.53896068 -0.09707023]
[ 0.05525611 0.37630539 0.54292178 -0.10977234 0.30147462]]
0.5609786914291215
[[4 0 2 0 1]
[0 2 3 0 0]
[1 0 2 4 0]
[5 0 0 3 1]
[0 0 1 5 1]
[0 3 2 4 1]]
array([[3.99350543, 2.51674135, 2.01049581, 3.65933526, 0.94756504],
[3.58002164, 2.03332638, 2.97916634, 4.08587363, 0.96805775],
[1.01008047, 0.88203516, 1.96613029, 4.00139316, 0.68553548],
[4.99292856, 2.84069443, 2.24068429, 3.00675796, 0.94636437],
[2.79737849, 2.45652931, 1.04750538, 4.97120172, 0.98912751],
[4.37904712, 2.94626505, 1.97420123, 4.00294624, 1.10930686]])