目录
一、实验目的
1、掌握直接扫描法;
2、了解正则表达式与有限状态自动机;
3、了解如何使用FLEX等工具完成词法分析。
二、实验任务
1、要求在原理部分介绍直接扫描法及有限自动机;
2、代码实现直接扫描算法(必做);
3、使用FLEX等工具完成词法分析(附加)。
三、实验原理
1 词法分析的基本概念
词法分析也称为分词,此阶段编译器从左向右扫描源文件,将其字符流分割成一个个的词token。token就是源文件中不可再进一步分割的一串字符,类似于英语中单词,或汉语中的词。

图3.1 词法分析示意图
英语中的单词的数量是有限的,程序语言中可用的token的类别也是有限的,而且是非常少的。一般来说程序语言中的token有:常数(整数、小数、字符、字符串等),操作符(算术操作符、比较操作符、逻辑操作符),分隔符(逗号、分号、括号等),保留字,标识符(变量名、函数名、类名等)等。
词法分析器每扫描到一个完整的token后,立即新建一个TokenRecord,将此token的类型记录在此结构的type域中,将其字面值记录在value域中对应的子域内,并将此TokenRecord结构传递给下一阶段的语法分析模块使用,然后接着扫描下一个token。这样从语法分析模块的角度来看,源程序就变成了一个连续的token stream。
2 直接扫描法
直接扫描法的思路非常简单,每轮扫描,根据第一个字符判断属于哪种类型的token,然后采取不同的策略扫描出一个完整的token,再接着进行下一轮扫描。在TinyC中,若仅考虑一些简单的情况,按token的第一个字符,可以将所有类别的token分为以下7大类:
- A型单字符运算符
A型单字符运算符包括:+, -, *, /, %,这种 token 只有一个字符,若本轮扫描的第一个字符为上述字符,则立即返回此字符所代表的 token ,然后移到下一个字符开始下一轮扫描。
- B型单字符运算符和双字符运算符
B型单字符运算符包括:< > = ! ,双字符运算符包括:<=, >=, ==, != 。若本轮扫描的第一个字符为B型单字符运算符时,先查看下一个字符是否是“=”,如果是,则返回这两个字符代表的token,如果否,则返回这个字符代表的 token 。例如,如果扫描到“>”,则查看下一个字符是否是 “=” ,是则返回 T_GREATEEQUAL,否则返回T_GREATTHAN。
- 关键词和标识符
都是以字母或下划线开始、且只有字母、下划线或数字组成。若本轮扫描的第一个字符为字母或下划线时,则一直向后扫描,直到遇到第一个既不是字母、也不是下划线或数字的字符,此时一个完整的词就被扫描出来了,然后,查看这个词是不是为关键字,如果是,则返回关键字代表的token,如果不是,则返回T_IDENTIFIER 以及这个词的字面值。
- 整数常量
整数常量以数字开始,若本轮扫描的第一个字符为数字,则一直向后扫描,直到遇到第一个非数字字符,然后返回T_INTEGERCONSTANT和这个数字。
- 字符串常量
以双引号开始和结束,若本轮扫描的第一个字符为双引号,则一直向后扫描,直到遇到第一个双引号,然后返回T_STRINGCONSTANT和这个字符串。
- 空白
若本轮扫描的第一个字符为为空格,则跳过此字符。
- 注释
注释仅考虑以#开始的情况,若本轮扫描的第一个字符为 #,则直接跳过此行字符流。
3 有限状态自动机
有限状态自动机(finate automaton)是用来判断字符串(句子)是否和正则表达式匹配的假想机器,它有一个字母表Σ、一个状态集合S,一个转换函数T,当它处于某个状态时,若它读入了一个字符(必须是字母表里的字符),则会根据当前状态和读入的字符自动转换到另一个状态,它有一个初始状态,还有一些所谓的接受状态。
它的工作过程如下:首先自动机处于初始状态,之后它开始读入字符串,每读入一个字符,它都根据当前状态和读入字符转换到下一状态,直到字符串结束,若此时自动机处于其接受状态,则表示该字符串被此自动机接受。如下图:
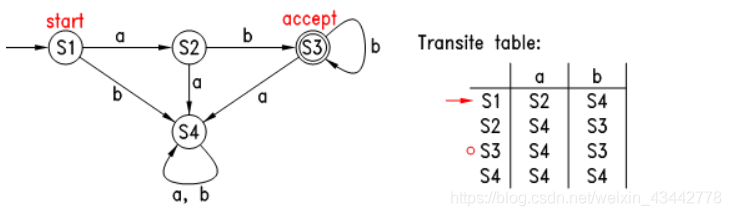
图3.2 典型的有限状态自动机
上图中圆圈表示各种状态,各箭头及签头上的字符表示状态的转换表,自动机只有一个初始状态,用一个不含字符的箭头指向此状态,可以认为此为自动机的入口,自动机可以有一个或多个接受状态,用双圆圈表示。上图中的自动机的字母表为{a,b},初始状态为S1,当它读入一个a后,就转到状态S2,若读入的是b,则转到S4,然后一个接一个字符的转换其状态,若字符结束时自动机处在其接受状态,则表示此字符串被其接受。经过观察可知,此图中的自动机能接受的字符串为“ab”、“abb”、“abbb”等,即此自动机与正则表达式ab+是等价的。
任何一个正则表达式都有一个等价的有限状态自动机,任何一个有限状态自动机也有一个等价的正则表达式。同时,有限状态自动机只要求对字符串扫描一遍就可以,判断速度很快。
总而言之,正则表达式的匹配判断可以通过构造有限状态自动机来进行,构造有限状态自动机的大体思路:先构造基本的自动机,再根据正则表达式的结构搭建出复杂的自动机。然而,构造有限状态自动机的具体算法十分复杂,可以借用工具flex 来进行基于正则匹配的词法分析。
4 flex简介
flex是一个快速词法分析生成器,它可以将用户用正则表达式写的分词匹配模式构造成一个有限状态自动机(一个C函数),目前很多编译器都采用它来生成词法分析器。
四、实验过程
1 直接扫描法
直接扫描法思路简单,代码量非常少,scan1.py不过100行代码。但缺点是速度慢,对标识符类型的token需要进行至少2次扫描,且需进行字符串查找和比较。而且不容易扩展,只适用于语法简单的语言。
具体代码详见附录1.
2 用flex词法分析生成器进行词法分析
本部分实现将输入的连续数字串替换成指定的字符,此处全部替换为字符‘?’,具体的步骤如下:
- 安装flex;
- 新建hide-digits.l文件,具体内容见附录2;
- 运行此文件:flex hide-digits.l;
- 此时目录下多了一个 “lex.yy.c” 文件,将C文件编译并运行;
- 在终端敲入任意键并回车,以敲入‘#’后程序退出。
五、实验结果
1 直接扫描法
运行结果见图5.1,分析了本程序代码的标识符类型。

图5.1 直接扫描法运行结果
2 flex词法分析生成器进行词法分析
*注:加粗字为输出结果,白体字为输入字符串。
| Abcedfs Abcedfs 12456789 ? Assdfasa1564 Assdfasa? Adsfa123asdfaf56 Adsfa?asdfaf? ... # |
由以上结果可知,此程序可以将输入的字符串中连续的数字字符串转换为‘?’;说明flex词法分析生成器效率较高,因为我们用较少的代码实现了词法分析,与直接扫描法相比,大大节约了编写代码的精力。
参考资料
- 词法分析:https://pandolia.net/tinyc/ch7_lexical_basic.html
- 用 flex 做词法分析:https://pandolia.net/tinyc/ch8_flex.html
附录
1 直接扫描法代码
| # -*- coding: utf-8 -*-
single_char_operators_typeA = { ";", ",", "(", ")", "{", "}", "[", "]", "/", "+", "-", "*", "%", ".", ":" }
single_char_operators_typeB = { "<", ">", "=", "!" }
double_char_operators = { ">=", "<=", "==", "~=" }
reservedWords = { "class", "for", "while", "if", "else", "return", "break", "True", "False", "raise", "pass" "in", "continue", "elif", "yield", "not", "def" }
class Token: def __init__(self, _type, _val = None): if _val is None: self.type = "T_" + _type; self.val = _type; else: self.type, self.val = _type, _val
def __str__(self): return "%-20s%s" % (self.type, self.val)
class NoneTerminateQuoteError(Exception): pass
def isWhiteSpace(ch): return ch in " \t\r\a\n"
def isDigit(ch): return ch in "0123456789"
def isLetter(ch): return ch in "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
def scan(s): n, i = len(s), 0 while i < n: ch, i = s[i], i + 1
if isWhiteSpace(ch): continue
if ch == "#": return
if ch in single_char_operators_typeA: yield Token(ch) elif ch in single_char_operators_typeB: if i < n and s[i] == "=": yield Token(ch + "=") else: yield Token(ch) elif isLetter(ch) or ch == "_": begin = i - 1 while i < n and (isLetter(s[i]) or isDigit(s[i]) or s[i] == "_"): i += 1 word = s[begin:i] if word in reservedWords: yield Token(word) else: yield Token("T_identifier", word) elif isDigit(ch): begin = i - 1 aDot = False while i < n: if s[i] == ".": if aDot: raise Exception("Too many dot in a number!\n\tline:"+line) aDot = True elif not isDigit(s[i]): break i += 1 yield Token("T_double" if aDot else "T_integer", s[begin:i]) elif ord(ch) == 34: # 34 means '"' begin = i while i < n and ord(s[i]) != 34: i += 1 if i == n: raise Exception("Non-terminated string quote!\n\tline:"+line) yield Token("T_string", chr(34) + s[begin:i] + chr(34)) i += 1 else: raise Exception("Unknown symbol!\n\tline:"+line+"\n\tchar:"+ch) if __name__ == "__main__": print( "%-20s%s" % ("TOKEN TYPE", "TOKEN VALUE")) print ("-" * 50) for line in open("scan1.py"): for token in scan(line): print (token) |
2 hide-digits.l文件
| %% [0-9]+ printf("?"); # return 0; . ECHO; %%
int main(int argc, char* argv[]) { yylex(); return 0; }
int yywrap() { return 1; } |