论文地址:http://web.cs.ucla.edu/~zhou.ren/ECCV2020_poseTracking.pdf
论文总结
本文实际上就是在top-down结构的基础下,在姿态检测器的backbone上增加了两个模块:时序关键点匹配模块(用以联系两帧之间的实例,维系ID的存在)和时序校正模块(用多帧的姿态检测器产生的heatmap,来加权平均当前的heatmap,从而避免错误的局部最小值响应过大的问题)。两个模块都整合到了单人的姿态检测网络中,训练的时候分两步训练,先训练正常的backbone和姿态检测模块,固定权重参数后,再训练两个新设计的模块。
两个新的模块,实际上就是改善视频中帧之间的pose联系以及当前帧的pose估计。时序关键点匹配模块,通过网络模块学习两帧之间对应关键点特征向量的相似度,用于跨帧匹配关键点;时序关键点校正模块,用于校正单个个体,用它相邻时间窗口的帧的相关姿态作为时序上下文信息。
论文介绍
本文的展示数据集是PoseTrack,即其目标就是在视频中的姿态识别。
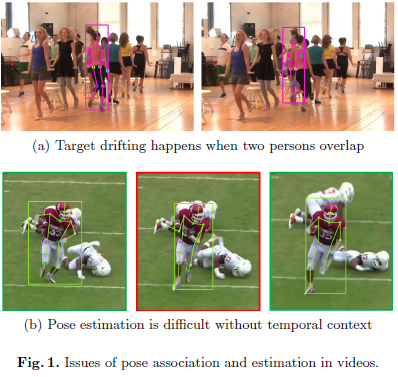
一般的相似度度量,有两种方式:基于IoU的边框相似度度量和基于姿态关键点的OKS距离度量。在这两种度量下,都会存在多人的相互对pose跨帧联系带来问题。遮挡、运动模糊、他人干扰和复杂背景都会带来定位问题的歧义。如下图1(a),由于两个人重叠可能就会导致对象目标的平移;如图1(b),由于遮挡问题,很难定位右手肘和右手腕。时序信息可以有效地解决这问题。
基于IoU的相似度度量和基于OKS的相似度度量,都是基于位置或几何形状的度量,是与实例无关的。本文提出的相似度度量,是在实例的层次上考虑的,可以从不同的人体实例中区分关键点,通过关键点相似度的聚合,来计算相邻两帧中两个pose之间的相似度。
所提出的方法
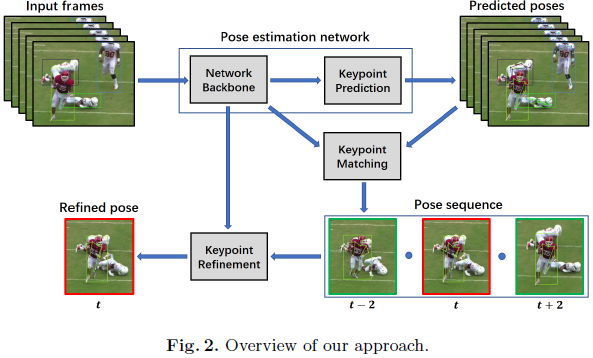
本文所提出的结构的运行流程如下图所示:由姿态检测模块进行关键点的预测,然后通过关键点匹配,用以联系相邻帧的姿态,再利用时序姿态检测特征去校正某帧的姿态。
单帧姿态检测
关键点预测模块,由 3 3 3个deconv层加 1 1 1个 1 ∗ 1 1*1 1∗1conv组成。设定 M k M^k Mk是第 k k k个关键点对应的heatmap,则对应的关键点位置 l k ∗ = a r g m a x l M k ( l ) l_k^*=\mathop{arg}\mathop{max}\limits_{l}M^k(l) lk∗=arglmaxMk(l) 为对应的响应。
设定 P i ˉ \bar{P_i} Piˉ是第 i i i个人体实例, Q i ˉ = { ( l ˉ i k , v ˉ i k ) ∣ 1 ≤ k ≤ K } \bar{Q_i}=\{(\bar{l}_i^k, \bar{v}_i^k)|1\leq k \leq K\} Qiˉ={ (lˉik,vˉik)∣1≤k≤K}是对应 P i ˉ \bar{P_i} Piˉ的标注, l ˉ i \bar{l}_i lˉi是位置坐标, v ˉ i ∈ { 0 , 1 } \bar{v}_i\in\{0,1\} vˉi∈{ 0,1}指示关键点的可见性,设定heatmap的高斯核大小 σ = 3 \sigma=3 σ=3,N个人,每个人有K个关键点。损失函数为: L p o s e = 1 N K ∑ i = 1 N ∑ k = 1 K v ˉ i k ∥ M i k − M ˉ i k ∥ 2 2 L_{pose}=\frac1{NK}\sum_{i=1}^N\sum_{k=1}^K\bar{v}_i^k\|M_i^k-\bar{M}_i^k\|_2^2 Lpose=NK1i=1∑Nk=1∑Kvˉik∥Mik−Mˉik∥22
时序关键点匹配和pose tracking
跨帧匹配 ,一般都使用最大二部匹配来联系ID,使用 W i , j t , t − 1 W_{i,j}^{t,{t-1}} Wi,jt,t−1来衡量两帧之间实例 i i i与实例 j j j的相似度,使用 z i , j t , t − 1 ∈ { 0 , 1 } z_{i,j}^{t,{t-1}}\in \{0,1\} zi,jt,t−1∈{ 0,1}表示二者是否匹配,其对应的两帧匹配解 z ∗ z^* z∗可由下列公式所得。
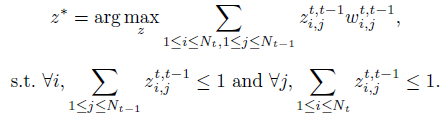
常见的相似度度量,是基于IoU和OKS。IoU可能存在的问题,如下图第一行所示,两个相邻的实例会造成ID联系的错误;OKS可能存在的问题,如下图第二行所示,由于人体的运动,可能相似运动的姿态会联系到错误的ID。也可以从图中看出,本文提出的新的度量方式,可以有效解决这些问题。

本文提出了新的相似度度量指标。在网络设计上,关键点匹配模块,在Backbone上加了一层来提取关键点的特征向量,来衡量两图中实例是否为同一个人。相似度度量公式在下面展示。 W i , j t , t − 1 = I ( I o U ( P t , i , P t − 1 , i ) ≥ 0.1 ) ∑ k = 1 G k ( f t , i k , f t − 1 , j k ) W_{i,j}^{t,{t-1}}=I(IoU(P_{t,i}, P_{ {t-1},i})\geq 0.1)\sum_{k=1}G_k(f_{t,i}^k,f_{t-1,j}^k) Wi,jt,t−1=I(IoU(Pt,i,Pt−1,i)≥0.1)k=1∑Gk(ft,ik,ft−1,jk)其中, G k G_k Gk是衡量特征相似性的函数; I ( I o U ( P t , i , P t − 1 , i ) ≥ 0.1 ) I(IoU(P_{t,i}, P_{ {t-1},i})\geq 0.1) I(IoU(Pt,i,Pt−1,i)≥0.1)是约束条件,来避免太远的实例进行匹配,只有两帧中IoU大于0.1的实例才进行匹配。可以从上面的姿态跟踪图右边所示,本文的度量方式可以有效解决一些问题。
时序关键点匹配模块,由 4 4 4个基础blocks和 k k k个分类器组成,每个block有 3 3 3个 3 ∗ 3 3*3 3∗3conv,每个conv输出 256 256 256个channel和一个deconv层上采样 2 2 2倍。
视频 P t , i P_{t,i} Pt,i表示第 t t t帧的第 i i i个实例, P t , i P_{t,i} Pt,i的第 k k k个关键点 p t , i k p_{t,i}^k pt,ik, F t , y 是 实 例 F_{t,y}是实例 Ft,y是实例P_{t,i}的feature maps , , , F t , i ( p t , i k ) F_{t,i}(p_{t,i}^k) Ft,i(pt,ik)是 F t , i F_{t,i} Ft,i在点 p t , i k p_{t,i}^k pt,ik上的特征向量。 G k G_k Gk将两帧中对应关键点的特征向量concat起来,输出一个相似概率(是否属于同一个人)。每个分类器 G k G_k Gk由 3 3 3个全连接层加 s o f t m a x softmax softmax实现。隐藏层的个数,分别为 256 , 256 , 2 256,256,2 256,256,2。
关键点匹配模块,在训练的时候,用一些人实例组一起训练。如图4所示,取右手肘的样本对,蓝色是真值位置,只有真值点的样本对的label为 1 1 1(图中红线),其余为 0 0 0。保持正实例位置对和错误位置对的数量比例为 1 : 4 1:4 1:4。使用交叉熵损失函数训练 K K K个分类器。

用时序信息进行姿态校正
由于有遮挡、多人相互干扰,运动模糊等问题,会对单人单帧姿态检测带来巨大挑战。如下图所示, t t t帧时的右手肘的真值位置响应值低,但 t − 1 t-1 t−1和 t + 1 t+1 t+1帧的右手肘都正确预测,利用上下帧的有用线索来纠正帧 t t t中的预测。
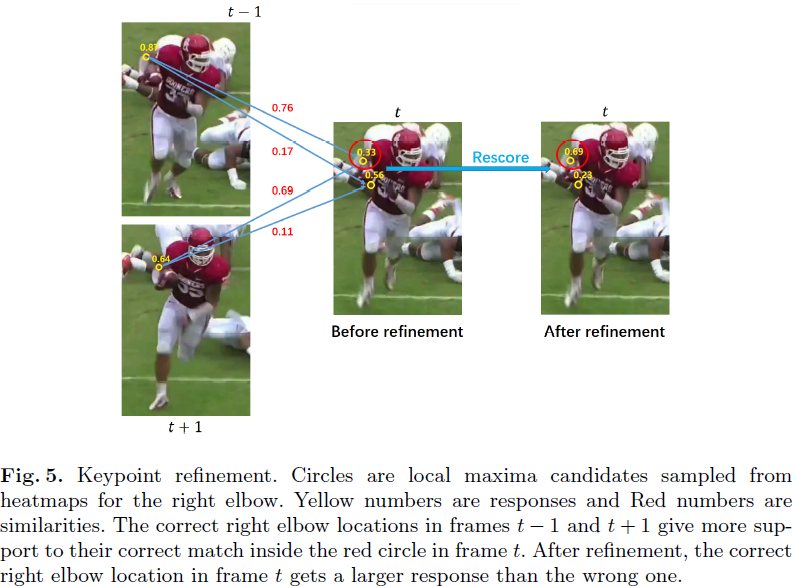
在运用时,对于实例 P t , i P_{t,i} Pt,i,在时间窗口的帧中找到对应该实例的实例。具体来说,有向前和向后两个方向搜索。对于反向搜索路径,从帧 t t t的实例 P t , i P_{t,i} Pt,i开始搜,找到前一帧中最大相似的实例(用前面的关键点匹配模块)。然后以帧 t − 1 t-1 t−1选中的实例作为参考,得到 t − 2 t-2 t−2帧中的最佳匹配人体实例,直到反向搜索路径结束。对于前向搜索路径,也是如此。然后将两条路径合并成一条路径。这条路径上的所有人体检测用于校正帧 t t t中对应实例的pose。
Q = { P t ′ , i ∣ t − τ ≤ t ′ ≤ t + τ } Q=\{P_{t',i}|t-\tau\leq t'\leq t+\tau\} Q={ Pt′,i∣t−τ≤t′≤t+τ}是某个实例在时间窗口中的姿态集合。 M t , i k M_{t,i}^k Mt,ik是第 t t t帧实例 i i i的第 k k k个heatmap。 ζ t , i k \zeta_{t,i}^k ζt,ik是第 k k k个关键点的heatmap中的局部最大候选集。
关键点校正模块和关键点预测模块有一样的结构,也是部署在backbone上的,只是在不同的路径。将 M t , i k M_{t,i}^k Mt,ik的局部最大候选集中稀疏采样 n n n个。然后校正他们的响应值。这里设置 n = 16 n=16 n=16,作者通过实验表现这个设置充分覆盖大多数的正确值。
将时间窗口姿态集合 Q Q Q中对应k的关键点位置作为 ζ t , i k \zeta_{t,i}^k ζt,ik的上下文。标记 l ^ t ′ , i k \hat{l}_{t',i}^k l^t′,ik作为heatmap M t ′ , i k M_{t',i}^k Mt′,ik中的最高响应。取校正第 k k k个heatmap中的最大相应 l l l。作者聚合(这里是相加,而前面的时序关键点匹配模块中的是concat)特征向量 H t , i ( l ) H_{t,i}(l) Ht,i(l)和特征向量 H t ′ , i ( l ^ t ′ , i k ) H_{t',i}(\hat{l}_{t',i}^k) Ht′,i(l^t′,ik)在对应窗的不同帧中,得到的新的 H ˉ t , i ( l ) \bar{H}_{t,i}(l) Hˉt,i(l)取代 H t , i ( l ) H_{t,i}(l) Ht,i(l)作为输入求解新的响应值。【所以候选集 l l l都选出来,通过计算得到新的表示】。聚合公式如下面所示。 H t , i ˉ ( l ) = H t , i ( l ) + ∑ t ′ ∈ [ t − τ , t + τ ] ∖ t H t ′ , i ( l ^ t ′ , i k ) W ( l , l ^ t ′ , t k ) 2 τ + 1 \bar{H_{t,i}}(l)=\frac{ {H_{t,i}(l)+\sum_{t'\in[t-\tau,t+\tau]\setminus t}}H_{t',i}(\hat{l}_{t',i}^k)W(l,\hat{l}_{t',t}^k)}{2\tau+1} Ht,iˉ(l)=2τ+1Ht,i(l)+∑t′∈[t−τ,t+τ]∖tHt′,i(l^t′,ik)W(l,l^t′,tk)
时序关键点校正模块的损失函数,也是和姿态检测模块的损失函数所示,只是在反向传播时,只有稀疏的候选位置集被用来更新损失。 L p o s e = 1 N K ∑ i = 1 N ∑ k = 1 K v ˉ i k ∥ M i k − M ˉ i k ∥ 2 2 L_{pose}=\frac1{NK}\sum_{i=1}^N\sum_{k=1}^K\bar{v}_i^k\|M_i^k-\bar{M}_i^k\|_2^2 Lpose=NK1i=1∑Nk=1∑Kvˉik∥Mik−Mˉik∥22
训练
训练采用两阶段的训练策略。先训练姿态检测模型,backbone和姿态检测模块。再用这个模型初始化本文的网络。即固定住backbone和关键点预测模块的权重参数,再进行模型优化。使用的优化器为SGD。
论文实验
论文中实验了两组backbone的实验,ResNet-152和HRNet。对于单帧模型的训练,迭代了 20 20 20个epoch,初始化学习率为 0.001 0.001 0.001,在第 10 10 10个和第 15 15 15个epoch分别减少 10 10 10倍。为训练关键点匹配模块和关键点校正模块,将时间窗口的长度设置为 11 11 11,即 τ = 5 \tau=5 τ=5。新模型训练 9 9 9个epoch。初始学习率设为 0.0001 0.0001 0.0001,在第 7 7 7个epoch减少 10 10 10倍。
使用Faster R-CNN和FPN,以及deformable convolutional network(DCN)来训练人体检测器。人体检测器也是在COCO余弦训练,然后在PoseTrack2017和PoseTrack2018中进行finetune。
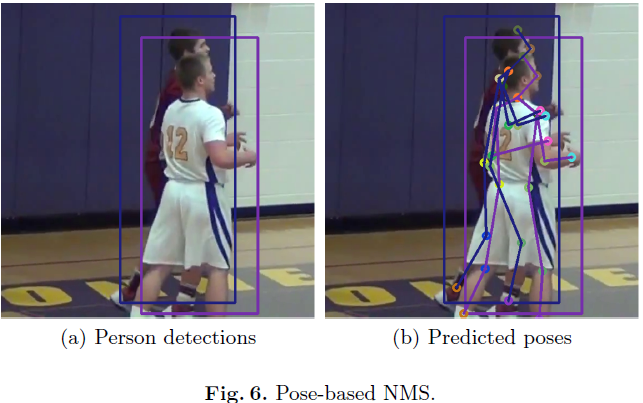
一般在人体检测器之后,会采用NMS减少边框。但对于多人的场景,人体遮挡会造成NMS的问题,如下图6(a)所示。也由于人体检测器的检测结果会影响后续的姿态检测、跟踪和校正,所以作者采取了基于pose的NMS(pNMS)的变种去更好的解决人体检测中的人体遮挡问题,如下图6(b)所示。对于两人的检测,作者通过计算每个关键点对的距离来比较他们的姿态。如果距离是在阈值内的,则认为这两个关键点是相同的。然后,作者计算在两个姿态中有多少个关键点对是重合的。如果百分比大于 0.5 0.5 0.5,则确定两个人员检测对应同一个人。
与其他最先进的多人姿态检测和跟踪方法进行比较,前六种方法是bottom-up方法,后三种方法是top-down方法。
表1展示单帧姿态检测在PoseTrack的结果。PoseWraper利用了未标记的帧进行训练,而且不通过阈值来过滤关键点进行评估。本文的方法比最好的top-down模型FlowTrack效果好 2.6 % 2.6\% 2.6%,比最好的bottom-up模型ST-Embed好 2.5 % 2.5\% 2.5%。
表2展示了多人姿态检测跟踪的结果。本文的方法也达到了最先进的效果,比FlowTrack提高了 6.6 % 6.6\% 6.6%。表明所提出的关键点匹配模块和关键点校正模块对于改进top-down的人体姿态估计和跟踪是有效的。对比最好的bottom-up方法St-Embed,本文在MOTA方面的效果提升了 0.4 % 0.4\% 0.4%。这个改进并不大,因为ST-Embed也采用了实例感知的相似度度量来进行姿态跟踪。不同之处在于ST-Embed同时使用了人类级和时间级实例嵌入,而本文的相似度度量只使用关键点级别的嵌入。
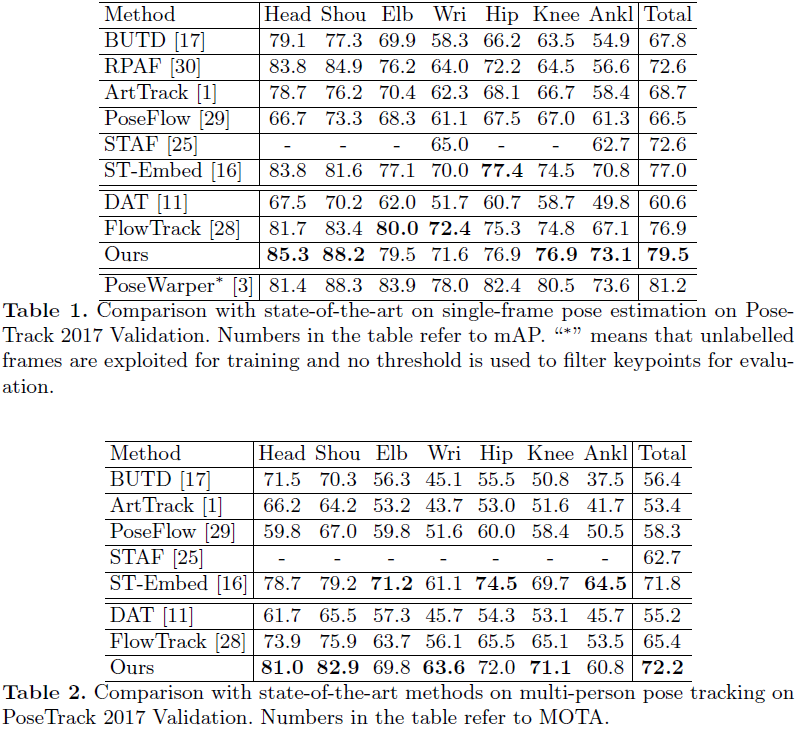
表3显示了所提出方法的消融学习实验,与该方法几个变体进行比较。M1是FlowTrack的复现,只是有两点不同:(1)不适用flow传播去增强检测结果;(2)使用ResNet101替代ResNet152去训练检测器。M1使用了传统的NMS。M2使用了pNMS
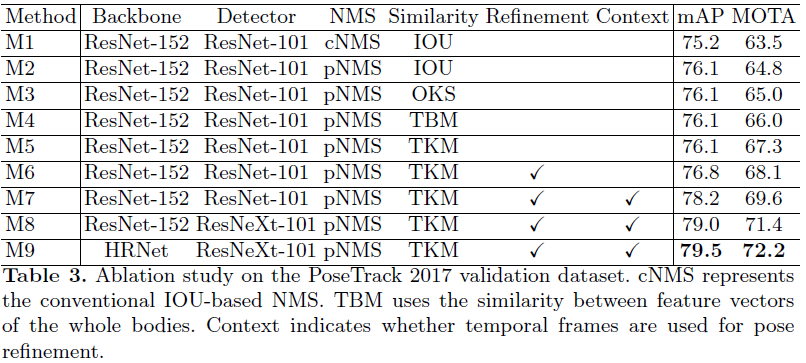
表4展示了在PoseTrack 2018的消融学习性能对比。