Co-Learning Feature Fusion Maps From PET-CT Images of Lung Cancer
使用新的监督卷积神经网络(CNN)改进多模态PET-CT中补充信息的融合,该网络可以学习用于多模态医学图像分析的有用补充信息。首先对形态特征进行编码,然后使用它们得出空间变化的融合图,以量化每种模式在不同空间位置的相对重要性。然后将这些融合图与模态专用特征图相乘,以获得不同位置处的互补多模态信息表示,然后可将其用于图像分析。
综述
医学成像方式的范围很广,但从本质上讲,它们提供了有关结构和生理病理的解剖和功能信息。PET-CT 结合了 PET 的敏感性以从 CT 检测异常功能区域和解剖定位。使用 PET,疾病部位通常显示出比正常结构更大的 FDG 摄取(葡萄糖代谢)。 然而,由于与CT和MR成像相比固有的PET分辨率较低,肿瘤异质性和部分体积效应,无法准确确定疾病在特定结构内的空间范围。 CT 提供了 PET 中 FDG 摄取异常的部位的解剖学定位,因此提高了图像解释的准确性。
PET-CT 在癌症护理中的作用引起了对检测、分类和检索 PET-CT 图像的方法的广泛研究。这些方法可以分为:(i)分别处理每个模态,然后组合特定模态的特征,以及(ii)组合或融合来自每个模态的互补特征。前者在需要同时考量解剖和功能信息时具有很大的局限性。相比之下,融合来自两种模式的信息的方法通常使用关于不同模式的特征的先验知识,以“优先”使用来自两种模式之一的信息以完成不同的任务,在不同的成像模态标识相同兴趣区域(ROI)的不同属性且没有一个模态捕获整个ROI的情况下,融合特别必要。(作者后面列举了一些用传统方法进行多模融合的例子)
当前在一般(非医学)领域中的图像融合策略是根据不同图像数据的局部视觉特征得出空间变化的融合权重。 诸如像素差异、对比度和颜色饱和度之类的功能可用于得出图像内不同关注区域(ROI)的任务特定融合率,这样就可以增强针对不同任务的来自不同图像数据的特定信息。作者认为,应该从单个图像的基本视觉特征中学习对多模态图像数据进行适当的空间变化融合的推导,因为这将使每个模态中的补充信息更好地整合在一起。
最初使用CNN方法进行医学图像分析研究,“转移”了从非医学领域学到的特征,并将其调整为特定的医学任务,迁移学习方法也已经用于多模式图像分类。针对多种多模态医学图像分析应用的 CNN 被专门训练出来,研究重点之一是不同序列的脑部MR图像,这些图像通常被视为多模态图像,原因是不同的MR图像显示出相同解剖结构的不同方面。(作者后面列举了一些用深度学习方法处理多模图像的例子)通常,CNN已作为特征提取器和分类器应用于多模态图像数据,而不考虑依赖于输入数据的预融合或每种输入模态的独立处理,如何组合每种模态的特征。最近基于基于CNN的PET-CT肺肿瘤分割的研究是从围绕肿瘤周围的图像块进行学习,并且没有考虑不同情况下发生的肿瘤的PET和CT图像特征的变化解剖位置。
作者的目标是改进多模态图像中补充信息的融合,以进行自动医学图像分析。特别是,作者专注于描述跨多个解剖位置的疾病的图像数据,提出了一个新的 CNN,该 CNN 学会以空间变化的方式融合来自 PET-CT 图像的互补解剖和功能数据。 CNN 的新颖之处在于它能够生成融合图,从而明确量化每种模态中特征的融合权重。这与使用多通道输入的 CNN 形成了鲜明对比,在 CNN 中,模态被隐式融合,或特定于模态的编码器分支,其中模态-特定功能将在稍后阶段连接。作者的共同学习 CNN 旨在作为整合 PET 和 CT 信息的通用方法,其组件可以针对许多不同的医学图像分析任务(例如可视化,分类和分割)进行利用和优化。
方法
作者的 CNN 包含四个主要组件:两个编码器(每个模态一个),一个共同学习和融合组件以及一个重构组件。这两个编码器的目的是得出与每个特定图像模态最相关的图像特征。 每个编码器的输入是轴向 2D 图像切片。 共同学习组件使用编码器产生的模态特定特征来导出空间变化的融合图,以加权不同位置的模态特定特征。 最后,重构组件将跨多个尺度的模态特定融合特征进行整合,以生成最终的预测图。网络结构示意图如下:

文章的创新点应该主要在中间的共同学习和融合组件。共同学习组件由两部分组成:(i)一个学习单元,它是一个 CNN,可以学习得出空间变化的融合图,以及(ii)融合操作,使用该融合图对不同的特征进行优先级排序。
共同学习单元的输入是两个特征图 ˆ FCT和 ˆ FPET(每个来自一个模态专用编码器的块),每个特征图的大小为 w×h×c,具有 w 宽度,h 高度和 c 个通道。 这些特征图被堆叠以形成ˆ Xmulti,一个 w×h×m×c 的张量,其中 m = 2 个模态数。 然后将 ˆ Xmulti 的通道与大小为 k×k×m 的可学习 3D 内核 Wmulti 的通道进行卷积, k 是卷积核的大小。作者的意图是,与 PET-CT 像素混合中的整体融合率相比,共同学习的融合图控制着从每个位置的每个模态提供给信息的重要性级别。图2 给出了多模态共同学习单元的功能的概念性示例:

融合操作(如图3所示)根据多模态融合图中的值(系数)整合了特定于模态的特征图,如下所示:

实验
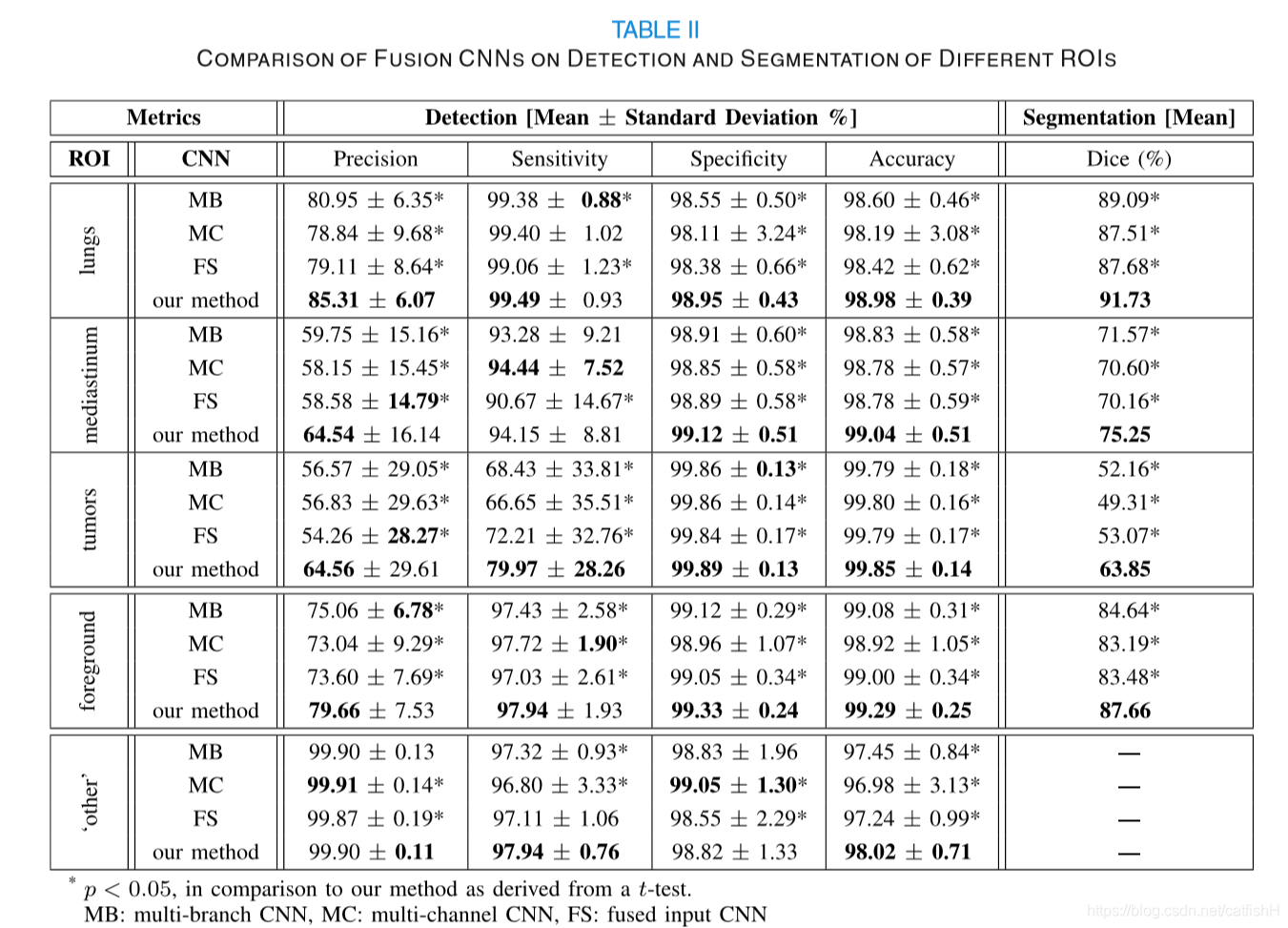
为了提高鲁棒性并减少偏差,作者使用了 5 折交叉验证评估方法。 对于每一折,作者的方法和所有基线使用相同的训练和测试数据集。作者在两种模式中都使用了灰度输入,这在基线融合策略和其他多模式 CNN 研究中很常见。对于所有与基线方法进行的实验比较,作者使用两次样本 t 检验计算了 p 值。使用了两个主要的评估任务来证明方法的有效性:肺癌 PET-CT 图像中 ROI 的检测和分割。实验设计如下:
-
将融合方法与几种融合基线策略进行了比较。 为了限制实验中可变变量的数量,对于所有融合基线,使用了与作者方法中相似的架构,用文献中的融合策略替代了共同学习组件。 基线是:
- 多分支(MB)CNN,其实施融合策略,其中分别对每个模态进行处理,并对每个模态的输出进行合并;
- 多通道(MC)输入CNN,实现一种融合策略,在该融合策略中,每种模式都被视为单个输入的不同通道;
- 融合(FS)输入CNN,实施一种策略,其中输入是已经通过像素混合融合的PET-CT图像。
-
将共同学习的 CNN 与 PET-CT 肺肿瘤分割的两种最新深度学习方法进行了比较:
- 肿瘤共分割方法,使用了公开可用的源代码。基线分别对CT和PET图像进行了分割,可以将其合并以进行PET-CT分割;
- 一种可变肿瘤分割方法,源代码不是公开可用的,作者根据本文提供的详细信息实现了基线。 该基线使用 U-Net 粗略确定 CT 上的肿瘤 ROI,然后使用 PET 数据和模糊变异模型对其进行完善。
-
对融合效果进行评估。提取了由共同学习单元产生的特征融合图,以检查针对肺部肿瘤的图像产生的融合率。 进行该实验是为了确定自动得出的融合率是否符合公认的期望。
总结
感觉期刊文章比会议文章在写作上要规范好多,前面的文献综述部分,以及对比实验和分析也更详尽。
文章主要思路是用一个类似注意力的方法,自动生成一个两个模态各个通道重要程度的融合图,将它作为加权实施在分别处理后的两个模态的特征图上,同时也用到了多尺度以及跳跃连接的方法。
