出处 :2019ICIP
作者: 
摘要 : 提出一个检测人脸图像拼接的深度网络。把输入图像转换为illumination map (IM),然后比较面部区域的 pairs 来检测拼接篡改。先在外部的训练集上训练孪生网络来区分来自相似或不同光照环境illumination environments (IEs)的pairs。训练好后,一支网络用来提取测试图像的特征。拼接一对特征,SVM进行分类。本文方法的优点是能够学习不同IE下有区分力的特征
数据集 DSO-1 [6]:包含100个真实的和100个拼接的高分辨率图像,其中包含人类群体肖像
DSI-1 [6]:DSI-1数据集包含25张来自互联网的真实图像和25张拼接图像
实验环境 Python 3.6,Keras 2.2.4 [16], Matlab 2017b on a Tesla K20c GPU with 5 GB RAM.
metrics detection accuracies
2 method
2.1 Image Representation and Face Extraction
输入图像分割成相似的区域(superpixels),从每个超像素估计光照颜色,然后recolor 超像素,创建IM。(IM是中间表示,压缩表层信息,增强光照颜色信息)IM 中的拼接部分更加明显,手工提取IM里的面部部分
有两种光照评估方法
-
基于统计的方法[10] [11],在假设图像像素分布的前提下,从图像中估计光源的颜色。
-
基于物理的方法[12] [13] [14]
-
本文使用 generalized gray edge (GGE) method [10],这是基于这样一种假设,即在白色光源的照射下,场景中的平均反射率差是achromatic(消色差的),光照颜色e计算如下
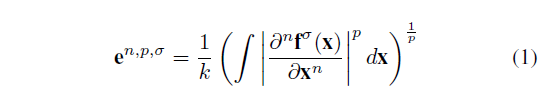
\(f^\sigma\) 是图像X位置使用(标准差\(\sigma\))高斯平滑后的像素密度,\(\frac{\partial}{\partial_x}\) 是偏导数,|·|是范数,n 是阶数,k 是常数项,p 是Minkowskin norm P范数
-
本文使用 the modified inverse-intensity chromaticity (IIC) [5],该方法基于Tan等人提出的原始IIC方法[14],其中对光源的估计如下:
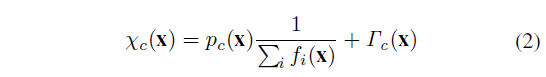
\(f_c(x)\) 是每个滤色器\(c\in{R,G,B}\)在x像素位置的传感器响应,\(\chi_c(x)\) 是图像的色度,\(\Gamma_c(x)\) 是镜面或光源的色度,\(p_c(x)\) 是依赖于曲面几何的参数,扩散色度和高光色度
2.2 Face-IM Pair Classification for Splicing Detection
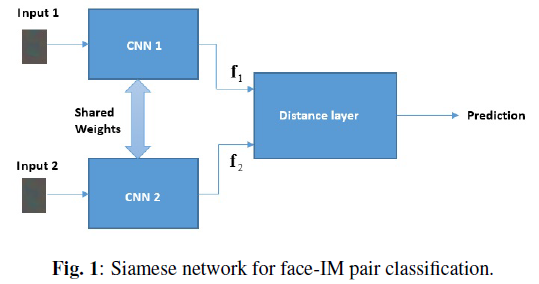
把 pairs of face-IMs 输入 siamese network(参数共享),预测 the class-label of the pairs。 使用 SVM 进行分类。authentic pair 是来自同一 IE 的 face-IMs pair(有相同的特征),spliced pair 指来自不同 IE 的 pair。
如果一副图像有N个face,那么有N(N-1)个 face pairs,如果至少有一个脸对是拼接的吗,那这副图像是拼接的。
2.2.1 Siamese Network for Learning Features
使用[9]的孪生网络,共享权重保证从两个输入中获得相同的特征集。
CNN 计算出输入对的特征 \(f_1\)\(f_2\),distance layer 计算 \(f_1\)、\(f_2\)的 L1 距离,然后全连接 sigmoid neuron layer 预测输入对的类别,预测p计算如下 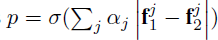 ,\(\alpha_j\)是全连接层的可调参数,表示距离的每个分量的重要性。使用 the cross-entropy loss。
,\(\alpha_j\)是全连接层的可调参数,表示距离的每个分量的重要性。使用 the cross-entropy loss。
图2是CNN的结构,

由于没有现成的人脸拼接数据集,我们在真实图像上人工生成一些拼接对。然后创建IMs,使用真实对和拼接对训练。经过训练,其中一个孪生CNNs被用来从真实拼接图像中出现的面部IMs中提取特征。我们没有利用整个孪生网络来对真正的拼接脸进行分类。
2.2.2 Splicing Detection
从图像中提取特征向量后,对其进行两两分类,以检测拼接的真伪。
如果在一个输入图像中有N个face,我们通过连接pair的每个face的特征来创建N(N 1)/2个联合特征。使用这些联合特征训练SVM,然后对测试图像中的face-IMs pairs 进行分类。
3. experiments
3.1 Training the siamese network
收集了6660个图像,每幅图像里有2-10个人,提取面部部分。真实pais是从同一个图像创建的脸对,拼接pair是从不同的图像随机选择的面部对。创建了57024个真实对,1103160个拼接对
使用了三种表达来训练网络 GGE method、IIC method、原始图像。
3.2 Splicing Detection
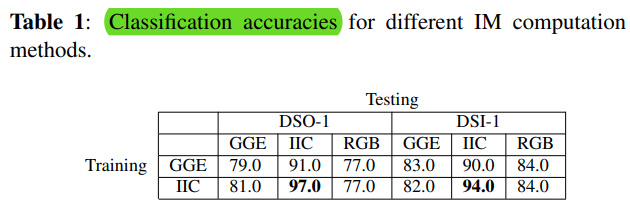
1.使用GGE-IMs方法训练的CNN,从 GGE method、IIC method、原始face提取特征
2.使用IIC-IMs方法训练的CNN,从 GGE method、IIC method、原始face提取特征
对比方法
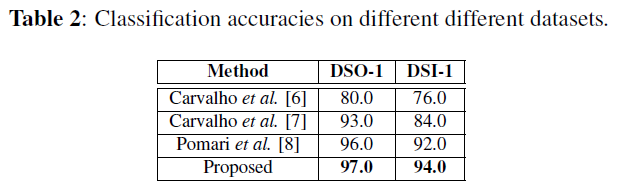
Carvalho et al.[6], [7] and Pomari et al. [8]
如表2
结论
本文提出了一种基于深度学习的人脸特征提取方法,用于检测人脸拼接的伪造特征。
该方法首先训练一个孪生CNN来区分来自同一幅图像的脸对和来自两个随机图像的脸对。
一旦网络被训练,其中一个孪生CNNs被用来从测试图像的面部ims中提取特征。
采用支持向量机对实验图像中真实拼接的人脸进行分类。
我们对不同类型的IM计算方法进行了实验,发现IIC方法是其中表现最好的