scrapy爬取昆明理工大学信自学院导师信息
1.爬取目的
关于昆明理工大学研究生导师信息的收集是因为昆工学校的官网经常不定时关闭,导致一些学生想要查看一些老师的信息,结果却查看不到。正好我的一位同学也刚好想要搜集老师的相关信息。这些信息都在这个学院的官网上放着,http://xzy.kmust.edu.cn/MHWZ/MHWQTGL/jslist.do?ywlbdm=001&lmlxdm=02&lmlbdm=0205&zc=05但是当他看到有一百多位老师的时候,想必谁都会犯怵吧
于是,就想着能不能写一个程序将这些信息全部收集起来呢。
2.技术可行性
现如今随着网络技术的发展,以及数据量的急剧增大,就萌生了一种新的技术,称之为爬虫。我所了解到的很多从事大数据行业的以及做数据分析的从业者,都有需要进行爬虫的需求。这也就使得这项爬虫技术很快的发展,正好在此处也为我们的此次“偷懒”提供了可能。
3.scrapy爬虫
多番调研之后我们采用了很多人都会使用的scrapy爬虫框架,接下来我来简单介绍一下该框架的运行机制:
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下:

从上边的示意图中我们也可以看出,scrapy是由这几个不同的功能模块相互协作,一起完成爬取动作的,接下来我来简单介绍一下其各个功能模块的作用:
| 功能模块 | 作用 |
|---|---|
| 引擎(Scrapy) | 处理整个系统的数据流、触发事务(框架核心) |
| 调度器(Scheduer) | 接收引擎发过来的请求,压入队列,在引擎再次请求的时候返回。(其中这个队列指的是要抓取网页的Url地址,可以去除重复网址。) |
| 下载器(Downloader) | 用于下载页面内容,并将页面内容返回给spiders |
| 爬虫(Spiders) | 在这一部分完成爬取工作的大部分,即在网页中提取出用户需要的数据,并将其赋值给Item实体。也可以在这里进行翻页操作。 |
| 项目管道(Pipeline) | 处理刚才传递的Item实体,验证实体有效性。 |
| 下载器中间件(Downloader Middlewares) | 处理Scrapy引擎与下载器(Downloader)之间的请求及响应 |
| 爬虫中间件(Spider Middlewares) | 处理蜘蛛的响应输入和请求输出。 |
| 调度中间件(Scheduer Middlewares) | 从Scrapy引擎发送到调度的请求和响应。 |
从上边的表格中我们也可以明白整个scrapy框架的工作流程可以简单表述成:
- 引擎在调度器中抽取一个网址(URL)用于下一步的抓取
- 引擎把网址(URL)封装成一个Request请求传给下载器
- 下载器把资源下载下来,并且封装成Response应答包
- Spiders爬虫解析应答包Response
- 解析出Item实体后,将Item实体交给实体管道进行进一步的处理
- 如果解析出的是链接,则把新的URL压入调度器中,等待抓取。
4.爬取过程及结果
此次爬取,暂且略去scrapy整个爬虫框架环境的搭建,如果以后有机会的话,我会再为大家写一个详细教程的。此次博客仅以这个小抓取实验展开。
4.1 根据要抓取的信息首先创建一个Item实体
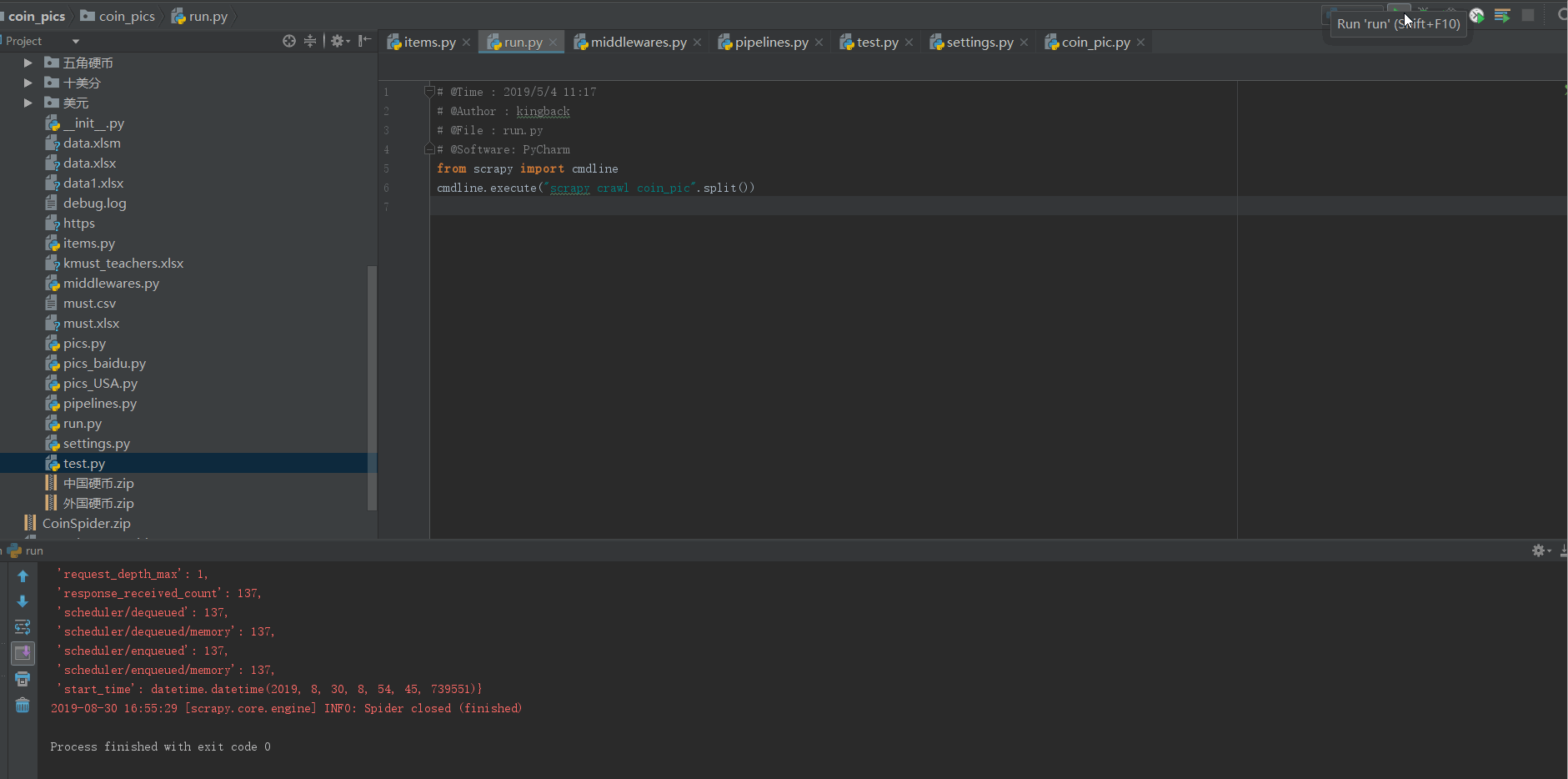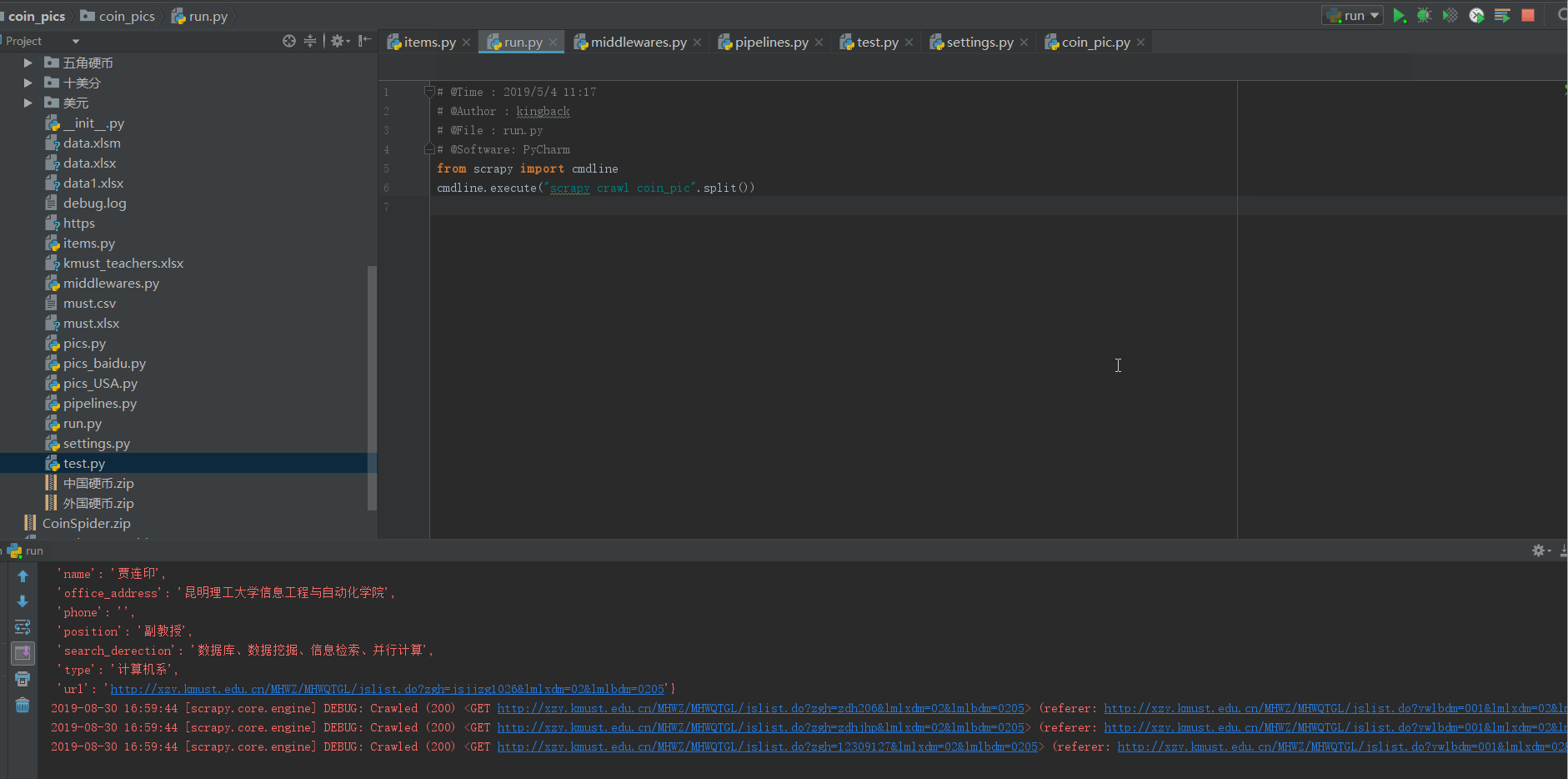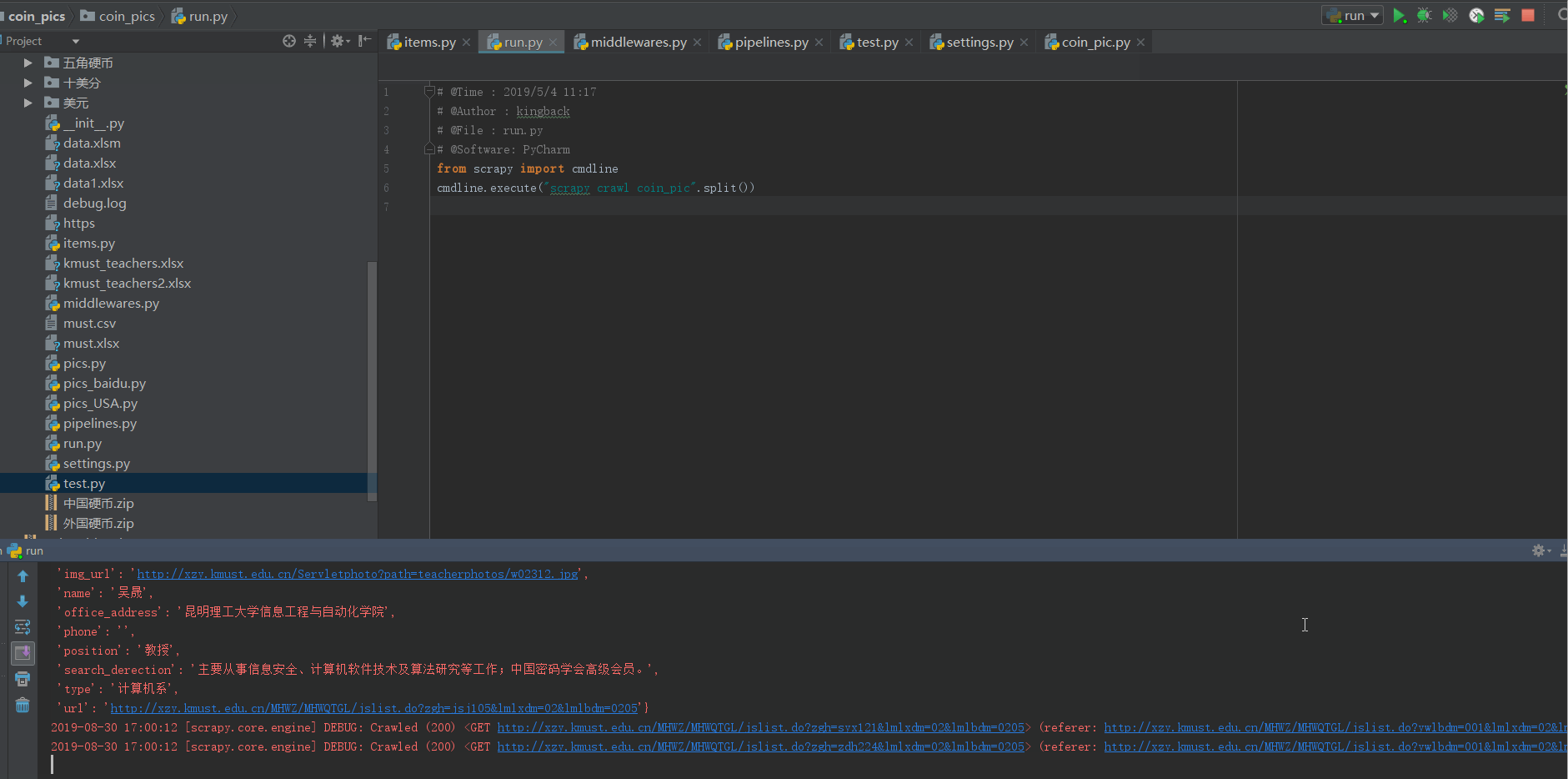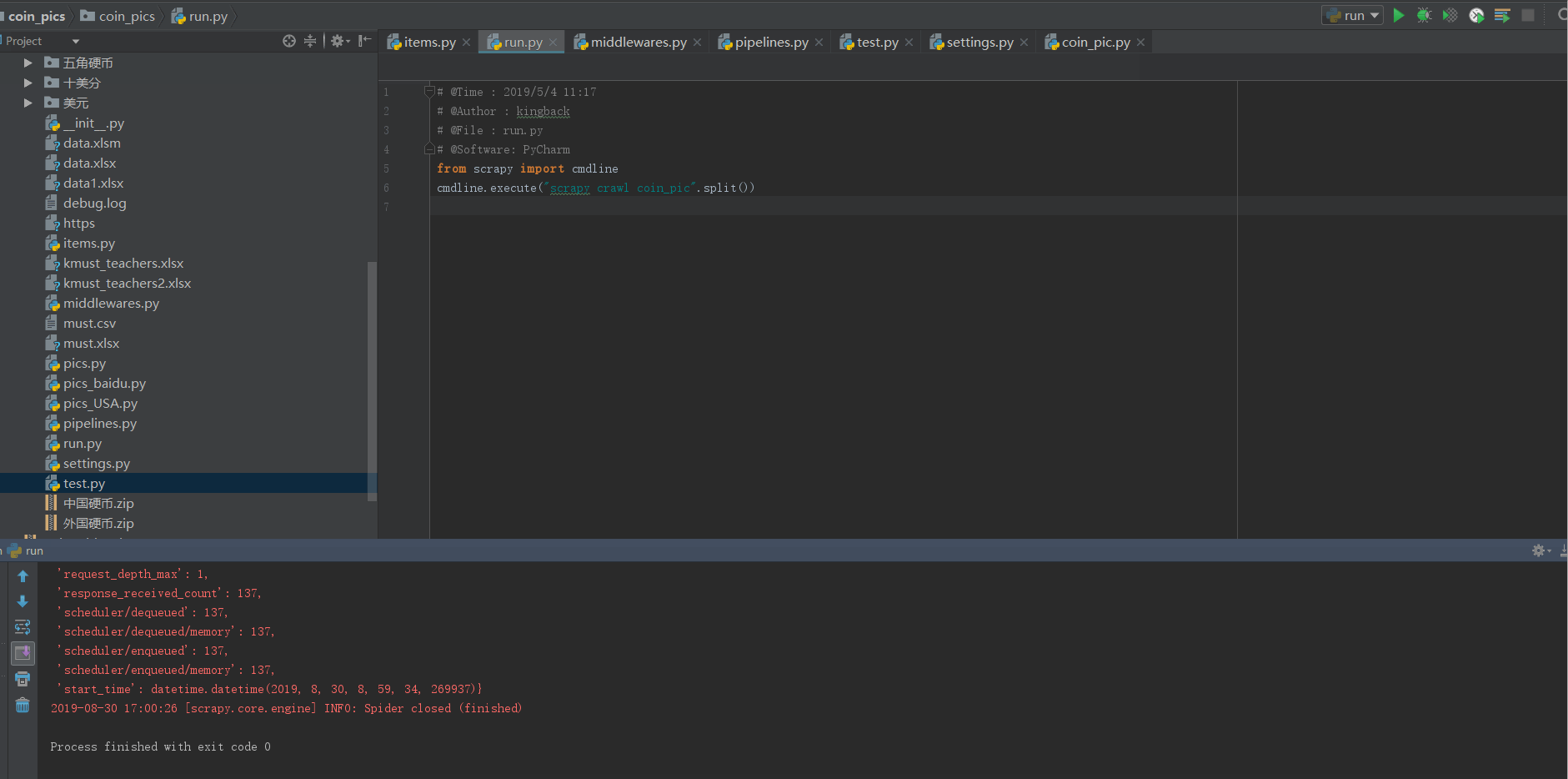
首先我们先参照一下需要存取的信息,包括:教师姓名,性别,职称…个人简介等等。

按照上边的需求我们在items.py内定义一下实体:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class CoinPicsItem(scrapy.Item):
# define the fields for your item here like:
url=scrapy.Field()#老师独立介绍界面
name=scrapy.Field()#姓名
gender=scrapy.Field()#性别
position=scrapy.Field()#职称
type=scrapy.Field()#
email=scrapy.Field()#电子邮件
phone=scrapy.Field()#电话
office_address=scrapy.Field()#办公地址
eduction_background=scrapy.Field()#教育背景
search_derection=scrapy.Field()#研究方向
description=scrapy.Field()#老师描述
img_url=scrapy.Field()#老师照片存储地址
4.2 解析出Item,并将Item交给Pipeline管道
这里才是对于数据进行处理的重头戏,以下为其代码:
# -*- coding: utf-8 -*-
import scrapy
from coin_pics.items import CoinPicsItem
from scrapy.http import Request
from selenium import webdriver
from time import sleep
from selenium.webdriver.remote.webelement import WebElement
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import re
import os
from selenium.common.exceptions import TimeoutException
class CoinPicSpider(scrapy.Spider):
name = 'coin_pic'
allowed_domains = ['xzy.kmust.edu.cn']
start_urls = ['http://xzy.kmust.edu.cn/MHWZ/MHWQTGL/jslist.do?ywlbdm=001&lmlxdm=02&lmlbdm=0205&zc=05',
]
#起始抓取网页地址,也就是我们所说的URL队列
def parse(self, response):
# print(response)
items = []
for i in range(136):
item = CoinPicsItem()
url=response.xpath('//*[@id="jslist"]/tr/td/a/@href').extract()[i]
item['url'] = 'http://xzy.kmust.edu.cn' + url
yield scrapy.http.Request(item['url'], meta={'item': item}, callback=self.parse1)
def parse1(self,response):
item = response.meta['item']
#开始接收返回的数据
#获取老师姓名
ccc = response.xpath('//*[@id="jsxxread"]/tr[1]/td[2]/text()').extract()[0]
item['name']=self.get_need_name(ccc)
#获取老师性别
ccc = response.xpath('//*[@id="jsxxread"]/tr[1]/td[4]/text()').extract()[0]
item['gender']=self.get_need_name(ccc)
#获取老师职称
ccc = response.xpath('//*[@id="jsxxread"]/tr[2]/td[2]/text()').extract()[0]
item['position'] = self.get_need_name(ccc)
#获取老师所属教研室
ccc = response.xpath('//*[@id="jsxxread"]/tr[2]/td[4]/text()').extract()[0]
item['type'] = self.get_need_name(ccc)
#获取老师电子邮箱
ccc = response.xpath('//*[@id="jsxxread"]/tr[3]/td[2]/text()').extract()[0]
item['email'] = self.get_need_name(ccc)
#获取老师电话
ccc = response.xpath('//*[@id="jsxxread"]/tr[3]/td[4]/text()').extract()[0]
item['phone'] = self.get_need_name(ccc)
#获取老师办公地址
ccc = response.xpath('//*[@id="jsxxread"]/tr[4]/td[2]/text()').extract()[0]
item['office_address'] = self.get_need_name(ccc)
#获取老师教育背景
ccc=response.xpath('//*[@id="jsxxread"]/tr[5]/td[2]/p/text()').extract()
item['eduction_background']='暂无描述'
if(len(ccc)!=0):
item['eduction_background'] = response.xpath('//*[@id="jsxxread"]/tr[5]/td[2]/p/text()').extract()[0]
#获取老师研究方向
ccc = response.xpath('//*[@id="jsxxread"]/tr[6]/td[2]/text()').extract()[0]
item['search_derection'] = self.get_need_name(ccc)
#获取老师描述
bbb=response.xpath('//*[@id="jsxxread"]/tr[8]/td/div/div/span/text()').extract()
description=''
for b in bbb:
description=description+b
item['description']=description
#获取老师图片连接地址
aaa=response.xpath('//*[@id="div1"]//@src').extract()
item['img_url']='暂无图片'
if(len(aaa)!=0):
img_url= response.xpath('//*[@id="div1"]//@src').extract()[0]
lists=re.split(r'../',img_url)
item['img_url'] = 'http://xzy.kmust.edu.cn/' + lists[2] + 'os/' + lists[3]
yield item
#http://xzy.kmust.edu.cn/Servletphoto?path=teacherphotos/cwg001.jpg
#../../Servletphoto?path=teacherphotos/cwg001.jpg
def get_need_name(self,str):
lists = re.split(r'\r\n', str)
list=re.split(r' ',lists[1])
result = list[-1]
return result
当然如果你只做到这里我们知识完成了对于Item实体的赋值,其实如果你没有声明一下的话,下一步Pipeline管道是永远不会得到要进一步处理的实体Item的。因此这就需要我们在setting.py文件里边加入如下声明,我要将Item传入哪个管道进行处理。(此处我们的项目因为比较小,所以只开设了一个管道,但如果项目管道多的时候,计算机就不知道我们要将Item实体传入到哪个管道了,所以此处非常重要!!)
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'coin_pics.pipelines.CoinPicsPipeline': 300,
}
代码中的管道数值,可以随意设置,一般设置为1~1000皆可。主要用于区分不同的管道(至少我是这么理解的)。
4.3 在Pipeline实现对于爬取信息的保存
在管道内得到Item实体传过来的信息以后,我们需要在对应的pipelines进行数据的进一步处理(比如保存,存入数据库等等),但如果是网页地址的话,可以按照需求选择是否传回之前的等待爬取的URL网址队列。
此处我们就直接将导师的图片直接下载到本地。pipelines.py代码如下:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import openpyxl
from openpyxl import Workbook
from openpyxl.drawing import image
import requests
import urllib.request
from time import sleep
#存储到本地数据
class CoinPicsPipeline(object):
def __init__(self):
#创建excel,填写表头
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['姓名', '性别', '职位', '所在院系','电子邮件','电话','办公地址','教育背景','研究方向','描述','图片']) # 设置表头
def process_item(self, item, spider):
line = [item['name'], item['gender'], item['position'], item['type'],item['email'],item['phone'],item['office_address'],
item['eduction_background'],item['search_derection'],item['description'],item['img_url']] # 把数据中每一项整理出来
self.ws.append(line) # 将数据以行的形式添加到xlsx中
self.wb.save('kmust_teachers2.xlsx') # 保存xlsx文件
#以下将图片爬取下来存储到本地
if(item['img_url']!='暂无图片'):
imgres = requests.get(item['img_url'])
with open(r'K:/数据存档/scrapy项目/coin_pics/coin_pics/teachers/'+str(item['name'])+'.jpg', "wb") as f:
f.write(imgres.content)
return item
例如在这个管道中,我就讲导师的全部信息先存到一个excel表格中,并且又单独对各个导师的图片进行了下载。
4.4 关于程序的执行
由于scrapy框架的特殊,我们在启动该爬虫时,还需要在同级目录下自己创建一个python文件来启动该爬虫模块。例如我自己创建了一个run.py文件,其内容如下:
# @Time : 2019/5/4 11:17
# @Author : kingback
# @File : run.py
# @Software: PyCharm
from scrapy import cmdline
cmdline.execute("scrapy crawl coin_pic".split())
我们需要调用cmd命令窗口来执行名字为“coin_pic”的爬虫。这个名字是在我们一开始要创建爬虫时必须为起的一个名字,就像是一个小孩的出生,你得给他起个名字一样。这样该命令一执行,就会启动我们的爬虫。
5.程序运行截图