程序逻辑图如下:

登录模块(获取cookie):
# encoding=utf-8
import requests
import re
import sys
#设置请求头
headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch, br',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Host':'www.zhihu.com',
'Origin':'https://www.zhihu.com',
'Referer':'https://www.zhihu.com/',
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'x-hd-token':'hello',
}
#下面写入账号密码
post_data={
'_xsrf':'***',
'password':'****',
'captcha':'***',
'phone_num':'*****',
}
req=requests.Session()
def login():
page=req.get(url="https://www.zhihu.com/#signin",headers=headers)
parser=re.compile(u'<input type="hidden" name="_xsrf" value="(.*?)"/>',re.S)
xsrf=re.findall(parser,page.text)[0]
headers['X-Xsrftoken']=xsrf
post_data['_xsrf']=xsrf
#下载验证码
with open("../code.jpg",'wb') as w:
p=req.get(url="https://www.zhihu.com/captcha.gif?r=1495546872530&type=login",headers=headers)
w.write(p.content)
code=input("请输入验证码:")
if not code:
sys.exit(1)
post_data['captcha']=code
res=req.post(url='https://www.zhihu.com/login/phone_num',data=post_data,headers=headers)
print(res.text)
return req
cookie=login().cookies.get_dict()
spiders如下:这里用re(正则表达式和xpath解析网页,不懂的同学可以花时间去学习一下)
# -*- coding: utf-8 -*-
import scrapy
from zhihu.items import *
import re
class ZhSpider(scrapy.Spider):
name = 'zh'
allowed_domains = ['zhihu.com']
start_urls = ['http://zhihu.com/']
url='http://www.zhihu.com/'
start_urls=['ruan-fu-zhong-tong-zhi','mu-huan-98',
'zeus871219','a-li-ai-di-10','dyxxg','hao-er-8',
'liu-miao-miao-47-17','peng-chen-xi-39','song-ling-shi-liao-63-56']
task_set=set(start_urls)
tasked_set=set()
def start_requests(self):
while len(self.task_set)>0:
print("**********start用户库**********")
print(str(self.task_set))
print("********************")
id=self.task_set.pop()
if id in self.tasked_set:
print("已经存在的数据 %s" %(id))
continue
self.tasked_set.add(id)
userinfo_url='https://www.zhihu.com/people/{}/answers'.format(id)
user_item=UserItem()
user_item['Id']=id
user_item['Url']=userinfo_url
yield scrapy.Request(
userinfo_url,
meta={"item":user_item},callback=self.User_parse,dont_filter=True
)
yield scrapy.Request(
'https://www.zhihu.com/people/{}/followers'.format(id),
callback=self.Add_user,dont_filter=True
)
def Add_user(self,response):
sel=scrapy.selector.Selector(response)
#<a class="UserLink-link" target="_blank" href="/people/12321-89">12321</a>
#//*[@id="Profile-following"]/div[2]/div[2]/div/div/div[2]/h2/div/span/div/div/a/@href
#//*[@id="Popover-24089-95956-toggle"]
#//*[@id="Popover-24089-95956-toggle"]/a
#print(response.text)
co=sel.xpath('//*[@id="root"]/div/main/div/div/div[2]').extract_first()
patten=re.compile(u'<a class="UserLink-link" target="_blank" href="/people/(.*?)">.*?</a>',re.S)
l=re.findall(patten,co)
#l=sel.xpath('//*[@id="Profile-following"]/div[2]/div[2]/div/div/div[2]/h2/div/span/div/div/a/@href')
for i in l:
if str(i) not in self.tasked_set and str(i) not in self.task_set:
self.task_set.add(i)
print("**********用户库**********")
print(str(self.task_set))
print("********************")
def User_parse(self, response):
item=response.meta["item"]
sel=scrapy.selector.Selector(response)
nick_name=sel.xpath('//*[@id="ProfileHeader"]/div/div[2]/div/div[2]/div[1]/h1/span[1]/text()').extract_first()
print(nick_name)
#item['Nick_name']=nick_name
summary=sel.xpath('//*[@id="ProfileHeader"]/div/div[2]/div/div[2]/div[1]/h1/span[2]/text()').extract_first()
print(summary)
item['Summary']=summary
item['Nick_name']=nick_name
# print(sel.xpath( '//span[@class="location item"]/@title').extract_first())
co=sel.xpath('//*[@id="ProfileHeader"]/div/div[2]/div/div[2]/div[2]').extract_first()
# print("**********************")
# print(co)
# print('**********************')
patten=re.compile(u'.*?</div>(.*?)<div.*?>',re.S)
l=re.findall(patten,co)
#print(str(l))
print("**********************")
print(str(l))
item['Content']=str(l)
print('**********************')
yield itempipelines模块:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
class ZhihuPipeline(object):
def process_item(self, item, spider):
return item
class MysqlPipeline(object):
def __init__(self):
self.conn=pymysql.connect(
host='localhost', #本地127.0.0.1
port=3306, #默认3306端口
user='root', #mysql最高权限用户
passwd='****', #root用户密码
db='zh', #database name
charset='utf8'
)
def process_item(self,item,spider):
self._conditional_insert(self.conn.cursor(),item)#调用插入的方法
# query.addErrback(self._handle_error,item,spider)#调用异常处理方法
return item
def _conditional_insert(self,tx,item):
sql="insert into user(id,url,nick_name,summary,content) values(%s,%s,%s,%s,%s)"
params=(item["Id"],item["Url"],item['Nick_name'],item['Summary'],item['Content'])
tx.execute(sql,params)
print('已经插入一条数据!')
tx.close()
self.conn.commit()
# self.conn.close()
#错误处理方法
def _handle_error(self, failue, item, spider):
print(failue)items模块:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
from scrapy import Field
class ZhihuItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class UserItem(scrapy.Item):
"""
知乎用户的用户名,居住地,所在行业,职业经历,教育经历,个人简介
"""
Id=Field()
Url=Field()
Nick_name=Field()
Summary=Field()
# Home_Position=Field()
# Compmany=Field()
# Edu=Field()
Content=Field()middlewares模块:
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/spider-middleware.html
from zhihu.getCookie import cookie
from scrapy import signals
class CookiesMiddleware(object):
""" 换Cookie """
def process_request(self, request, spider):
#cookie = random.choice(cookies)
request.cookies = cookie
class ZhihuSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Response, dict
# or Item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)代码是单机的,操作无误的话,可以一直运行下去,理论上可以把所有用户都抓下来,我测试的时候设的俩秒比较慢,一个小时一俩万字段。爬取的数据如下
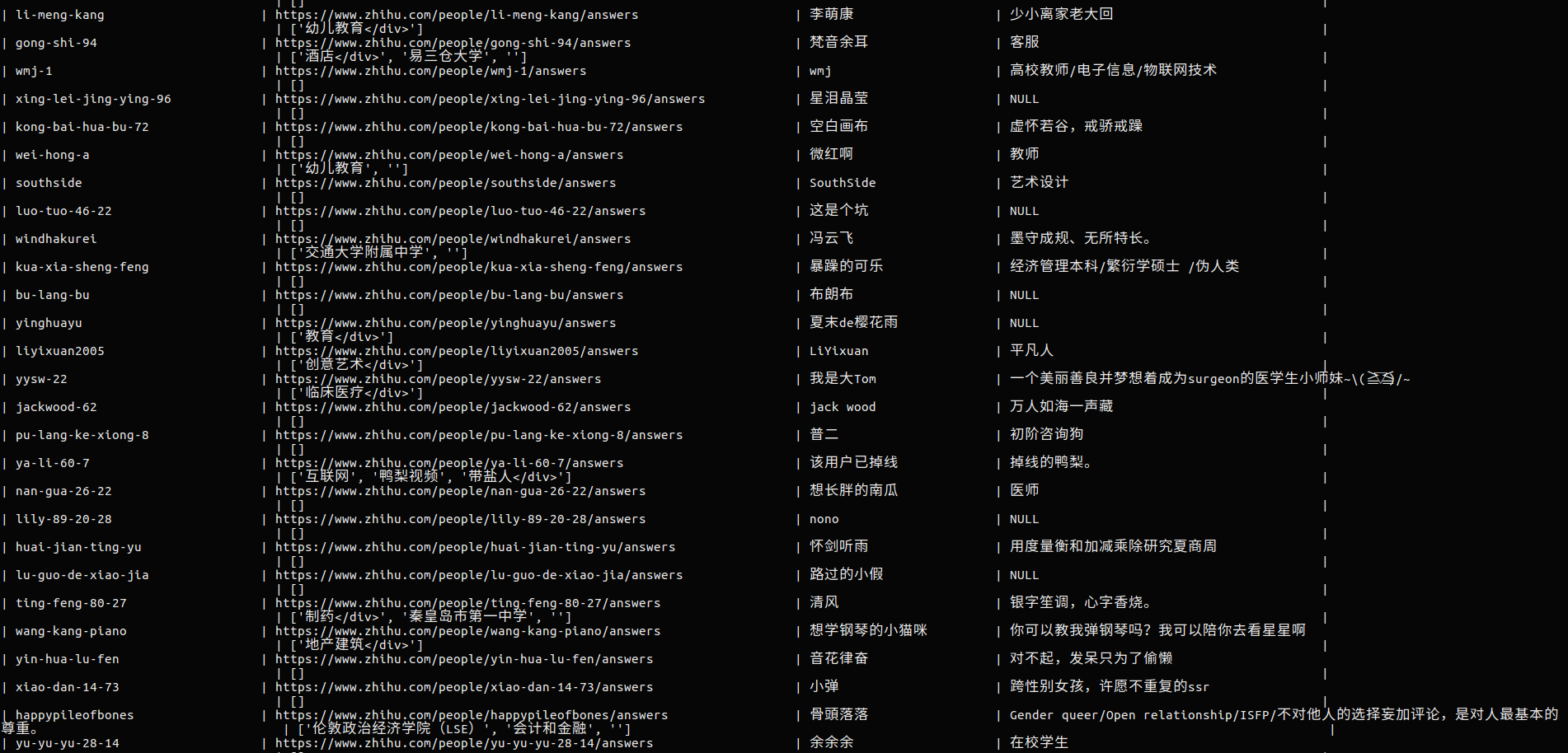
项目地址: