1、scrapy爬虫的流程,可简单该括为以下4步:
1).新建项目---->scrapy startproject 项目名称(例如:myspider)
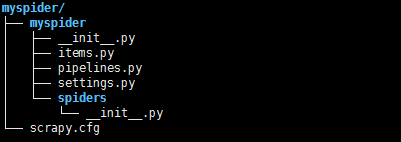
>>scrapy.cfg为项目配置文件
>>myspider:项目的Python模块,将会从这里引用代码
>>mySpider/items.py :项目的目标文件
>>mySpider/pipelines.py :项目的管道文件
>>mySpider/settings.py :项目的设置文件
>>mySpider/spiders/ :存储爬虫代码目录
2).编写items.py文件,可以理解为要爬取的内容,后边在案例中说明
3).编写爬虫文件,在spiders中自己创建,或者通过命令:scrapy genspider 爬虫名 爬虫允许访问的域
4).存储内容(pipelines.py)
案例:爬取黑马培训的老师信息
第一步:创建项目 scrapy startproject ItcastSpider
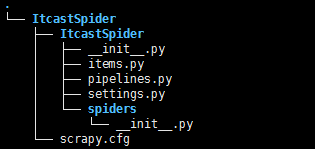
第二步:解析网页,明确要爬取的内容,并编写item文件,代码如下:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy class ItcastspiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 老师姓名 name = scrapy.Field() # 职位 level = scrapy.Field() # 介绍信息 info = scrapy.Field()
第三步:编写爬虫文件 切入spiders文件夹,通过scrapy genspider itcast 'itcast.cn' 来创建
# -*- coding: utf-8 -*- import scrapy # 导入之前已经写好的items文件中的类 from ItcastSpider.items import ItcastspiderItem class ItcastSpider(scrapy.Spider): name = "itcast" #爬虫名 allowed_domains = ["http://www.itcast.cn"] #爬虫允许访问的域 start_urls = ['http://www.itcast.cn/channel/teacher.shtml#apython'] # 要爬取的第一个url def parse(self, response): # 通过scrapy内置的xpath规则解析网页,返回一个包含selector对象的列表 teacher_list = response.xpath('//div[@class="li_txt"]') # 实例化类 item = ItcastspiderItem() for each in teacher_list: # 通过xpath解析后返回该表达式所对应的所有节点的selector list列表,利用extract()可将该节点序列化为Unicode字符串并返回列表 # 老师名称 item['name'] = each.xpath('./h3/text()').extract()[0] # 老师的职称 item['level'] = each.xpath('./h4/text()').extract()[0] # 信息 item['info'] = each.xpath('./p/text()').extract()[0] yield item
第四步:编辑管道文件pipelines,将爬取内容存贮到本地
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import json class ItcastspiderPipeline(object): def __init__(self): # 在本地创建teacher.json文件 self.filename = open('teacher.json','w') def process_item(self, item, spider): # python类型转化为json字符串 text = json.dumps(dict(item),ensure_ascii = False) + '\n' # 写入 self.filename.write(text.encode('utf-8')) return item def close_spider(self,spider): self.filename.close()
第五步:在settings.py中配置管道文件

第六步:启动爬虫 命令 scrapy crawl itcast