创建项目:scrapy startproject dangdang
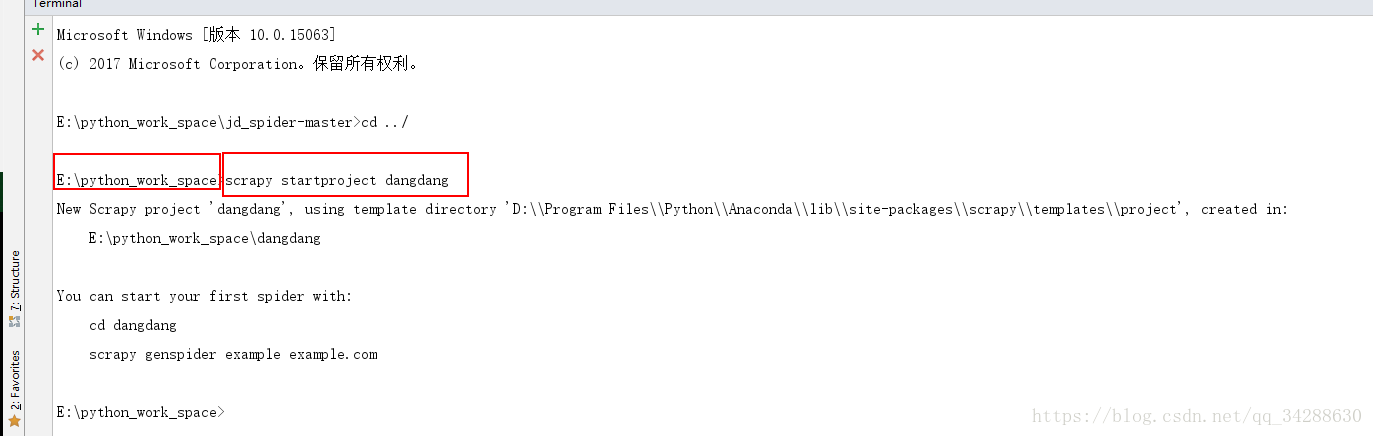
如下用pycharm打开:
使用默认模版创建爬虫scrapy genspider -t basic dd dangdang.com
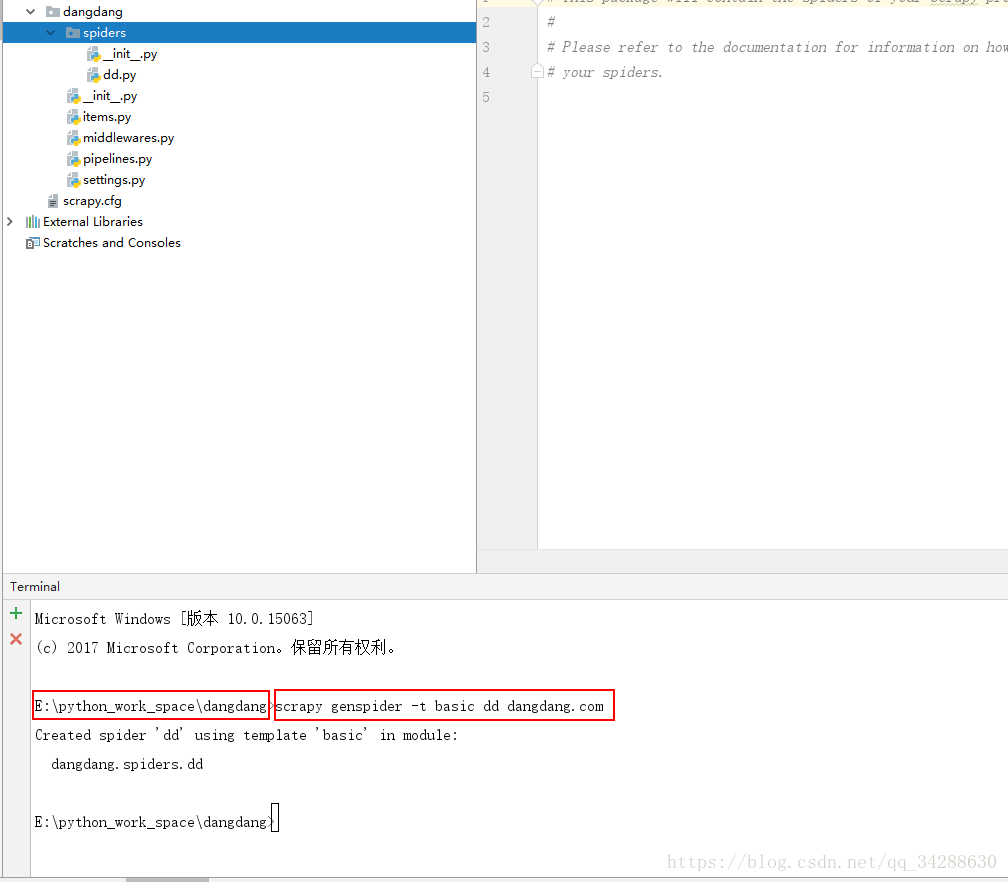
执行完毕:
一、编写item,需要爬取的信息model
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
二、开启seting中的pipelines
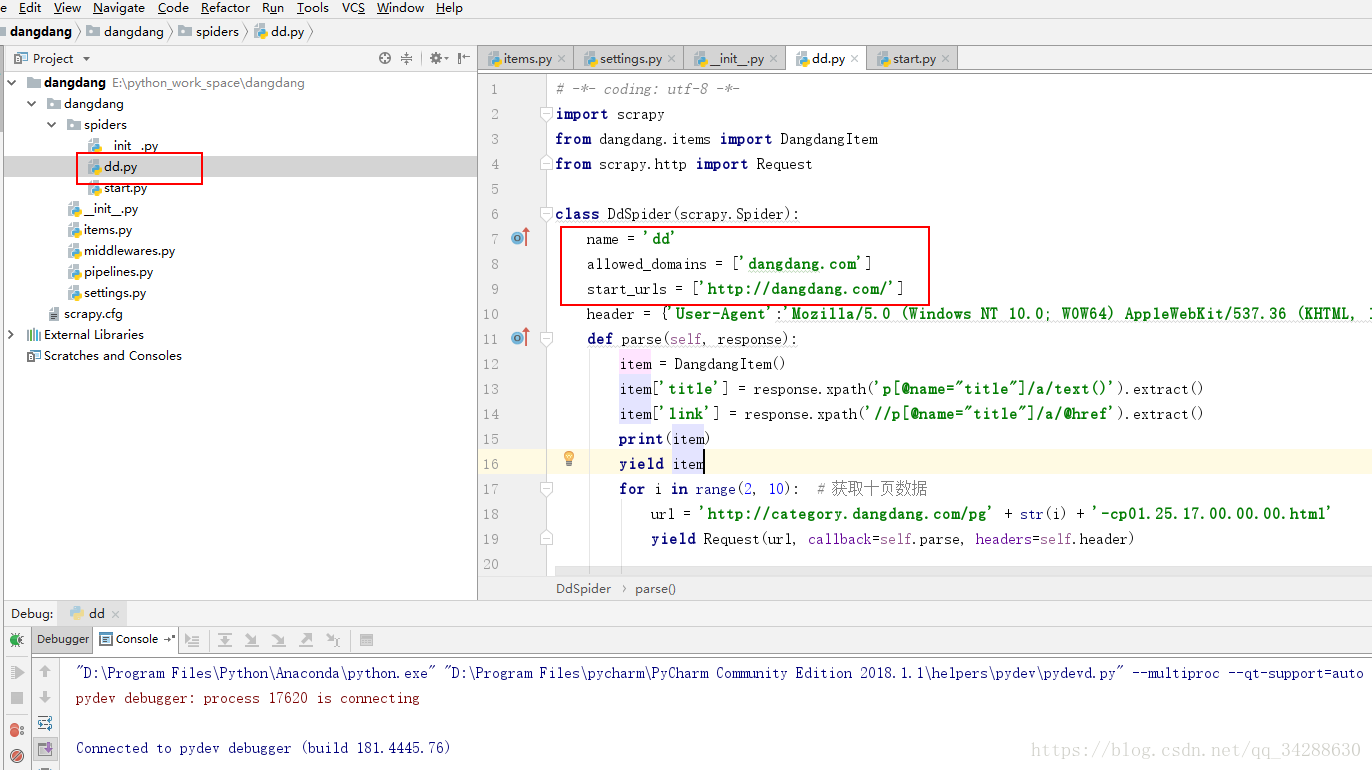
三、编写爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from dangdang.items import DangdangItem
from scrapy.http import Request
class DdSpider(scrapy.Spider):
name = 'dd'
allowed_domains = ['dangdang.com']
start_urls = ['http://dangdang.com/']
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER'}
def parse(self, response):
item = DangdangItem()
item['title'] = response.xpath('p[@name="title"]/a/text()').extract()
item['link'] = response.xpath('//p[@name="title"]/a/@href').extract()
print(item)
yield item
for i in range(2, 10): # 获取十页数据
url = 'http://category.dangdang.com/pg' + str(i) + '-cp01.25.17.00.00.00.html'
yield Request(url, callback=self.parse, headers=self.header)