版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Yk_0311/article/details/83096469
要点
1.分析Ajax请求
观察到Ajax请求参数的变化,有一个参数sn一直在变化,当sn=30时,返回的时前30张图片,listtype时排序方式,temp是参数可以忽略
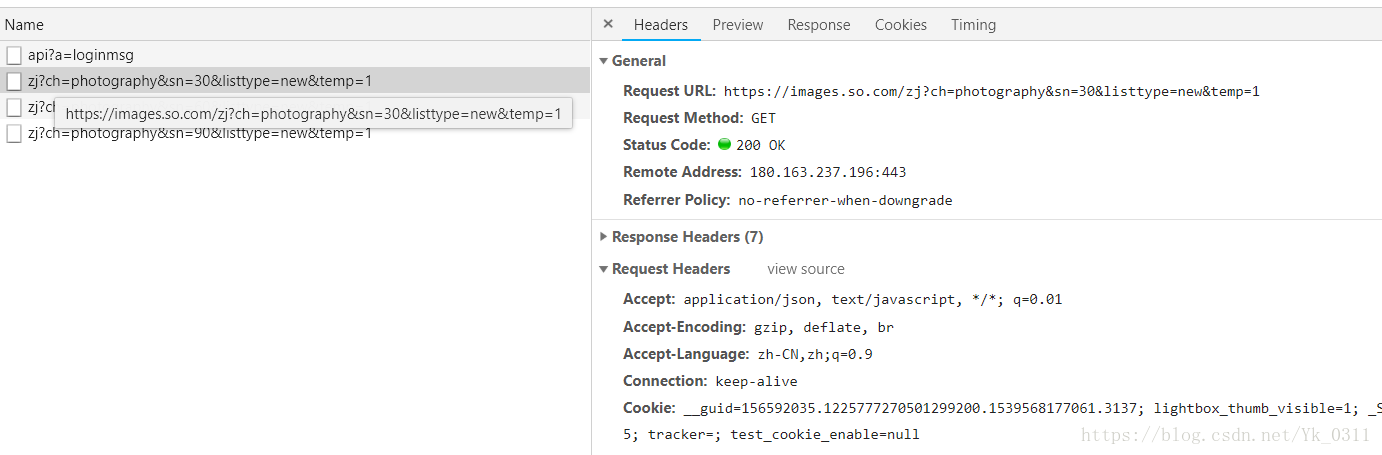
2.构造请求和提取信息
# -*- coding: utf-8 -*-
import scrapy
from images360.settings import MAX_PAGE
from images360.items import Images360Item
import json
class ImagesSpider(scrapy.Spider):
name = 'images'
'''
这里将start_urls 列表删去了
start_urls: 它是起始URL列表,当我们没有实现start_requests()方法时,默认会从这个列表开始抓取
'''
def start_requests(self): # 此方法用于生成初始请求,它必须返回一个可迭代对象
for page in range(MAX_PAGE): # MAX_PAGE在settings.py中定义好了
url = 'https://images.so.com/zj?ch=photography&sn={}&listtype=new&temp=1'.format(page * 30)
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
result = json.loads(response.body)
item = Images360Item()
for image in result.get('list'): # 遍历一个列表
item['id'] = image.get('imageid') # ID
item['url'] = image.get('qhimg_url') # url
item['title'] = image.get('group_title') #标题
yield item
3.修改User-Agent
在middlewares.py 中添加一个RandomUserAgentMiddleware类
class RandomUserAgentMiddleware():
def __init__(self):
self.user_agent = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1'
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
'Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50'
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20'
]
def process_request(self,request,spider):
request.headers['User-Agent']=random.choice(self.user_agent)
首先先定义了几个不同的User-Agent,然后实现 process_request(request, spider) 方法,修改request的headers属性的User-Agent,随机选取了User-Agent
要使之生效需要在 settings.py 中取消DOWNLOADER_MIDDLEWARES注释,并改写成如下内容
DOWNLOADER_MIDDLEWARES = {
'images360.middlewares.RandomUserAgentMiddleware': 543,
}
4.将数据存入数据库
在settings.py 中添加几个变量
# 连接数据时需要的参数
MYSQL_HOST = 'localhost'
MYSQL_DATABASE = 'spiders'
MYSQL_PORT = 3306
MYSQL_USER = 'root'
MYSQL_PASSWORD = 'yellowkk'#密码
实现 MysqlPipeline 在pipelines.py
class MysqlPipeline():
def __init__(self, host, database, user, password, port):
self.host = host
self.database = database
self.user = user
self.password = password
self.port = port
@classmethod
def from_crawler(cls, crawler): # 类方法,参数是crawler,通过此对象我们可以拿到Scrapy的所有核心组件
return cls(
host=crawler.settings.get('MYSQL_HOST'),
database=crawler.settings.get('MYSQL_DATABASE'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
port=crawler.settings.get('MYSQL_PORT')
)
def open_spider(self, spider):
self.db = pymysql.connect(host=self.host, user=self.user, password=self.password, port=self.port,
db=self.database, charset='utf8')
self.cursor = self.db.cursor()
def close_spider(self, spider):
self.db.close()
def process_item(self, item, spider):
data = dict(item) # item是一个类字典的类型,将其转化为字典类型、
keys = ','.join(data.keys())
values = ','.join(['%s'] * len(data))
sql = 'insert into image360({}) values({})'.format(keys, values)#插入方法是一个动态构造SQL语句的方法
self.cursor.execute(sql, tuple(data.values()))
self.db.commit()
return item
最后在 settings.py 中 设置ITEM_PIPELINES,如下
ITEM_PIPELINES = {
'images360.pipelines.MysqlPipeline': 300,
}
具体代码已经上传github:https://github.com/YilK/Web-Crawler/tree/master/DEMO05-360摄影图片的爬取