爬虫最后要达到的效果,是将某分类下,第一页的所有商品的评论保存至mysql中。
具体会保存评论日期、评论id、评论内容、商品链接和商品id。
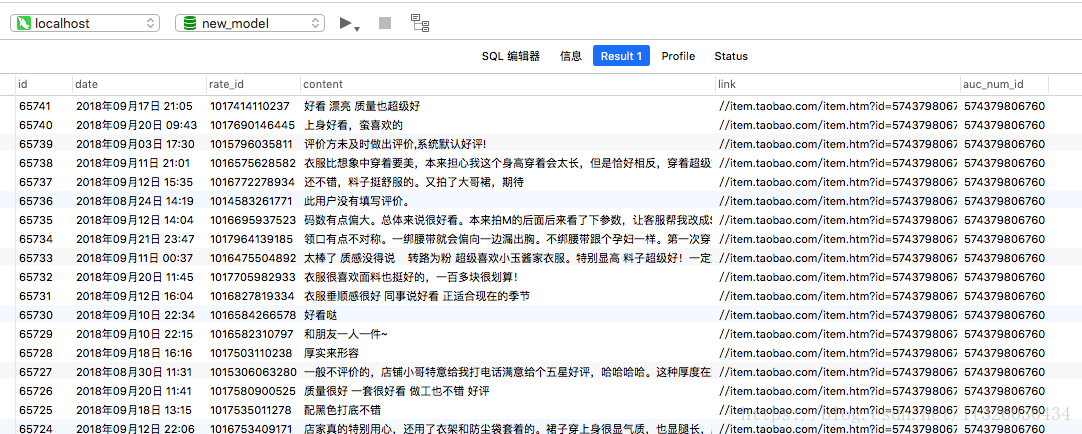
爬虫部分代码
# -*- coding: utf-8 -*-
import scrapy
import re
import requests
import math
import json
from scrapy.loader import ItemLoader
from taobao_test.items import GoodsItem
class LianyiqunSpider(scrapy.Spider):
name = 'lianyiqun'
allowed_domains = ['item.taobao.com',
'rate.taobao.com',
's.taobao.com'
]
start_urls = [
'这里填写要抓取的商品分类主页链接'
]
# 解析"连衣裙"分类页面(第一页商品)
def parse(self, response):
# 获取储存列表用的script标签
js_script = response.css('script::text')[4].extract()
# 获取储存列表用的json
g_page_config = re.findall('g_page_config = ([\s\S]*)g_srp_loadCss', js_script)[0]
g_page_config_json = json.loads(g_page_config.strip()[0:-1])
# 访问商品链接
auctions = g_page_config_json['mods']['itemlist']['data']['auctions']
for a in auctions:
yield scrapy.Request(url="http://" + a['detail_url'], callback=self.goods_detail)
# 解析商品信息
def goods_detail(self, response):
# 获取到页面渲染的第一个脚本的数据结构
first_js_script = response.css('script::text')[0].extract()
# 正则匹配到g_config字段
g_config = re.findall('var g_config = ([\s\S]*)g_config\.tadInfo', first_js_script)[0]
# 正则匹配,拿到页面的评论url
rate_counter_api = re.findall("rateCounterApi : '//(.*)',", g_config)[0]
# 访问获取评论的url
rate_count_response = requests.get("http://" + rate_counter_api)
# 获取评论数量
rate_count = re.findall('"count":(.*)}', rate_count_response.text)[0]
# 拿到data_list_api_url,这个能够匹配到域名
data_list_api_url = response.css('#reviews::attr(data-listapi)').extract()[0]
# 获取到评论的url
feed_rate_list_url = re.findall('//(.*)\?', data_list_api_url)[0]
# 宝贝id
auttion_num_id = re.findall('auctionNumId=([\d]*)&', data_list_api_url)[0]
# 设置一个值,一页获取的评论数量
page_size = 20
# 计算一共有多少页的评论
pages = math.ceil(int(rate_count) / page_size)
# 迭代一共有多少页,然后分别请求每一页评论
for current_page_number in range(1, pages):
yield scrapy.Request(url="http://" + feed_rate_list_url
+ "?auctionNumId=" + auttion_num_id
+ "¤tPageNum=" + str(current_page_number)
+ "&pageSize=" + str(page_size),
callback=self.parse_rate_list)
# 解析具体的评论
def parse_rate_list(self, response):
# 将响应信息转换成json格式
goods_rate_data_json = json.loads(response.text.strip()[1:-1])
# 获取到具体的评论信息,就是json信息获取
comments = goods_rate_data_json['comments']
for comment in comments:
# ItemLoader方式
goods_item_loader = ItemLoader(item=GoodsItem(), response=response)
# 评论时间
goods_item_loader.add_value('date', comment['date'])
# 评论id
goods_item_loader.add_value('rate_id', comment['rateId'])
# 评论内容
goods_item_loader.add_value('content', comment['content'])
auction = comment['auction']
# 商品的链接地址
goods_item_loader.add_value('link', auction['link'])
# 商品id
goods_item_loader.add_value('auc_num_id', auction['aucNumId'])
yield goods_item_loader.load_item()
items代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy.loader.processors import MapCompose
from scrapy.loader.processors import Join
def parse_field(text):
return str(text).strip()
class TaobaoTestItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class GoodsItem(scrapy.Item):
# 评论时间
date = scrapy.Field(
input_processor=MapCompose(parse_field),
output_processor=Join(),
)
# 评论id
rate_id = scrapy.Field(
input_processor=MapCompose(parse_field),
output_processor=Join(),
)
# 评论内容
content = scrapy.Field(
input_processor=MapCompose(parse_field),
output_processor=Join(),
)
# 商品链接
link = scrapy.Field(
input_processor=MapCompose(parse_field),
output_processor=Join(),
)
# 商品id
auc_num_id = scrapy.Field(
input_processor=MapCompose(parse_field),
output_processor=Join(),
)
def get_insert_sql(self):
insert_sql = """
insert into rate(date,rate_id,content,link,auc_num_id)
values (%s,%s,%s,%s,%s)
"""
params = (self["date"], self["rate_id"], self["content"], self["link"], self["auc_num_id"])
return insert_sql, params
main代码
#coding:utf-8
from scrapy.cmdline import execute
import sys
import os
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy", "crawl", "lianyiqun"])
pipelines代码
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import codecs
import json
import MySQLdb.cursors
from twisted.enterprise import adbapi
import pymysql
class TaobaoTestPipeline(object):
def process_item(self, item, spider):
return item
class JsonPipeline(object):
def __init__(self):
self.file = codecs.open("jsondata.json", "w", encoding="utf-8")
def process_item(self, item, spider):
lines = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(lines)
return item
def spider_close(self):
self.file.close()
class writeMysql(object):
def __init__(self):
self.client = pymysql.connect(
host='localhost',
port=3306,
user='root',
passwd='123456',
db='new_model',
charset='utf8'
)
self.cur = self.client.cursor()
def process_item(self, item, spider):
insert_sql, params = item.get_insert_sql()
self.cur.execute(insert_sql, params)
self.client.commit()
return item
def handle_error(self, failure, item, spider):
print(failure)
源码以上传至git,可点击直接查看git地址,有疑问的同学可提Issues或在博客下方留言~