分区
1.分区的作用
RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区,分别保存在不同的节点上。如下图所示,一个集群中包含4个工作节点(Worker Node),分别是WorkerNode1、WorkNode2、WorkNode3和WorkNode4,假设有两个RDD,即rdd1和rdd2,其中,rdd1包含5个分区,即p1、p2、p3、p4和p5,rdd2包含3个分区,即p6,p7,p8.
对RDD进行分区,第一个功能是增加并行度。例如,在图中,rdd2的3个分区p6、p7和p8,分布在3个不同的工作节点WorkerNode2、WorkerNode3、WorkerNode4上面,就可以在这3个工作节点上分别启动3个线程对这3个分区的数据进行并行处理,从而增加了任务的并行度。
对RDD进行分区的第二个功能是减少通信开销。在分布式系统中,通信的代价是巨大的,控制数据分布以获得最少的网络传输可以极大地提升整体性能。Spark程序可以通过控制RDD分区方式来减少网络通信的开销。
2.分区的原则
RDD分区的一个原则是使分区的个数尽量等于集群中的CPU核心(Core)数目。对于不同的Spark部署模式而言(Local模式、Standalone模式、YARN模式、Mesos模式),都可以通过设置spark.default.parallelism这个参数值,来配置默认的分区数目。一般而言,各种模式下的默认分区数目如下:
- Local模式:默认为本地机器的CPU数目,若设置了local[N],其默认为N;
- Standalone或YARN模式:在”集群中所有CPU核心数目总和“和”2“这二者中取较大值作为默认值
- Mesos模式:默认的分区数为8.
3.设置分区的个数
可以手动设置分区的数量,主要包括两种方式:(1)创建RDD时手动指定分区个数;(2)使用reparitition方法重新设置分区个数。
- 创建RDD时手动指定分区个数
在调用textFile()和parallelize()方法的时候手动指定分区个数即可,语法格式如下:
sc.textFile(path,partitionNum)
其中,path参数用于指定要加载的文件的地址,partitionNum参数用于指定分区个数。

对于parallelize()而言,如果没有在方法中指定分区数,则默认为spark.default.parallelism。对于textFile()而言,如果没有在方法中指定分区数,则默认为min(defaultParallelism,2),其中,defaultParallelism对应的就是spark.default.parallelism。如果是HDFS中读取文件,则分区数位文件分片数(例如,128MB/片)
- 使用reparitition方法重新设置分区个数
通过转换操作得到新的RDD时,直接调用repartition方法即可。

键值对RDD
键值对RDD是指每个RDD元素都是(key,value)键值对类型,是一种常见的RDD类型,可以应用于很多的应用场景。
键值对RDD的创建
键值对RDD的创建主要有两种方式:
- 从文件中加载生成RDD;
- 通过并行集合(数组)创建RDD
- 从文件中加载生成RDD
首先使用textFile()方法从文件中加载数据,然后,使用map()函数转换得到相应的键值对RDD
上面语句中,map(word=>(word,1))函数的作用是,取出RDD中的每个元素,也就是每个单词,赋值给word,然后把word转换成(word,1)的键值对形式。
- 通过并行集合(数组)创建RDD

常用的键值对转换操作
常用的键值对转换操作包括reduceByKey(func)、groupByKey()、keys、values、sortByKey()、mapValues(func)、join和combineByKey等。
- reduceByKey(func)
reduceByKey(func)的功能是,使用func函数合并具有相同键的值。例如,有一个键值对RDD包含4个元素,分别是("Hadoop",1)、("Spark",1)、("Hive",1)和("Spark",1)。可以使用reduceByKey()操作,得到每个单词出现次数,代码及其执行结果如下:

- groupByKey()
groupByKey()的功能是,对具有相同键的值进行分组,如下所示:
reduceByKey和groupByKey的区别是:reduceByKey用于对每个key对应的多个value进行聚合操作,并且聚合操作可以通过函数func进行自定义;groupByKey也是对每个key进行操作,但是,对每个key只会生成一个value-list;groupByKey本身不能自定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。
实际上,对于一些操作,可以通过reduceByKey得到结果,也可以通过组合使用groupByKey和map操作得到结果,二者是”殊途同归“。
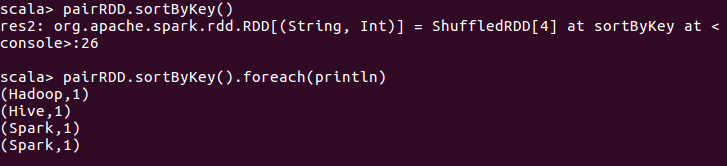
- sortByKey()
sortByKey()的功能是返回一个根据key排序的RDD。
- mapValues(func)
mapValues(func)对键值对RDD中的每个value都应用一个函数,但是,key不会发生变化。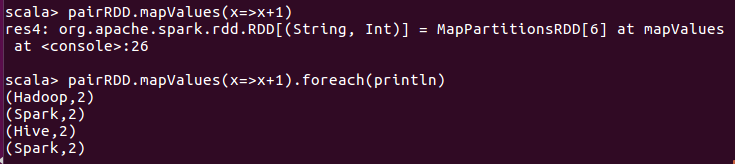
- combineByKey
combineByKey(createCombiner,mergeValue,mergeCombiners,partitioner,mapSideCombine)中的各个参数的含义如下:
- createCombiner:在第一次遇到key时创建组合器函数,将RDD数据计中的V类型的值转换C类型的值(V=>C);
- mergeValue:合并值函数,再次遇到相同的Key时,将createCombiner的C类型值与这次传入的V类型值合并成一个C类型值(C,V)=>C;
- mergeCombiners:合并组合器函数,将C类型值两两合并成一个C类型值;
- partitioner:使用已有的或自定义的分区函数,默认是HashPartitioner;
- mapSideCombine:是否在map端进行Combine操作,默认为true。
