1、WordCount案例实操
导入项目依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.3.0</version>
</dependency>
</dependencies>
1.1 本地调试
本地Spark程序调试需要使用Local提交模式,即将本机当做运行环境,Master和Worker都为本机。运行时直接加断点调试即可。
1、准备测试文件word.txt
hello world
hello zhm
hello future
2、代码实现
package com.zhm.spark.wordcount;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName WordCountLocal
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/28 14:15
* @Version 1.0
*/
public class WordCountLocal {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("WordCountLocal");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、Todo 获取RDD
JavaRDD<String> javaRDD = sparkContext.textFile("input/word.txt");
//4、对每行数据根据分隔符进行拆分
JavaRDD<String> stringJavaRDD = javaRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.stream(s.split(" ")).iterator();
}
});
//5、给每个元素加上一个1
JavaPairRDD<String, Integer> javaPairRDD = stringJavaRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s, 1);
}
});
//6、利用ReduceByKey对相同key的数据进行累加
JavaPairRDD<String, Integer> result = javaPairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
//7、收集结果输出
result.collect().forEach(System.out::println);
//x 关闭 sparkContext
sparkContext.stop();
}
}
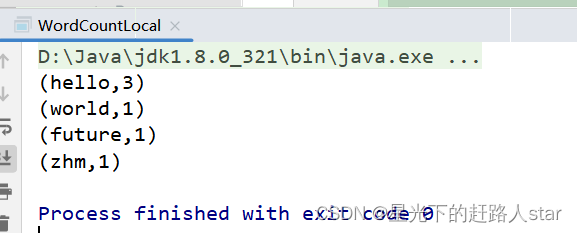
运行结果:
1.2 集群运行
1、修改代码
package com.zhm.spark.wordcount;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName WordCountYarn
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/28 14:25
* @Version 1.0
*/
public class WordCountYarn {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("yarn").setAppName("WordCountYarn");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、Todo 获取RDD
JavaRDD<String> javaRDD = sparkContext.textFile(args[0]);
//4、按行读取然后按分隔符切分字符串
JavaRDD<String> stringJavaRDD = javaRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.stream(s.split(" ")).iterator();
}
});
//5、将每个单词转换为(word,1)
JavaPairRDD<String, Integer> pairRDD = stringJavaRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s, 1);
}
});
//6、累加相同key的值
JavaPairRDD<String, Integer> result = pairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
//7、将数据储存到文件上
result.saveAsTextFile(args[1]);
//x 关闭 sparkContext
sparkContext.stop();
}
}
2、打包到集群测试
(1)点击package打包,然后,查看打完后的jar包
(2)将WordCount.jar上传到/opt/module/spark-yarn目录
(3)在HDFS上创建,存储输入文件的路径/input
(4)创建test_data并上传word.txt文件到/opt/module/spark-yarn/test_data/目录下,在上传到HDFS的/input路径下
(5)执行任务
bin/spark-submit \
--class com.atguigu.spark.WordCount \
--master yarn \
./WordCount.jar \
/input \
/output
##注意:input和ouput都是HDFS上的集群路径
(6)查询运行结果
hadoop fs -cat /output/*
2、RDD序列化
在实际开发中我们往往需要自己定义一些对于RDD的操作,那么此时需要注意的是:
(1)初始化工作(与计算无关的操作)是在Driver端进行的
(2)而实际运行程序(数据计算操作)是在Executor端进行的
这就涉及到了跨进程通信,是需要序列化的。
2.1 序列化测试
1、 创建包名:com.zhm.spark.operator.serializable
2、创建使用的javaBean:User
3、创建类:Test_user测试序列化:将RDD中元素包装为User进行测试
package com.zhm.spark.operator.serializable;
/**
* @ClassName User
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/29 11:32
* @Version 1.0
*/
public class User {
private String name;
private int age;
public User() {
}
public User(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
package com.zhm.spark.operator.serializable;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
import java.util.Arrays;
/**
* @ClassName Test_User
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/29 11:33
* @Version 1.0
*/
public class Test_User {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test_User");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、创建RDD数据集
JavaRDD<User> javaRDD = sparkContext.parallelize(Arrays.asList(new User("zhm", 24), new User("zhm1", 25)));
javaRDD.foreach(new VoidFunction<User>() {
@Override
public void call(User user) throws Exception {
System.out.println(user);
}
});
//x 关闭 sparkContext
sparkContext.stop();
}
}
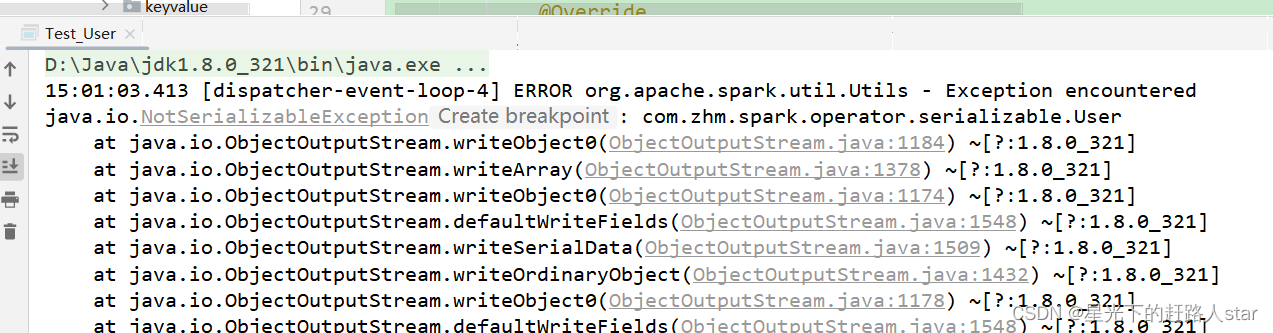
运行结果:
对javaBean:User类进行修改
package com.zhm.spark.operator.serializable;
import scala.Serializable;
/**
* @ClassName User
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/29 11:32
* @Version 1.0
*/
public class User implements Serializable {
private String name;
private int age;
public User() {
}
public User(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
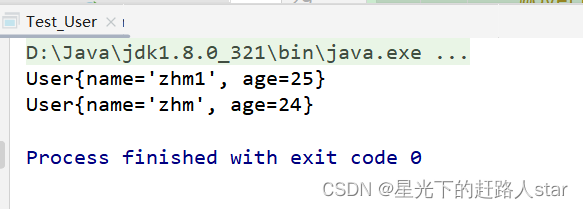
再次运行结果:
2.2 Kryo序列化框架
Java的序列化能够序列化任何的类。但是比较重,序列化后对象的体积也比较大。
Spark出于性能的考虑,Spark2.0开始支持另外一种Kryo序列化机制。Kryo速度是Serializable的10倍。当RDD在Shuffle数据的时候,简单数据类型、数组和字符串类型已经在Spark内部使用Kryo来序列化。
使用Kryo序列化框架的步骤
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore")
// 替换默认的序列化机制
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 注册需要使用kryo序列化的自定义类
.registerKryoClasses(new Class[]{
Class.forName("com.atguigu.bean.User")});
3、RDD依赖关系
3.1 查看血缘关系
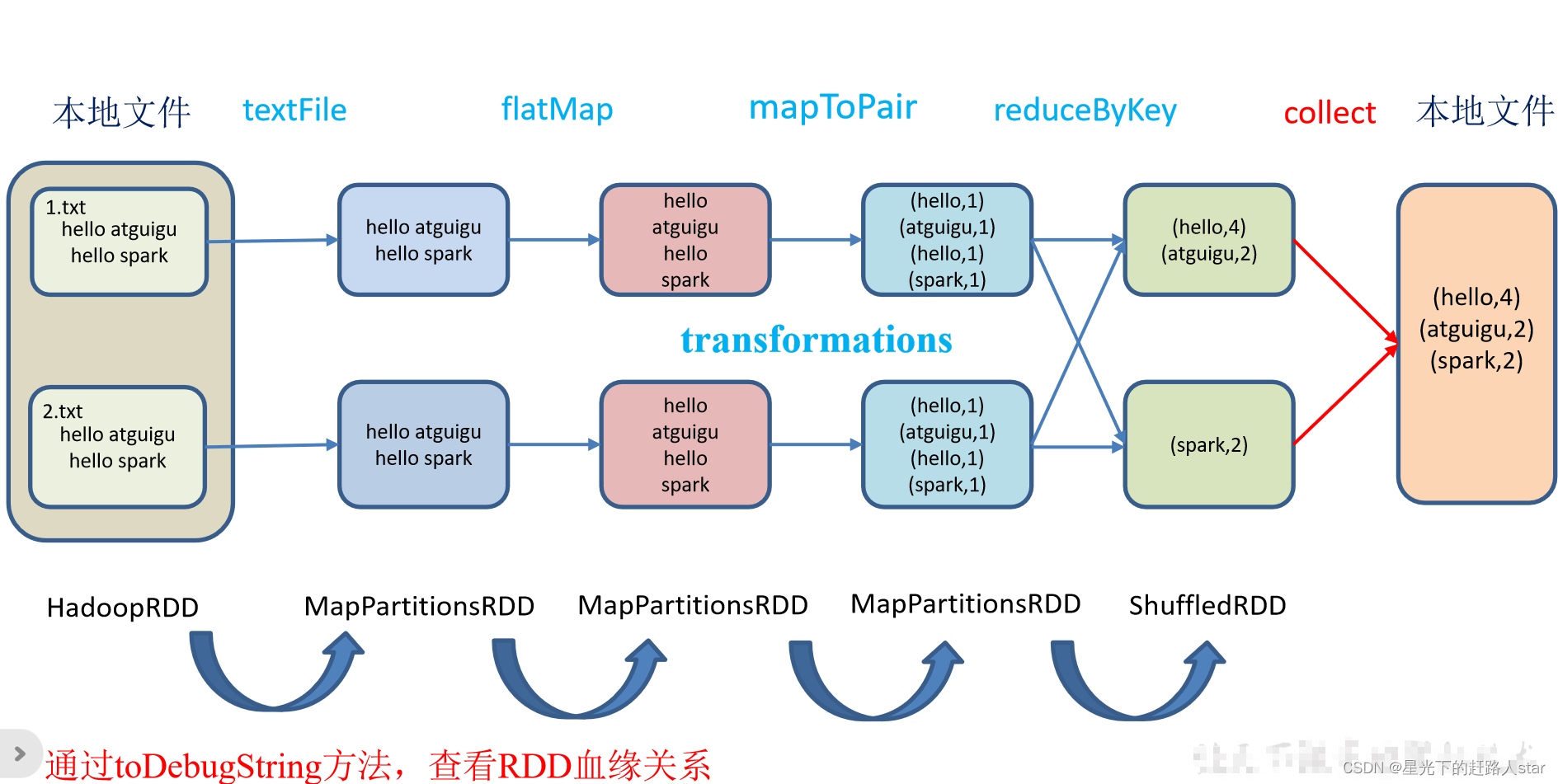
RDD只支持粗粒度转换,每一个转换操作都是对上游RDD的元素执行函数f得到一个新的RDD,所以RDD之间就会形成类似流水线的前后依赖关系。
将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算丢失的RDD的数据分区所依赖的父RDD分区数据以实现恢复,这样就避免了从头再次开始计算了。
1、创建包名com.zhm.spark.operator.dependency
2、代码实现
package com.zhm.spark.operator.dependency;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName Test01
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/29 11:41
* @Version 1.0
*/
public class Test01 {
/**
* 不Shuffle的转换算子都是MapPartitionsRDD
* 窄依赖:表示每一个父RDD的Partition最多被子RDD的一个Partition使用(独生子女)
*
* 宽依赖:表示同一个父RDD的Partition被多个子RDD的Partition依赖(超生)
* --sort、reduceByKey、groupByKey、join和调用rePartition函数 一般都是要Shuffle的算子
*
*
* Stage任务划分
* 1、DAG有向无环图
*
* RDD任务切分
* 分为:Application、Job、Stage和Task
* Application:初始化一个SparkContext即生成一个
* Job:应该Action算子就会生成一个Job
* Stage:等于宽依赖的个数加1
* Task:应该Stage阶段中,最后一个RDD的分区个数就是Task的个数
*
*/
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test01");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、创建RDD数据集
JavaRDD<String> sourceRDD = sparkContext.textFile("./input/word.txt");
//4、打印sourceRDD的血缘
System.out.println("--------------sourceRDD的血缘------------");
System.out.println(sourceRDD.toDebugString());
//5 炸裂RDD(flatMap)
JavaRDD<String> flatmapRDD = sourceRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.stream(s.split(" ")).iterator();
}
});
//6、打印flatmapRDD的血缘
System.out.println("--------------flatmapRDD的血缘------------");
System.out.println(flatmapRDD.toDebugString());
//7、转换为--->(word,1) mapToPair
JavaPairRDD<String, Integer> mapToPairRDD = flatmapRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s, 1);
}
});
//8、打印mapToPairRDD的血缘
System.out.println("--------------mapToPairRDD的血缘------------");
System.out.println(mapToPairRDD.toDebugString());
//9、统计每个单词的个数
JavaPairRDD<String, Integer> reduceByKeyRDD = mapToPairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
//8、打印reduceByKeyRDD的血缘
System.out.println("--------------reduceByKeyRDD的血缘--------------");
System.out.println(reduceByKeyRDD.toDebugString());
//9、收集打印
System.out.println("打印结果:\n");
reduceByKeyRDD.collect().forEach(System.out::println);
//x 关闭 sparkContext
sparkContext.stop();
}
}
运行结果:
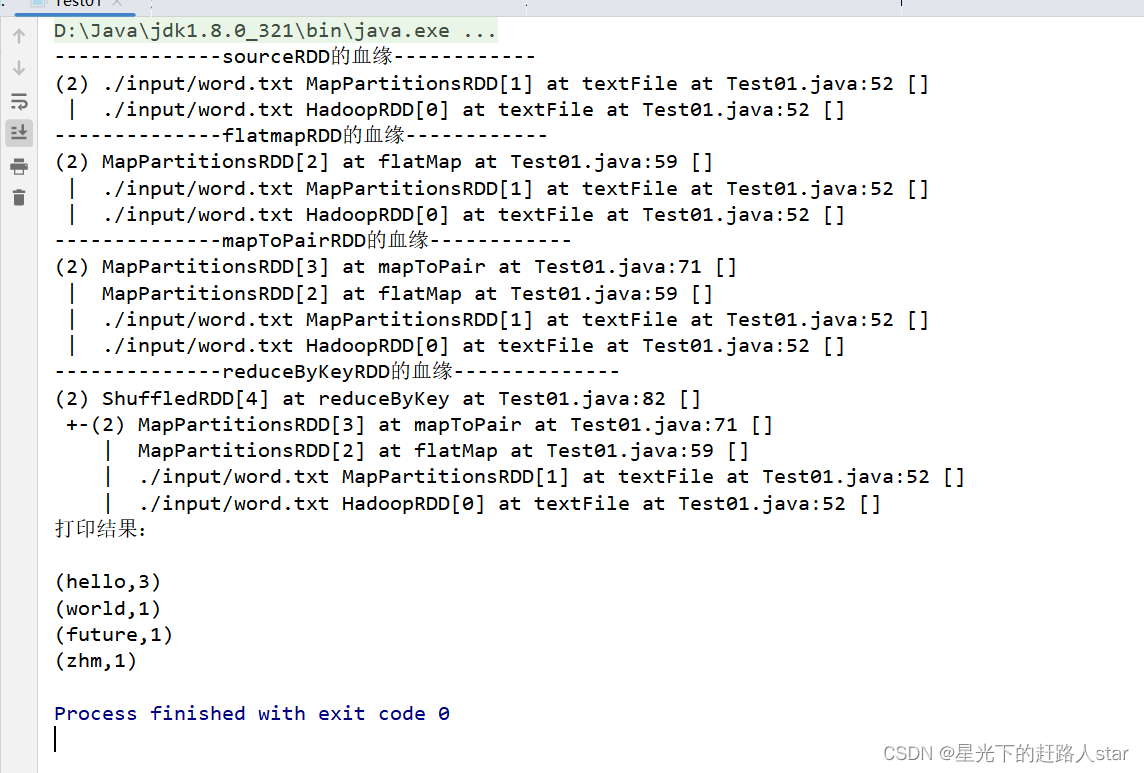
3.2 依赖关系
1、窄依赖:
(1)表示每一个父RDD的Partition最多被子RDD的一个Partition使用(一对一or多对一)
(2)窄依赖可以形象的比喻为独生子女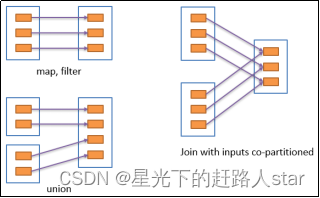
2、宽依赖
(1)表示同一个父RDD的Partition被多个子RDD的Partition依赖(只能是一对多),会引起Shuffle
(2)宽依赖可以形象的比喻为超生
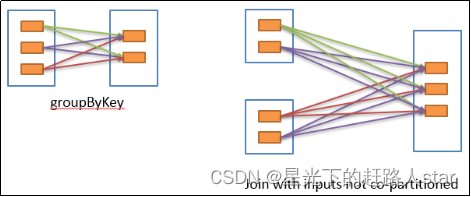
3、总结
(1)具有宽依赖的transformations包括:sort、reduceByKey、groupByKey、join和调用rePartition函数的任何操作
(2)宽依赖对Spark去评估一个transformatioins有更加重要的影响,比如对性能的影响。
(3)在不影响业务要求的情况下,要避免使用具有宽依赖的转换算子,因为宽依赖一定会走Shuffle,影响性能。
3.3 Stage任务划分
1、DAG有向无环图
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。
如下,DAG记录了RDD的转换过程和任务的阶段。
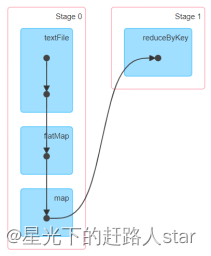
2、任务运行的整体流程
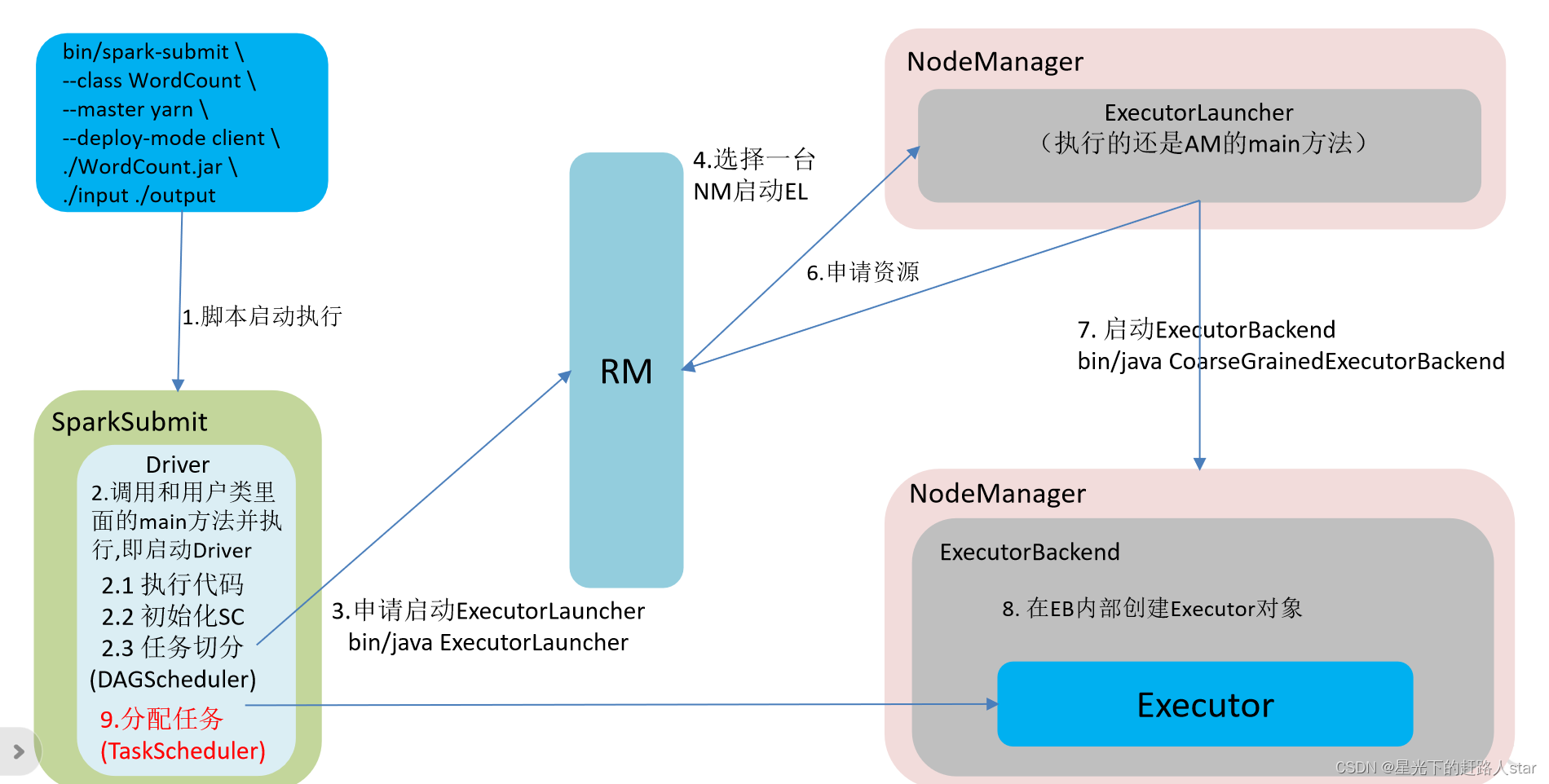
3、RDD任务切分
RDD的任务切分中分为:Application、Job、Stage和Task。
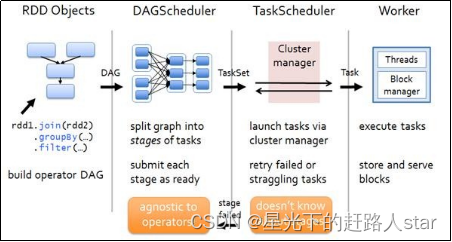
(1)Application:初始化一个SparkContext即生成一个
(2)Job:一个Action算子就会生成一个
(3)Stage:Stage等于宽依赖的个数+1
(4)Task:一个Stage中,最后一个RDD的分区个数就是Task的个数。
4、执行任务
再次运行Test01_dependency程序,添加上线程睡眠,方可查看job信息
##额外添加两个Action算子
reduceByKeyRDD.collect().forEach(System.out::println);
reduceByKeyRDD.collect().forEach(System.out::println);
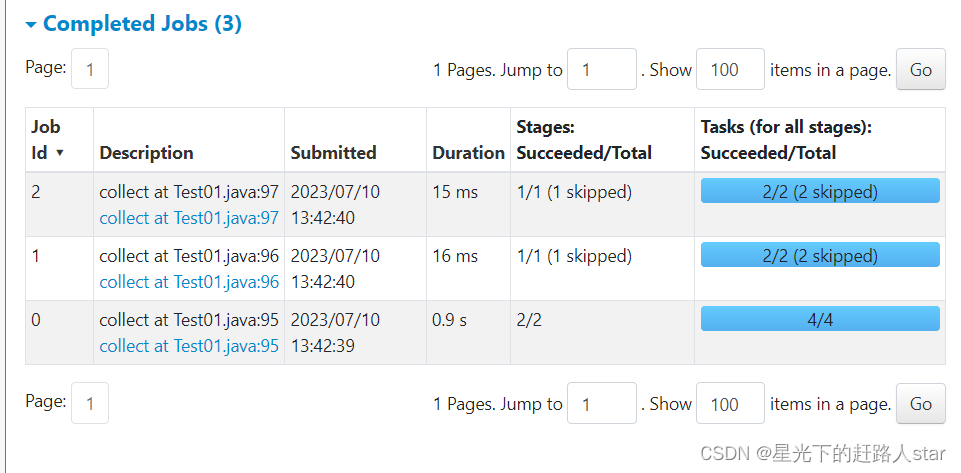
5、查看Job个数
查看http://localhost:4040/jobs/,发现Job有三个。
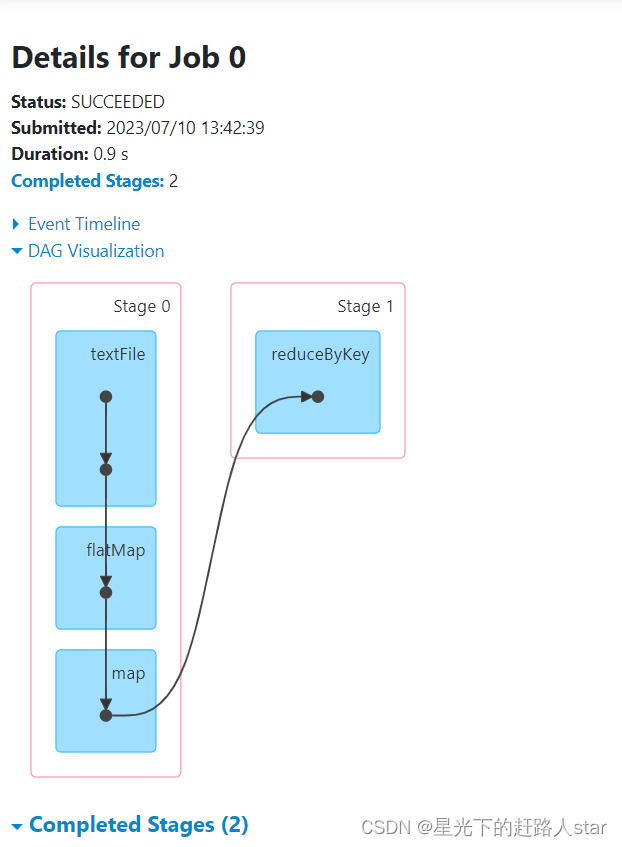
6、查看Stage个数
查看Job0的Stage。由于只有1个Shuffle阶段,所以Stage个数为2。
job1的
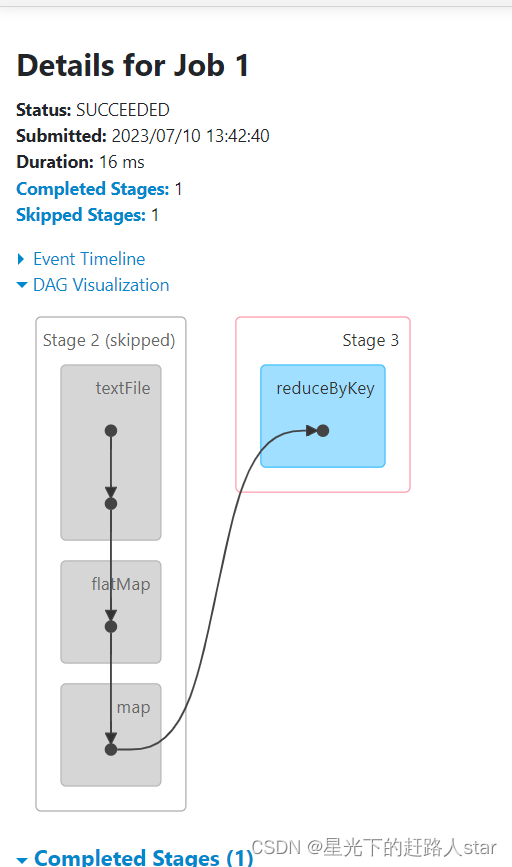
job2是和job1一样的
7、Task个数
都是两个
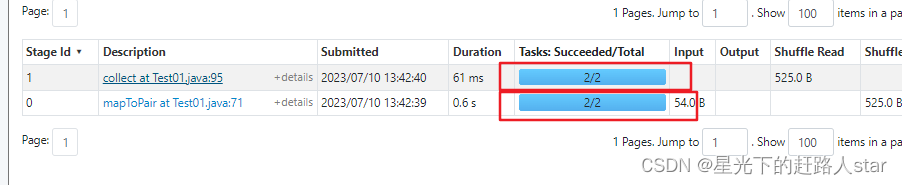
注意:如果存在shuffle过程,系统会自动进行缓存,UI界面显示skipped的部分。
4、RDD持久化
4.1 RDD Cache缓存
1、RDD Cache缓存
(1)RDD通过Cache或者persist方法将前面的计算结果缓存
(2)默认情况下会把数据以序列化的形式缓存在JVM的堆内存中。
(3)但是并不是这个两个方法被调用时立即缓存,而是触发后面的action算子时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
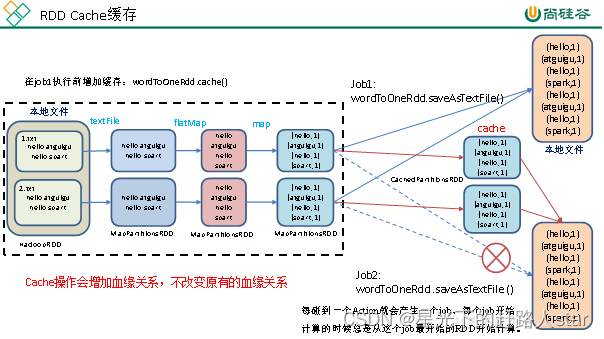
2、创建包名com.zhm.spark.operator.cache
3、未使用缓存代码实现
package com.zhm.spark.operator.cache;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName Test01_no_cache
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/29 13:58
* @Version 1.0
*/
public class Test01_no_cache {
public static void main(String[] args) throws InterruptedException {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test01");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、创建RDD数据集
JavaRDD<String> sourceRDD = sparkContext.textFile("./input/word.txt");
//4、炸裂每行数据
JavaRDD<String> flatMapRDD = sourceRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.stream(s.split(" ")).iterator();
}
});
//5、转换元素形式-->(word,1)
JavaPairRDD<String, Integer> mapToPairRDD = flatMapRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
System.out.println("你看我出现几次?");
return new Tuple2<>(s, 1);
}
});
//6、执行两个Action算子,以触发两个Job
mapToPairRDD.saveAsTextFile("output/1"+System.currentTimeMillis()+".txt");
mapToPairRDD.saveAsTextFile("output/2"+System.currentTimeMillis()+".txt");
//7、设置睡眠时间 以便查看localhost:4040
Thread.sleep(1000000L);
//x 关闭 sparkContext
sparkContext.stop();
}
}
4、运行结果:
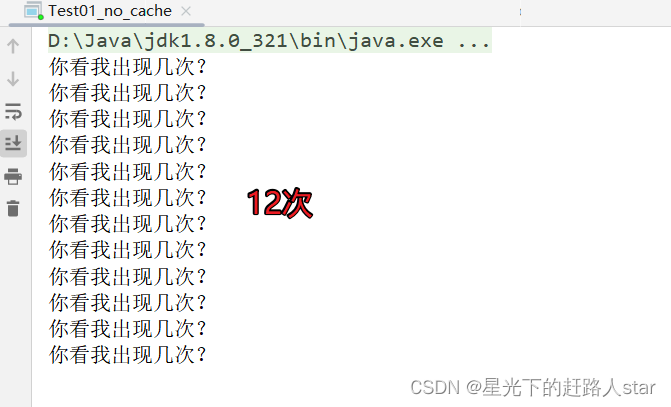
结论:一共输出12次,我们的RDD中有12条数据,每个job都执行一个flatMapRDD.map都会输出,所以是8次,也就意味着我们的两个job都会从头开始计算,直到最终的结果。
查看任务的WebUI
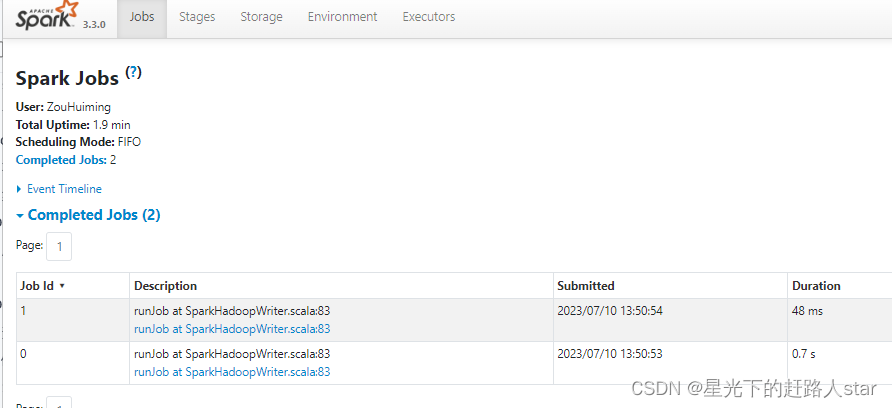
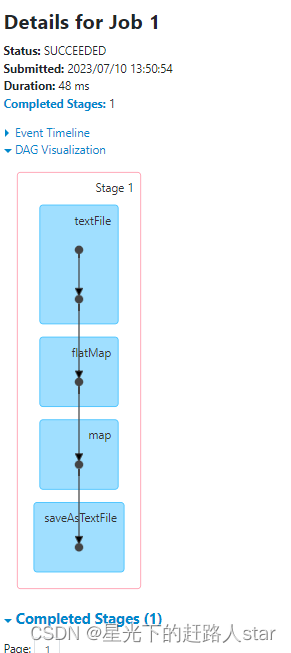
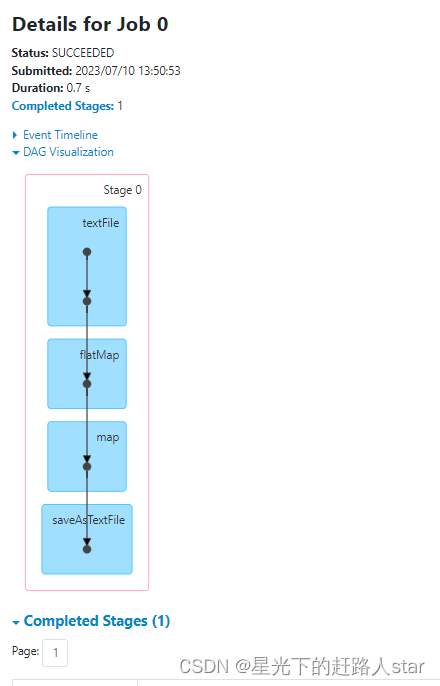
5、使用缓存代码实现
package com.zhm.spark.operator.cache;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName Test02_has_cache
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/29 14:08
* @Version 1.0
*/
public class Test02_has_cache {
/**
*自带缓存的算子:reduceByKey
*/
public static void main(String[] args) throws InterruptedException {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test01");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、创建RDD数据集
JavaRDD<String> sourceRDD = sparkContext.textFile("./input/word.txt");
//4、炸裂每行数据
JavaRDD<String> flatMapRDD = sourceRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.stream(s.split(" ")).iterator();
}
});
//5、转换元素形式-->(word,1)
JavaPairRDD<String, Integer> mapToPairRDD = flatMapRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
System.out.println("你看我出现几次?");
return new Tuple2<>(s, 1);
}
});
//将mapToPairRDD进行缓存
mapToPairRDD.cache();
//6、执行两个Action算子,以触发两个Job
mapToPairRDD.saveAsTextFile("output/1"+System.currentTimeMillis()+".txt");
mapToPairRDD.saveAsTextFile("output/2"+System.currentTimeMillis()+".txt");
//7、设置睡眠时间 以便查看localhost:4040
Thread.sleep(1000000L);
//x 关闭 sparkContext
sparkContext.stop();
}
}
注意:缓存的应用程序执行结束之后,缓存的目录也会被删除
6、运行结果
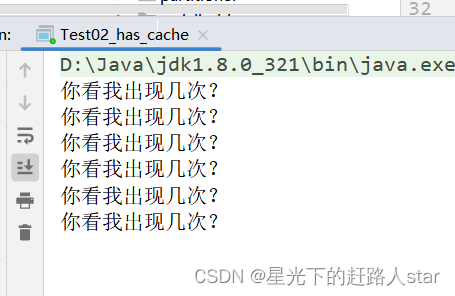
结论:我们对JavaPairRDD进行了缓存,那么也就第一个Job会从头到JavaPairRDD执行,而第二个则会从缓存中得到JavaPairRDD数据,继续自己的处理逻辑。
观察任务WebUI
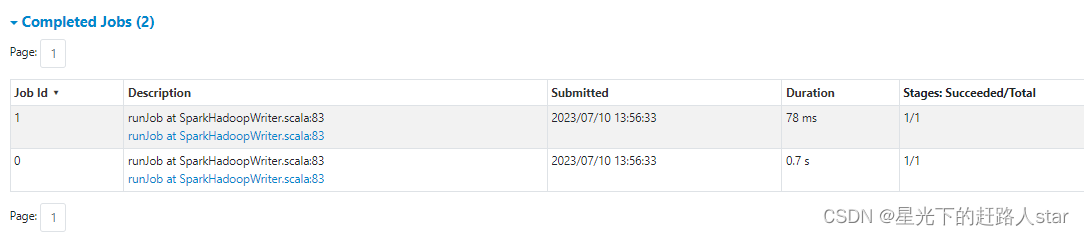
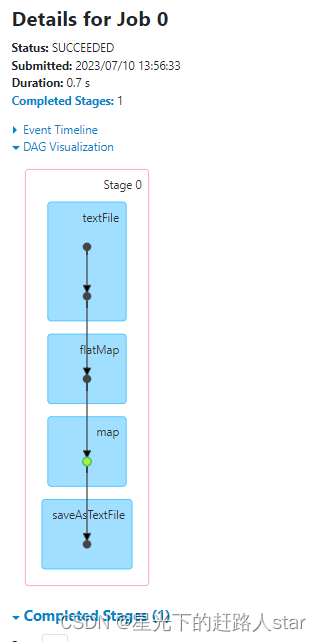
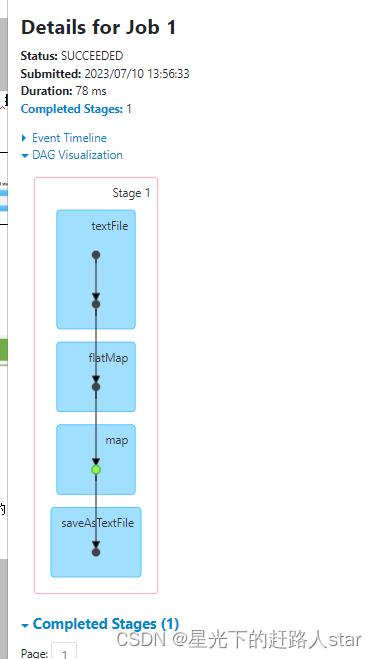
不同于未使用缓存的任务,本次job中再map出对javaPairRDD进行了缓存,途中绿色的点就表示缓存,鼠标停留到绿色点处会有提示。
7、缓存相关源码解析
mapRdd.cache()
def cache(): this.type = persist()
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
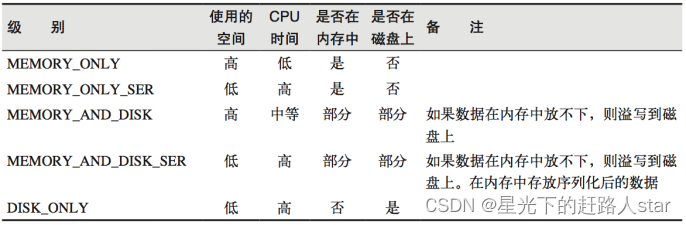
注意:默认的存储级别都是仅在内存存储一份。在存储级别的末尾加上“_2”表示持久化的数据存为两份。SER:表示序列化。
8、SparkRDD的安全问题和解决方案
(1)问题:缓存有可能会丢失,或者储存于内存的数据由于内存不足而被删除
(2)RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行
(3)原理:
通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算所有的Partition。
9、自带缓存算子
(1)Spark会自动对一些Shuffle操作的中间数据做持久化操作(别人ReduceByKey)。
(2)这样做的目的是为了当一个节点Shuffle失败了避免重新计算整个输入。
(3)但是,在时间使用的时候,如果想重用数据,仍然建议调用persist或Cache。
(4)编写具有自带缓存算子的代码
package com.zhm.spark.operator.cache;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName Test03_OperatorWithCache
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/29 14:19
* @Version 1.0
*/
public class Test03_OperatorWithCache {
public static void main(String[] args) throws InterruptedException {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test01");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、创建RDD数据集
JavaRDD<String> sourceRDD = sparkContext.textFile("input/word.txt");
//4、炸裂每行数据
JavaRDD<String> flatMapRDD = sourceRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.stream(s.split(" ")).iterator();
}
});
//5、转换元素形式-->(word,1)
JavaPairRDD<String, Integer> mapToPairRDD = flatMapRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
System.out.println("你看我出现几次?");
return new Tuple2<>(s, 1);
}
});
//6、对mapToPairRDD按照key聚合
JavaPairRDD<String, Integer> reduceByKeyRDD = mapToPairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
//7、执行两个行动算子
reduceByKeyRDD.saveAsTextFile("output/1"+System.currentTimeMillis()+".txt");
reduceByKeyRDD.saveAsTextFile("output/2"+System.currentTimeMillis()+".txt");
//8、设置睡眠时间 以便查看localhost:4040
Thread.sleep(1000000L);
//x 关闭 sparkContext
sparkContext.stop();
}
}
访问http://localhost:4040/jobs/页面,查看第一个和第二个job的DAG图。
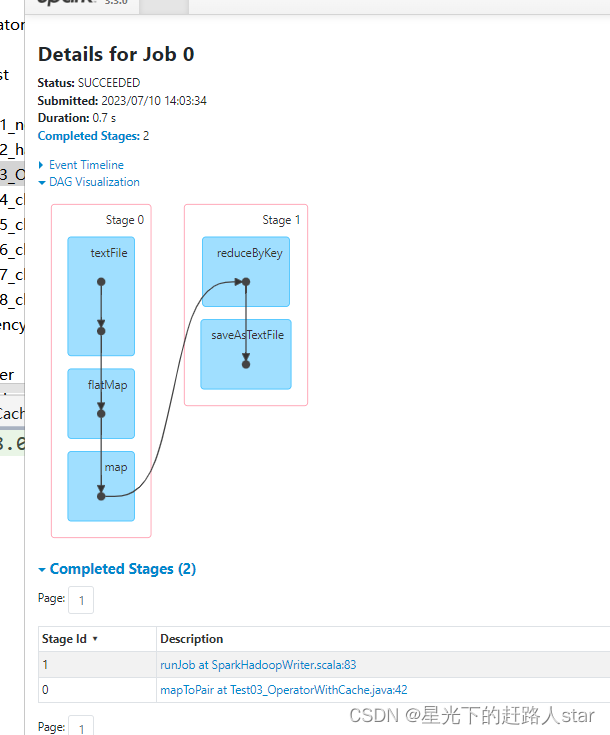
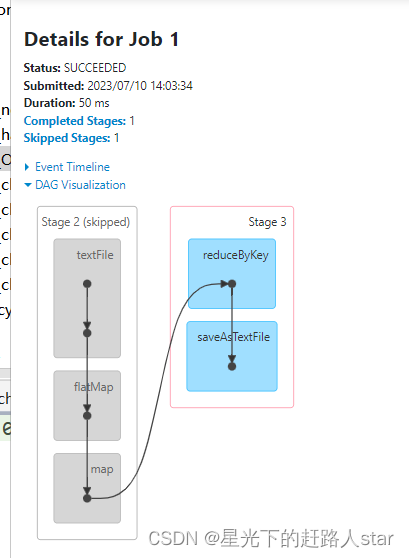
4.2 RDD CheckPoint检查点
1、检查点:是将RDD中间结果写入磁盘
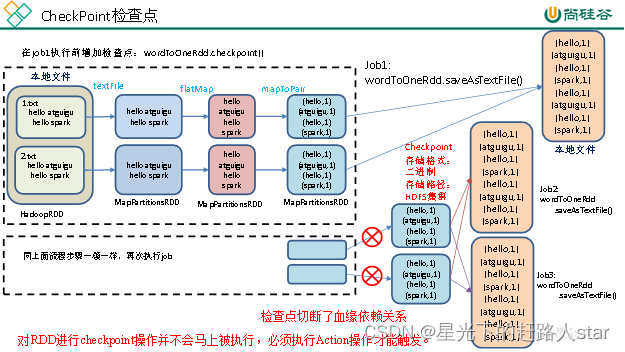
2、为什么要做检查点?
由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以就从检查点开始重做血缘,减少了开销。
3、检查点储存路径:Checkpoint的数据通常是储存在HDFS等容错、高可用的文件系统。
4、检查点数据储存格式为:二进制文件
5、检查点切断血缘:在Checkpoint的过程中,该RDD的所以依赖于父RDD的信息将全部被移除。
6、检查点触发时间:对RDD进行Checkpoint操作并不会马上执行,必须执行Action操作才能触发。但是检查点为了数据安全,会从血缘关系的最开始执行一遍。
7、设置检查点步骤
(1)设置检查点数据储存路径:sc.setCheckpointDir(“./checkpoint1”)
(2)调用检查点方法:wordToOneRdd.checkpoint()
8、代码实现
package com.zhm.spark.operator.cache;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName Test04_checkPoint
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/29 14:26
* @Version 1.0
*/
public class Test04_checkPoint {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test01");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//设置检查点储存路径
sparkContext.setCheckpointDir("output/checkPoint");
//3、创建RDD数据集
JavaRDD<String> sourceRDD = sparkContext.textFile("input/word.txt");
//4、炸裂每行数据
JavaRDD<String> flatMapRDD = sourceRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.stream(s.split(" ")).iterator();
}
});
//5、转换元素形式-->(word,1)
JavaPairRDD<String, Integer> mapToPairRDD = flatMapRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
System.out.println("你看我出现几次?");
return new Tuple2<>(s, 1);
}
});
//6、对mapToPairRDD设置检查点
mapToPairRDD.checkpoint();
//7、将数据储存到文件中
mapToPairRDD.saveAsTextFile("output/checkPoint/wordCount_"+System.currentTimeMillis()+".txt");
//x 关闭 sparkContext
sparkContext.stop();
}
}
9、执行结果:
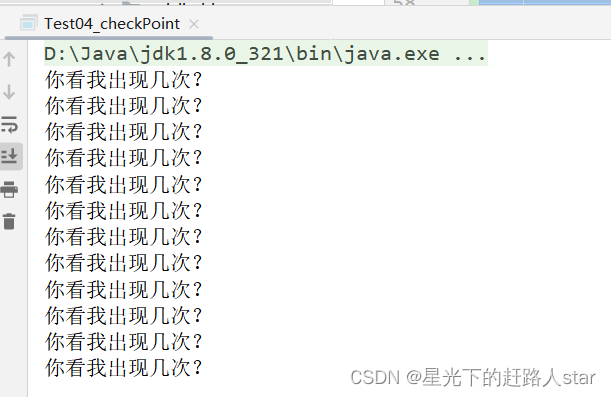
访问http://localhost:4040/jobs/
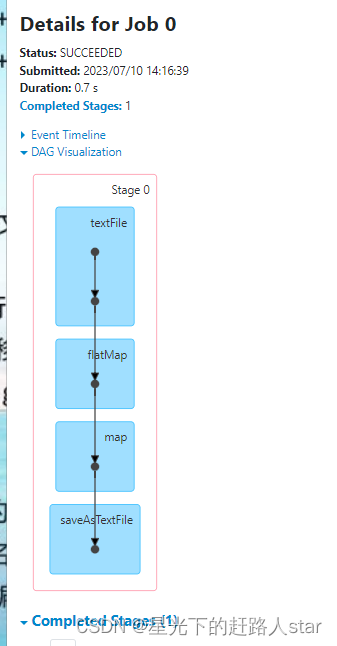
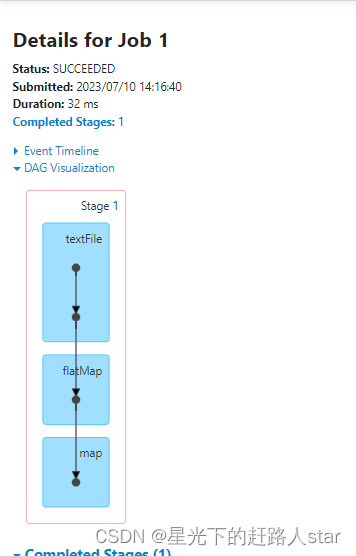
10、Checkpoint对血缘的一些
package com.zhm.spark.operator.cache;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName Test05_checkPoint_printLineage
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/29 15:12
* @Version 1.0
*/
public class Test05_checkPoint_printLineage {
public static void main(String[] args) throws InterruptedException {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test01");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//设置检查点储存路径
sparkContext.setCheckpointDir("output/checkpoint1");
//3、创建RDD数据集
JavaRDD<String> sourceRDD = sparkContext.textFile("input/word.txt");
//4、炸裂每行数据
JavaRDD<String> flatMapRDD = sourceRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.stream(s.split(" ")).iterator();
}
});
//5、转换元素形式-->(word,1)
JavaPairRDD<String, Integer> mapToPairRDD = flatMapRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
System.out.println("你看我出现几次?");
return new Tuple2<>(s, 1);
}
});
//6、在检查点之前答应血缘
System.out.println("在检查点之前打印血缘: ");
System.out.println(mapToPairRDD.toDebugString());
//7、对mapToPairRDD设置检查点
mapToPairRDD.checkpoint();
//8、将数据储存到文件中
mapToPairRDD.saveAsTextFile("output/checkPoint1/wordCount"+System.currentTimeMillis()+".txt");
//9、在检查点之后打印血缘
System.out.println("在检查点之后打印血缘: ");
System.out.println(mapToPairRDD.toDebugString());
Thread.sleep(10000000);
//x 关闭 sparkContext
sparkContext.stop();
}
}
运行结果:
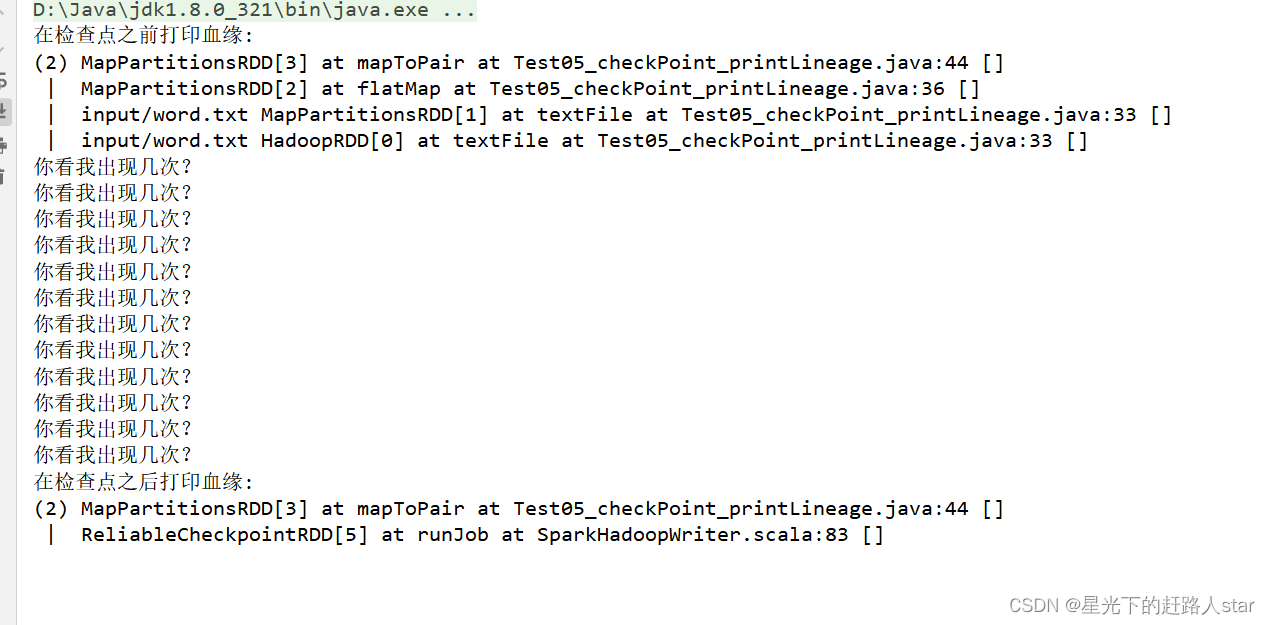
结论:血缘关系被切断了,因为Checkpoint机制是储存的数据很安全了,不用保留血缘依赖。
11、Checkpoint对数据的影响
package com.zhm.spark.operator.cache;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName Test06_check_influence_data
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/29 15:21
* @Version 1.0
*/
public class Test06_check_influence_data {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test01");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//设置检查点储存路径
sparkContext.setCheckpointDir("output/checkpoint3");
//3、创建RDD数据集
JavaRDD<String> sourceRDD = sparkContext.textFile("input/word.txt");
//4、炸裂每行数据
JavaRDD<String> flatMapRDD = sourceRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.stream(s.split(" ")).iterator();
}
});
//5、转换元素形式-->(word,当前时间)
JavaPairRDD<String, Long> mapToPairRDD = flatMapRDD.mapToPair(new PairFunction<String, String, Long>() {
@Override
public Tuple2<String, Long> call(String s) throws Exception {
System.out.println("你看我出现几次?");
return new Tuple2<>(s, System.currentTimeMillis());
}
});
//6、checkpoint前收集打印
System.out.println("checkpoint前收集打印:");
mapToPairRDD.collect().forEach(System.out::println);
//7、对mapToPairRDD设置检查点
mapToPairRDD.checkpoint();
//6、checkpoint后收集打印
System.out.println("checkpoint前收集打印:");
mapToPairRDD.collect().forEach(System.out::println);
//x 关闭 sparkContext
sparkContext.stop();
}
}
运行结果:
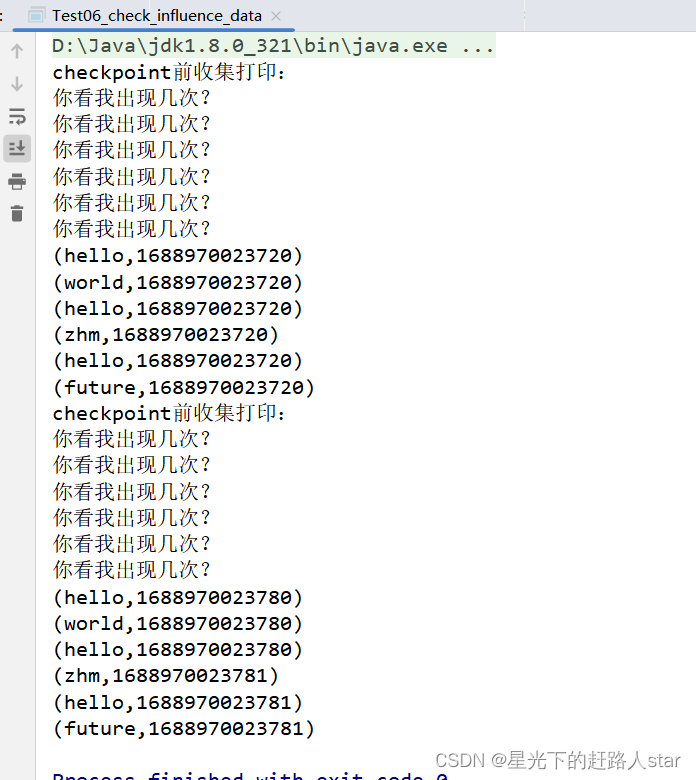
现象:由于Checkpoint要从头再执行一遍,这种与时间相关的就会造成数据不一致。
12、Checkpoint检查点+Cache缓存
package com.zhm.spark.operator.cache;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName Test07_checkPoint_with_cache
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/29 15:27
* @Version 1.0
*/
public class Test07_checkPoint_with_cache {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test01");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//设置检查点储存路径
sparkContext.setCheckpointDir("output/checkpoint4");
//3、创建RDD数据集
JavaRDD<String> sourceRDD = sparkContext.textFile("input/word.txt");
//4、炸裂每行数据
JavaRDD<String> flatMapRDD = sourceRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.stream(s.split(" ")).iterator();
}
});
//5、转换元素形式-->(word,当前时间)
JavaPairRDD<String, Long> mapToPairRDD = flatMapRDD.mapToPair(new PairFunction<String, String, Long>() {
@Override
public Tuple2<String, Long> call(String s) throws Exception {
System.out.println("你看我出现几次?");
return new Tuple2<>(s, System.currentTimeMillis());
}
});
//缓存
mapToPairRDD.cache();
//6、checkpoint前收集打印
System.out.println("checkpoint前收集打印:");
mapToPairRDD.collect().forEach(System.out::println);
//7、对mapToPairRDD设置检查点
mapToPairRDD.checkpoint();
//6、checkpoint后收集打印
System.out.println("checkpoint后收集打印:");
mapToPairRDD.collect().forEach(System.out::println);
//x 关闭 sparkContext
sparkContext.stop();
}
}
运行结果:
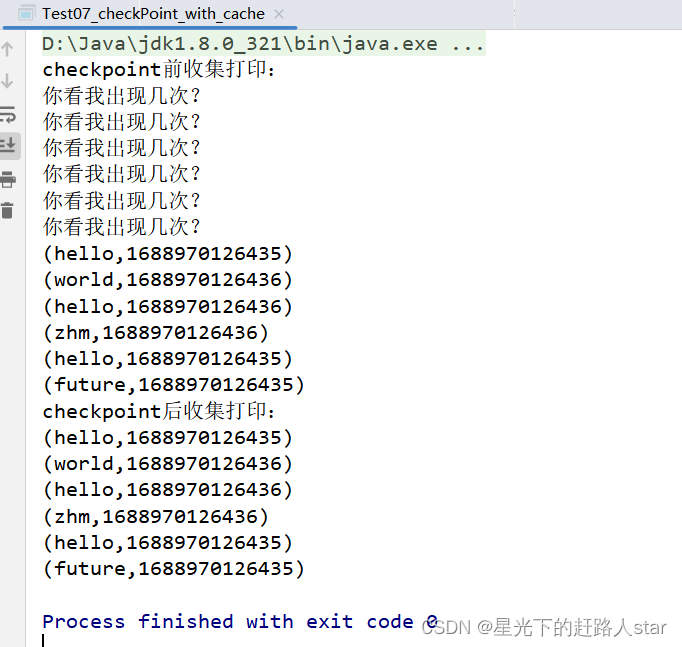
结论:保持了数据的一致性
4.3缓存和检查点的区别
1、Cache缓存只是将数据保存起来,不切断血缘依赖.Checkpoint检查点切断血缘依赖
2、Cache缓存的数据通常储存在磁盘、内存等地方,可靠性低。Checkpoint的数据通常储存在HDFS等容错、高可用的文件系统,可靠性高。
3、建议对Checkpoint的RDD使用Cache缓存,这样Checkpoint的job只需要从Cache缓存中读取数据即可,否者需要再从头计算一次RDD。
4、如果使用完了缓存,可以通过unpersist方法是否缓存。
4.4. 检查点储存到HDFS集群
注意:如果检查点数据储存到HDFS集群,要注意配置访问集群的用户名。否者会报访问权限异常。
package com.zhm.spark.operator.cache;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName Test08_checkpoint_hdfs
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/29 15:30
* @Version 1.0
*/
public class Test08_checkpoint_hdfs {
public static void main(String[] args) {
//0、设置hadoop用户
System.setProperty("HADOOP_USER_NAME","zhm");
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test01");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//设置检查点储存路径
sparkContext.setCheckpointDir("hdfs://hadoop102:8020/sparkCheckPoint");
//3、创建RDD数据集
JavaRDD<String> sourceRDD = sparkContext.textFile("input/word.txt");
//4、炸裂每行数据
JavaRDD<String> flatMapRDD = sourceRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.stream(s.split(" ")).iterator();
}
});
//5、转换元素形式-->(word,1)
JavaPairRDD<String, Integer> mapToPairRDD = flatMapRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
System.out.println("你看我出现几次?");
return new Tuple2<>(s, 1);
}
});
//6、对mapToPairRDD设置检查点
mapToPairRDD.checkpoint();
//7、将数据储存到文件中
mapToPairRDD.saveAsTextFile("output/checkPoint5/wordCount_"+System.currentTimeMillis()+".txt");
//x 关闭 sparkContext
sparkContext.stop();
}
}