Spark中RDD有transform和action两种类型的算子操作,transform会生成一个子RDD,子RDD与之前的父RDD之间存在依赖关系,目前有两种依赖关系:NarrowDependency和ShuffleDependency。NarrowDependency又分为OneToOneDependency和RangeDependency两种。现在来看下org.apache.spark.Dependency.class源码。
1. Dependency
/**
* :: DeveloperApi ::
* Base class for dependencies.
* 依赖的基类
*/
@DeveloperApi
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}2. NarrowDependency
/**
* :: DeveloperApi ::
* Base class for dependencies where each partition of the child RDD depends on a small number
* of partitions of the parent RDD. Narrow dependencies allow for pipelined execution.
*/
@DeveloperApi
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
/**
* Get the parent partitions for a child partition.
* @param partitionId a partition of the child RDD
* @return the partitions of the parent RDD that the child partition depends upon
* 得到子RDD的某个partition依赖父RDD的所有partitions
*/
def getParents(partitionId: Int): Seq[Int]
override def rdd: RDD[T] = _rdd
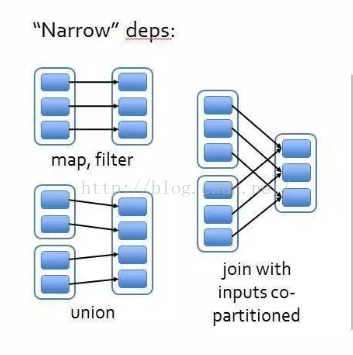
}从源码中可以看到NarrowDependency是指子RDD的每个分区依赖少量(一个或多个)父RDD分区,也可以说一个父RDD的partition至多被子RDD的某个partition使用一次。NarrowDependency允许pipeline操作。
2.1 OneToOneDependency
OneToOneDependency指的是子RDD的每个partition只依赖父RDD的一个partition。产生OneToOneDependency的算子有map、filter、flatMap等。现在来看下OneToOneDependency源码。
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between partitions of the parent and child RDDs.
*/
@DeveloperApi
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId)
}2.2 RangeDependency
RangeDependency指的是子RDD的每个partition依赖多个父RDD的一个partition。
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between ranges of partitions in the parent and child RDDs.
* @param rdd the parent RDD
* @param inStart the start of the range in the parent RDD
* @param outStart the start of the range in the child RDD
* @param length the length of the range
*/
@DeveloperApi
class RangeDependency[T](rdd: RDD[T], inStart: Int, outStart: Int, length: Int)
extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = {
// 子RDDpartitionId >= 子RDD依赖partition range的开始位置 && 子RDDpartitionId < 子RDD依赖partition range结束位置
if (partitionId >= outStart && partitionId < outStart + length) {
// partitionId - outStart表示子RDD的partitionId所在的相对位置
List(partitionId - outStart + inStart)
} else {
Nil
}
}
}3. ShuffleDependency
ShuffleDependency表示一个父RDD的partition会被子RDD的partition使用多次下图表示了ShuffleDependency的示例。

/**
* :: DeveloperApi ::
* Represents a dependency on the output of a shuffle stage. Note that in the case of shuffle,
* the RDD is transient since we don't need it on the executor side.
*
* @param _rdd the parent RDD
* @param partitioner partitioner used to partition the shuffle output
* @param serializer [[org.apache.spark.serializer.Serializer Serializer]] to use. If set to None,
* the default serializer, as specified by `spark.serializer` config option, will
* be used.
* @param keyOrdering key ordering for RDD's shuffles
* @param aggregator map/reduce-side aggregator for RDD's shuffle
* @param mapSideCombine whether to perform partial aggregation (also known as map-side combine)
*/
@DeveloperApi
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Option[Serializer] = None,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]] {
override def rdd: RDD[Product2[K, V]] = _rdd.asInstanceOf[RDD[Product2[K, V]]]
private[spark] val keyClassName: String = reflect.classTag[K].runtimeClass.getName
private[spark] val valueClassName: String = reflect.classTag[V].runtimeClass.getName
// Note: It's possible that the combiner class tag is null, if the combineByKey
// methods in PairRDDFunctions are used instead of combineByKeyWithClassTag.
private[spark] val combinerClassName: Option[String] =
Option(reflect.classTag[C]).map(_.runtimeClass.getName)
val shuffleId: Int = _rdd.context.newShuffleId()
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.size, this)
_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
}ShuffleDependency需要经过shuffle过程才能形成,而shuffle都是基于 PairRDD进行的,所以传入的RDD需要是key-value类型的。newShuffleId的作用是得到唯一的shufflId(每次加1)。
这儿有的地方还不是特别明白,希望大家能发表自己的意见。