什么是图
图是一种非常强大的数据结构,图是由顶点的有穷非空集合和顶点之间边的集合组成,通
常表示为:G(V,E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合。
当我们需要处理多对多这么一种关系时,我们就可以建立一张图来解决。图中的顶点是我
们的数据元素(线性表中我们把数据元素叫元素,树中叫结点,在图中数据元素我们则称
之为顶点),边就是这些研究对象之间的关系,通常称之为权重,具体应用中会有不同。
怎么存储图
邻接矩阵
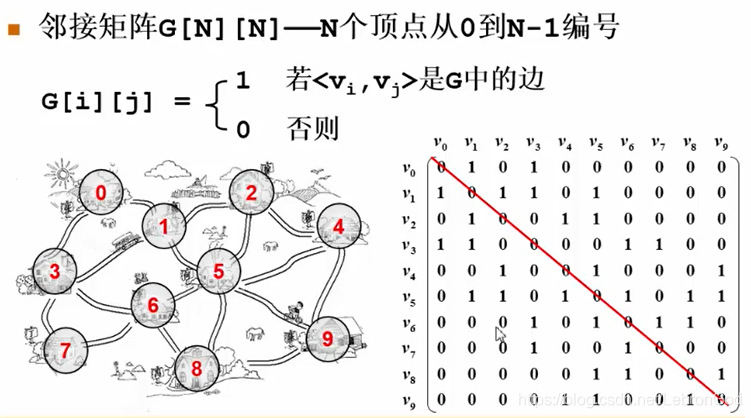
用一个二维数组存放节点,节点之间有边的就把对应的数组元素赋值位1,代表存在。
邻接矩阵的好处就是能够直观的看到那些边之间存在关系,便于查询(只要输入你要查询
的两个顶点值便可以确定他在这个二维数组当中的位置),计算每一个顶点的入度或出度
时只需遍历一遍即可。
代码实现邻接矩阵构建图:

但我们不难发现这个二维数组沿红线分开的两部分是完全对称的,且红线上的值都为0(自
己到自己肯定是没有边的啦),精打细算的我们就会想能不能那一半不用可以节省点空间
啊!

于是我们有了上面这个解决方案,他优化了邻接矩阵的空间复杂度,但他也制造了一些不
便,变成一个一维数组来存储之后,查询是否存在边变得没那么容易,如果我们要查询点
Vi与Vj之间有没有边就要查询a[i*(i+1)/2+j]了。但无论怎样还是节省了空间。
我们知道建立一个邻接矩阵就是为了存储一个图当中的关联关系,就是我们的边,矩阵中
为1的就代表着有边,但如果便很少一个矩阵里面大部分都是0,如果边多还好说,用了不
亏嘛,但这个点多边还少那肯定会导致大量的空间浪费(几万个点我就存两条边),所以
聪明的我们又想到了链表。
邻接表
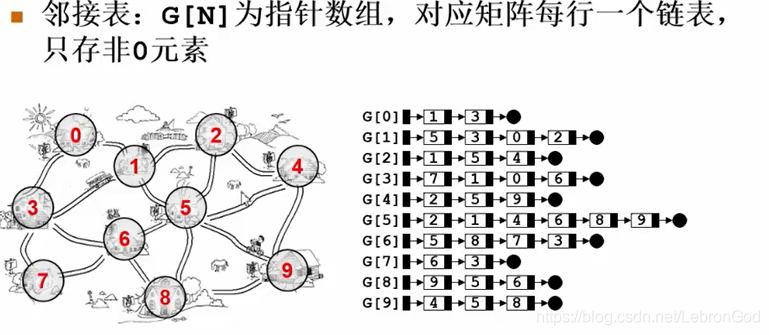
对于所有的顶点我们都建立一个指针构成一个指针数组,将与其有关的顶点连接至他的
next指针,这样就形成了邻接表,邻接表只存有关系的,当我们面对一个稀疏图时,邻接
表便显得那么的简洁。对于带权值的网图,可以在边表结点定义中再增加一个数据域来存
储权值即可。邻接表还能很方便的找到任一顶点的邻接点。
但邻接表也是有缺点的,在零阶矩阵当中我们表示边的存在时用的是1来表示他只占了一个
字节,但在邻接表里如果两点之间存在边,他既会出现在Vi的单链表里还会出现在VJ
里,而且我们不仅要存一个数据域,还要有一个指针域,如果带有权重还得要有一个数据
域,那样就占用了三个字节了。在用邻接表存储图后,计算出度入度对于无向图是和邻接
矩阵无异的,遍历一边即可,但对于无向图而言,还需要再建立一个逆邻接表才能实现,
所以,要用邻接表的话,一定要稀疏才合算啊。
图的遍历
我们存储完一个图之后,我们肯定要取用他,图怎么用,那就是遍历,图的遍历分为DFS和BFS。

深度优先顾名思义就是优先往深的地方走(一条路走到黑),直到走不下去或者达到终点
他才会终止,其实这里面也是用到了一个递归,当碰到不能走之后,它会返回他的上一层
往另一个方向继续搜索。
代码实现:
void dfs(int x, int y, int step)
{
if(mp[x][y]=='D'&&step==T)
{
flag=1;
return;
}
vis[x][y]=1;
for(int i=0;i<4;++i)
{
int x1=x+dir[i][0];
int y1=y+dir[i][1];
if(in(x1,y1)&&mp[x1][y1]!='X'&&!vis[x1][y1])
{
vis[x1][y1]=1;
dfs(x1,y1,step+1);
if(flag)
return ;
vis[x1][y1]=0;
}
}
}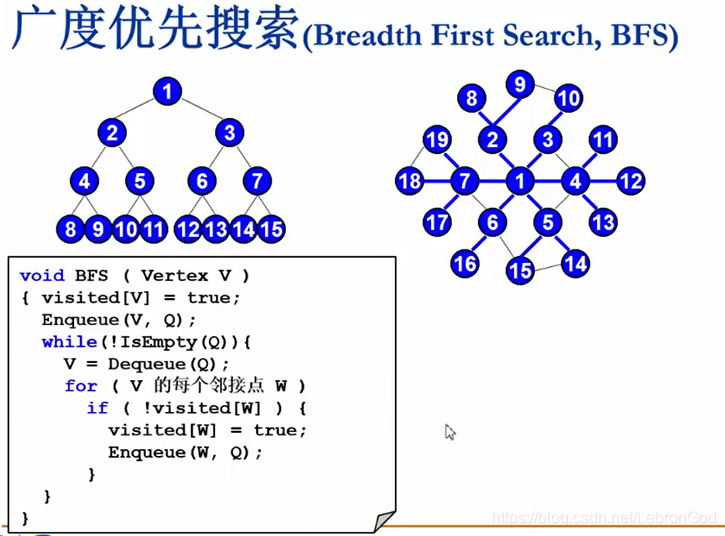
广度优先搜索是一圈一圈往外搜的,所以我们在这个地方用队列来实现,从起点出发将与
其相关的顶点入队,将自己出队,不断重复操直至所有顶点出队,或找到符合条件终止。
代码实现:
void bfs(struct node start)
{
Q.push(start);
book[start.x][start.y]=1;
while(!Q.empty())
{
struct node now=Q.front();
Q.pop();
if(now.step>0&&(now.x==1||now.x==n||now.y==1||now.y==m))
{
ans=now.step;
return;
}
for(int i=0; i<4;i++)
{
struct node neww;
neww.x=now.x+dir[i][0];
neww.y=now.y+dir[i][1];
neww.step=0;
if(neww.x>0&&neww.x<=n&&neww.y>0&&neww.y<=m&&!book[neww.x][neww.y]&&mp[neww.x][neww.y]=='.')
{
book[neww.x][neww.y]=1;
if(now.step>0)
neww.step=now.step+1;
Q.push(neww);
}
}
}
}dfs空间复杂度小于bfs,bfs的时间复杂度小于dfs
dfs与bfs可谓各有千秋吧(不过我们好像更加关注的是时间复杂度,bfs用的还是要多一点啊)
