转载https://www.cnblogs.com/ysocean/p/8032659.html
图的定义
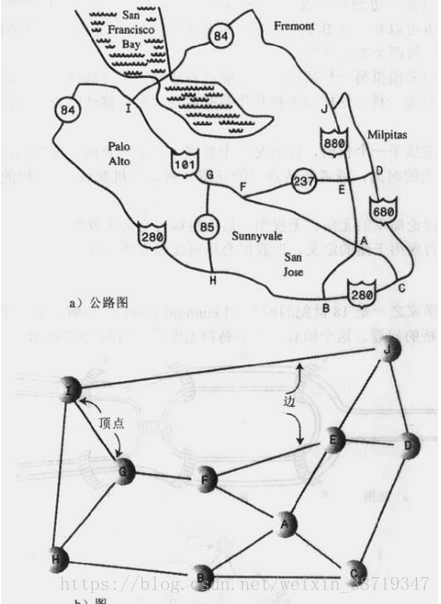
- 在程序中表示图
- 顶点:
在大多数情况下,顶点表示某个真实世界的对象,这个对象必须用数据项来描述。比如在一个飞机航线模拟程序中,顶点表示城市,那么它需要存储城市的名字、海拔高度、地理位置和其它相关信息,因此通常用一个顶点类的对象来表示一个顶点,这里我们仅仅在顶点中存储了一个字母来标识顶点,同时还有一个标志位,用来判断该顶点有没有被访问过(用于后面的搜索)。
/**
* 顶点类
* @author vae
*/
public class Vertex {
public char label;
public boolean wasVisited;
public Vertex(char label){
this.label = label;
wasVisited = false;
}
}顶点对象能放在数组中,然后用下标指示,也可以放在链表或其它数据结构中,不论使用什么结构,存储只是为了使用方便,这与边如何连接点是没有关系的。
- 邻接矩阵: 邻接矩阵是一个二维数组,数据项表示两点间是否存在边,如果图中有 N 个顶点,邻接矩阵就是 N*N 的数组。
- 邻接表:邻接表是一个链表数组(或者是链表的链表),每个单独的链表表示了有哪些顶点与当前顶点邻接。
搜索
在图中实现最基本的操作之一就是搜索从一个指定顶点可以到达哪些顶点,比如从武汉出发的高铁可以到达哪些城市,一些城市可以直达,一些城市不能直达。现在有一份全国高铁模拟图,要从某个城市(顶点)开始,沿着铁轨(边)移动到其他城市(顶点),有两种方法可以用来搜索图:深度优先搜索(DFS)和广度优先搜索(BFS)。它们最终都会到达所有连通的顶点,深度优先搜索通过栈来实现,而广度优先搜索通过队列来实现,不同的实现机制导致不同的搜索方式。
①、深度优先搜索(DFS)
深度优先搜索算法有如下规则:
规则1:如果可能,访问一个邻接的未访问顶点,标记它,并将它放入栈中。
规则2:当不能执行规则 1 时,如果栈不为空,就从栈中弹出一个顶点。
规则3:如果不能执行规则 1 和规则 2 时,就完成了整个搜索过程。
对于上图,应用深度优先搜索如下:假设选取 A 顶点为起始点,并且按照字母优先顺序进行访问,那么应用规则 1 ,接下来访问顶点 B,然后标记它,并将它放入栈中;再次应用规则 1,接下来访问顶点 F,再次应用规则 1,访问顶点 H。我们这时候发现,没有 H 顶点的邻接点了,这时候应用规则 2,从栈中弹出 H,这时候回到了顶点 F,但是我们发现 F 也除了 H 也没有与之邻接且未访问的顶点了,那么再弹出 F,这时候回到顶点 B,同理规则 1 应用不了,应用规则 2,弹出 B,这时候栈中只有顶点 A了,然后 A 还有未访问的邻接点,所有接下来访问顶点 C,但是 C又是这条线的终点,所以从栈中弹出它,再次回到 A,接着访问 D,G,I,最后也回到了 A,然后访问 E,但是最后又回到了顶点 A,这时候我们发现 A没有未访问的邻接点了,所以也把它弹出栈。现在栈中已无顶点,于是应用规则 3,完成了整个搜索过程。深度优先搜索在于能够找到与某一顶点邻接且没有访问过的顶点。这里以邻接矩阵为例,找到顶点所在的行,从第一列开始向后寻找值为1的列;列号是邻接顶点的号码,检查这个顶点是否未访问过,如果是这样,那么这就是要访问的下一个顶点,如果该行没有顶点既等于1(邻接)且又是未访问的,那么与指定点相邻接的顶点就全部访问过了(后面会用算法实现)。
②、广度优先搜索(BFS):
深度优先搜索要尽可能的远离起始点,而广度优先搜索则要尽可能的靠近起始点,它首先访问起始顶点的所有邻接点,然后再访问较远的区域,这种搜索不能用栈实现,而是用队列实现。规则1:访问下一个未访问的邻接点(如果存在),这个顶点必须是当前顶点的邻接点,标记它,并把它插入到队列中。
规则2:如果已经没有未访问的邻接点而不能执行规则 1 时,那么从队列列头取出一个顶点(如果存在),并使其成为当前顶点。
规则3:如果因为队列为空而不能执行规则 2,则搜索结束。
对于上面的图,应用广度优先搜索:以A为起始点,首先访问所有与 A 相邻的顶点,并在访问的同时将其插入队列中,现在已经访问了 A,B,C,D和E。这时队列(从头到尾)包含 BCDE,已经没有未访问的且与顶点 A 邻接的顶点了,所以从队列中取出B,寻找与B邻接的顶点,这时找到F,所以把F插入到队列中。已经没有未访问且与B邻接的顶点了,所以从队列列头取出C,它没有未访问的邻接点。因此取出 D 并访问 G,D也没有未访问的邻接点了,所以取出E,现在队列中有 FG,在取出 F,访问 H,然后取出 G,访问 I,现在队列中有 HI,当取出他们时,发现没有其它为访问的顶点了,这时队列为空,搜索结束。
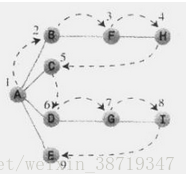
程序实现
https://www.cnblogs.com/ysocean/p/8032659.html
总结
图是由边连接的顶点组成,图可以表示许多真实的世界情况,包括飞机航线、电子线路等等。搜索算法以一种系统的方式访问图中的每个顶点,主要通过深度优先搜索(DFS)和广度优先搜索(BFS),深度优先搜索通过栈来实现,广度优先搜索通过队列来实现。最后需要知道最小生成树是包含连接图中所有顶点所需要的最少数量的边。