YOLO这个模型虽然我不会拿来用,但YOLO2还是不错的。所以还是把YOLO做个简单的了解吧。
注意:这并不是详解!
1. Introduction
YOLO相对于基于Region proposal的模型来说,不同之处在于直接在图像上做检测和分类。因为region proposal比较费时间,无法做到real-time。所以YOLO把这个给砍掉了。当然,YOLO这种方法虽然保证了实时速度很快,但精度做了很大的牺牲。
基本流程为:
1.resize image to 448 x 448,输入到网络中。(YOLO要求图像是方形,因为最后是利用7 x 7的张量来表示分类值和位置值等)
2.运行卷积神经网络,输出 7x7x30的张量。每一个格网表示2个bbox的预测值。没错,YOLO中,总共只输出98个bbox,是不是很吃鸡。
3.非极大值抑制。虽然bbox少,但也是有重叠的情况,所以要pass掉分数低的。
具体的解释看下面。
2.YOLO
YOLO在input image前,将image划分成7 x 7的格网。
引用一下参考文献[1]中的图。

如果一个物体的中心落在某个格网内,则这个格网负责检测这个物体。
物体的中心怎么知道在哪呢?笔者认为训练时可以通过GT获取。(当然,测试时是没有的)
如图,dog的中心在(5,2)这个位置,这个位置就负责dog的训练。
测试时,是由每个格网生成2个bbox,一共98个bbox,进行回归的。
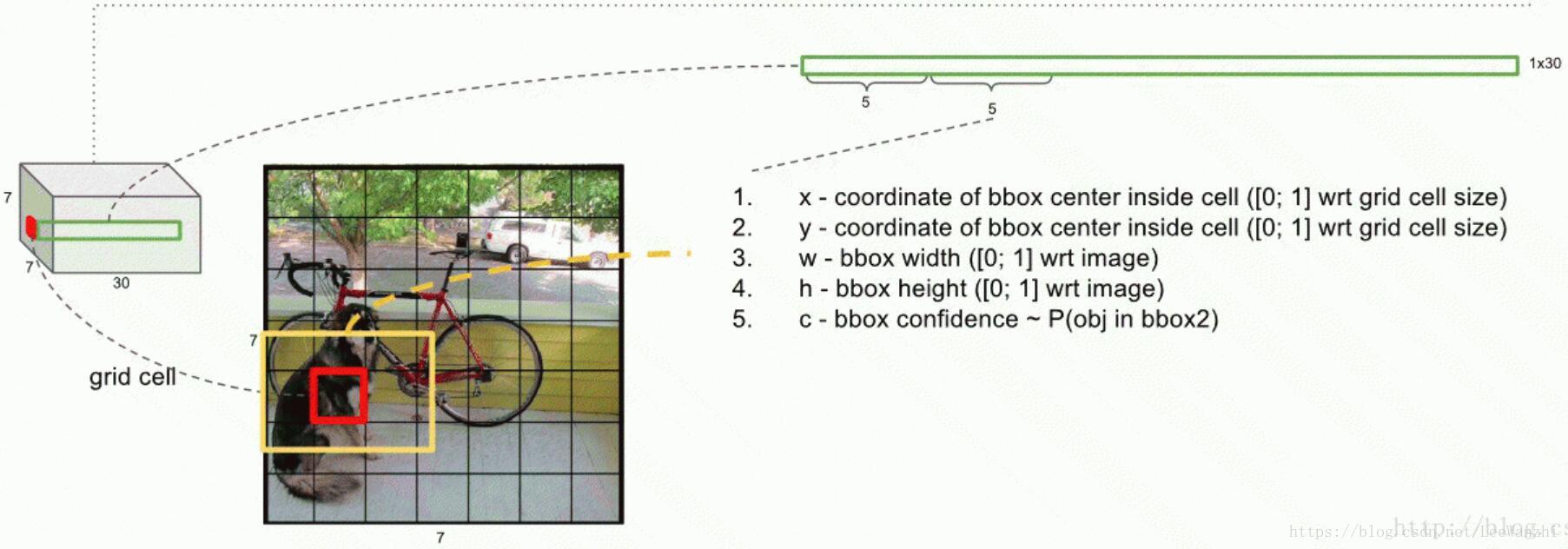
这幅图对YOLO的检测模式有一个比较形象的表示。YOLO的输出为一个7x7x30的张量。其中输出值中,每个格网1x30,表示image上对应格网的bbox值。
前5个值,表示第一个bbox的变量:
(1) x,y:表示bbox的中心在当前格网的位置相对于格网尺寸的比例
(2) w,h: 表示bbox的宽和高相对整幅图像的比例
(3) confidence: 置信度,反映bbox是否包含object,以及bbox位置预测有多准。其实也就是IoU,反映的是位置预测的准不准。
后5个值,表示第二个bbox的变量。

confidence的计算公式:Pr表示包含object的概率,包含则为1,不包含则为0. IoU表示如果包含object,则bbox与GT的IoU。
最后20个值,表示 VOC数据集中20个类每类的score。即每个格网只给出一组打分值,尽管有2个bbox。
score = Pr(class|object),因为有20类,所以有20个值。
测试阶段,将这些评价值相乘,进行综合评价,主要体现在位置预测的准不准和类别分的准不准。

YOLO模型框架
根据GoogleNet修改,24个卷积层,2个FC层。

至于训练以及损失函数,就不细说了。
3.评价
YOLO它的思想主要是利用输出的7 x 7的张量来表示image上7 x 7的格网的检测情况。每个格网都有两个anchor可以预测+1组分类。
这样的弊端就是:召回率太低,容易找不全。因为如果两个物体落入一个image格网,YOLO只会给出一个预测(格网中的2个anchor只预测一类)。对小物体的检测自然而然就比较渣了。
另外定位误差大(只有2个anchor,很难将object的位置准确确定)。这样它的平均精度也会比较低。
优点就是:没有了region proposal,比较快。(ssd也是把RPN给砍掉了,所以快)。同时一幅图只有98个anchor,也是提高了速度。(但这是牺牲了召回率为代价的)