学习论文:YOLO: Unified, Real-Time Object Detection
核心思想
YOLO 的核心思想就是把目标检测转变成一个回归问题,利用整张图作为网络的输入,仅仅经过一个神经网络,得到bounding box(边界框) 的位置及其所属的类别。
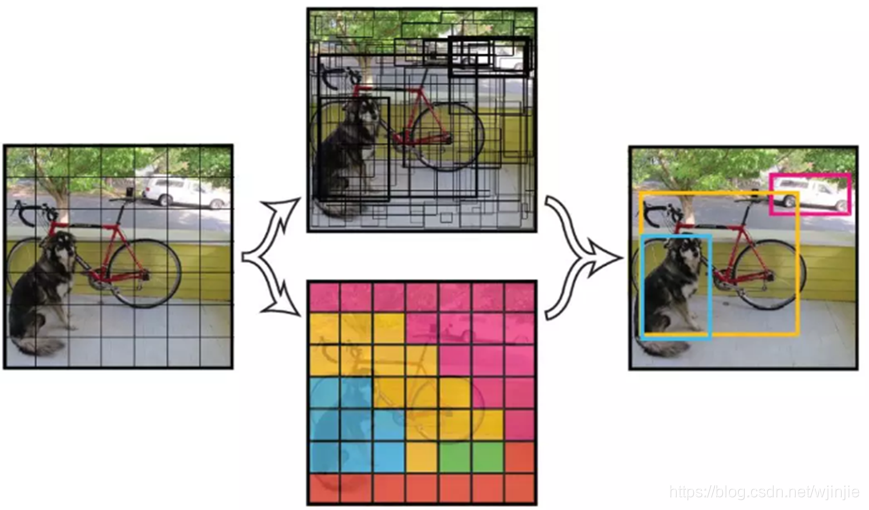
实现过程
- 将一幅图像分成 S*S个网格(grid cell),如果某个 object 的中心落在这个网格中,则这个网格就负责预测这个object。
- 每个网格要预测 B 个bounding box,每个 bounding box 要预测 (x, y, w, h) 和 confidence 共5个值。
- 每个网格还要预测一个类别信息,记为 C 个类。
- 总的来说,SS 个网格,每个网格要预测 B个bounding box ,还要预测 C 个 类。输出就是 S * S * (5B+C) 的一个 tensor。
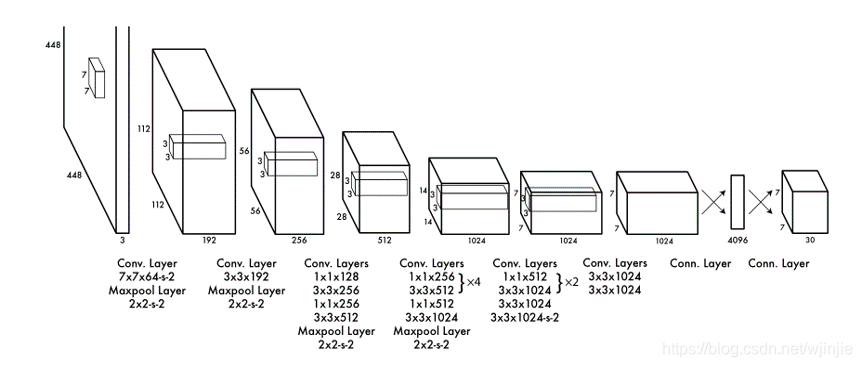
YOLO网络结构
- 采用了24层卷积层,2层全连接层。
- 借鉴了GoogLeNet分类网络结构,但不完全相同。(比如层数不同)
- 卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。
目标损失函数
先给出论文中的损失函数原型:
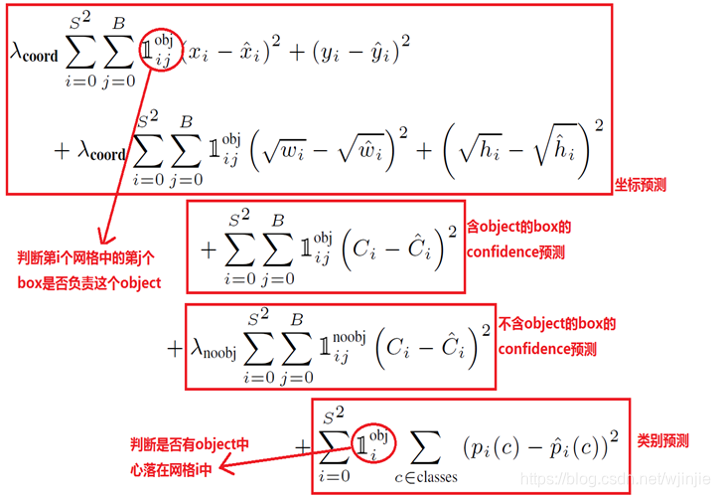
由目标损失函数可以看出: - 由三部分组成,分别是:坐标预测、置信度预测和类别预测。
- 使用的是平方和误差,因为它容易优化,但是它并不完全符合我们最大化平均精度的目标。如果它的定位误差与分类误差相等,可能不是理想的。为了增加对定位误差的判罚,使第二项系数为5。
- 在每个图像中,许多网格单元不包含任何对象。这就把这些细胞的“置信度”分数推到零,往往超过了包含对象的细胞的梯度。这可能导致模型不稳定,导致训练早期发散。为了减小对不包含对象的框的置信度的判罚,使之第三项系数为0.5。
- 这里要注意,w和h在进行误差计算的时候取的是它们的平方根,原因是对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏一点更不能忍受。而sum-square error loss中对同样的偏移loss是一样。 为了缓和这个问题,作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width。
性能分析
优点:
- YOLO 检测系统非常的快。对于实时检测,标准版本的 YOLO 系统可以每秒处理 45 张图像;YOLO 的极速版本可以处理 150 帧图像。这就意味着 YOLO 可以以小于 25 毫秒延迟,实时地处理视频。对于欠实时系统,在准确率保证的情况下,YOLO速度快于其他方法。
- YOLO 实时检测的mean Average Precision是其他实时监测系统的两倍。
- 迁移能力强,能运用到其他的新的领域(比如艺术品目标检测)。
局限: - YOLO对相互靠近的物体,以及很小的群体检测效果不好,这是一个网格只预测了2个框,并且都只属于同一类。
- YOLO是从数据中学习预测bounding boxes,因此,对不常见的角度的目标泛化性能偏弱。
- 由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。(因为对于小的bounding boxes,small error影响更大)
结论
YOLO作为一种基于单独神经网络模型的目标检测方法,具有可以高准确率、快速检测的特点,同时具有一定的鲁棒性,可以适用于实时目标检测。
