前几天YOLOv3问世了,朋友圈也是很多同学转发,很兴奋,当然我也是。所以,先是直接上手体验了一下darknet53,今天把paper看了,做个总结。
1. BBox Prediction
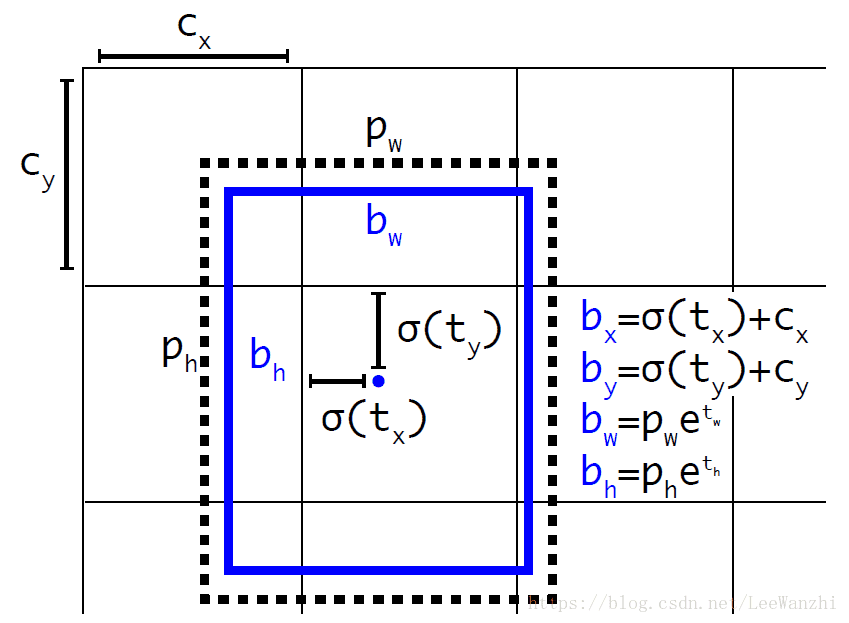
与YOLOv2一样,YOLOv3也是在feature map上对每个位置进行bbox预测。图中,t为预测值,但是,注意这些值都是相对当前grid的相对值,分别是(tx,ty,tw,th)。最终的预测bbox为:bx,by,bw,bh,这是在image的bbox。
其实,上面的都是和YOLOv2一样啦(除了YOLOv2输出的t是5个),下面才是new version的亮点。
3个尺度的feature map
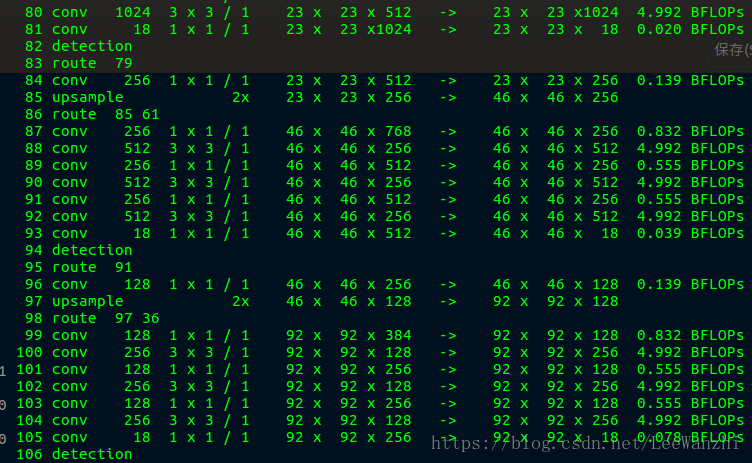
如图,在每个detection前,尺度都不同(23x23,46x46,92x92)。这里用到了上采样。(可以提供更多的语义信息和细粒度特征)。
这里的操作类似于FPN(feature pyramid network)。
在YOLOv3中,我们的anchor由5个变为9个,当然,也是由K均值产生的。每个尺度分配3个anchor。其中每个尺度下每个位置预测3个bbox(4个位置输出+1个objectness+C个类别的分数)。所以每个位置输出(1+4+C)*3个值,这也就是训练时yolov3.cfg里的filter的数量。这也就是每个尺度张量的深度。
2. 网络结构
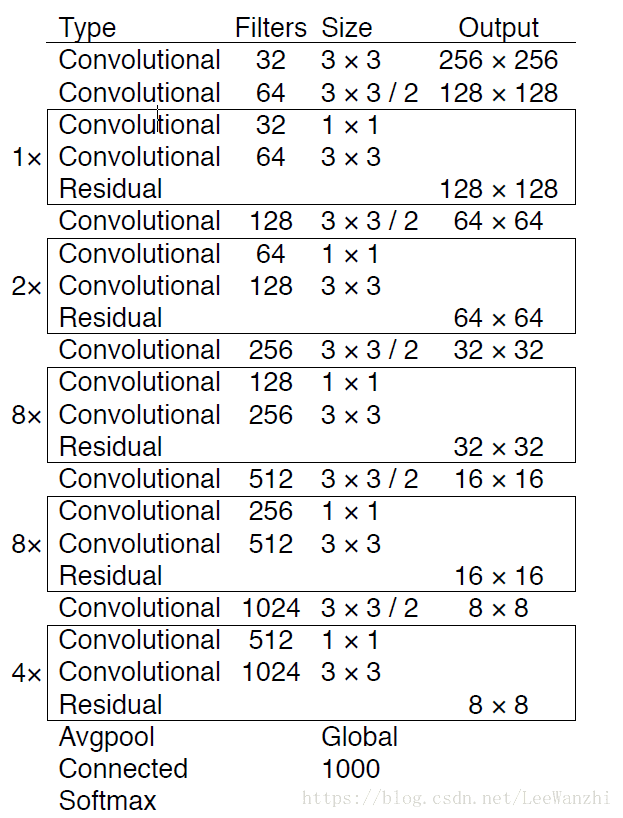
53个卷积层,称为darknet53,类似于ResNET,但速度完爆ResNET。
3. 一点问题
论文中提到YOLOv3在AP50和小目标上表现都不错,但AP75表现就比较乏力。说明随着IoU的升高,YOLOv3预测的bbox不能很好的与GT相重叠。