这篇博文比较推荐的yolo v3代码是qwe的keras版本,复现比较容易,代码相对来说比较容易理解。同学们可以结合代码和博文共同理解v3的精髓。
github地址:https://github.com/qqwweee/keras-yolo3
基于tensorflow的实现代码可以参考:
https://github.com/wizyoung/YOLOv3_TensorFlow
yolo_v3是我最近一段时间主攻的算法,写下博客,以作分享交流。
看过yolov3论文的应该都知道,这篇论文写得很随意,很多亮点都被作者都是草草描述。很多骚年入手yolo算法都是从v3才开始,这是不可能掌握yolo精髓的,因为v3很多东西是保留v2甚至v1的东西,而且v3的论文写得很随心。想深入了解yolo_v3算法,是有必要先了解v1和v2的。以下是我关于v1和v2算法解析所写的文章:
v1算法解析:《yolo系列之yolo v1》
v2算法解析:《yolo系列之yolo v2》
yolo_v3作为yolo系列目前最新的算法,对之前的算法既有保留又有改进。先分析一下yolo_v3上保留的东西:
- “分而治之”,从yolo_v1开始,yolo算法就是通过划分单元格来做检测,只是划分的数量不一样。
- 采用"leaky ReLU"作为激活函数。
- 端到端进行训练。一个loss function搞定训练,只需关注输入端和输出端。
- 从yolo_v2开始,yolo就用batch normalization作为正则化、加速收敛和避免过拟合的方法,把BN层和leaky relu层接到每一层卷积层之后。
- 多尺度训练。在速度和准确率之间tradeoff。想速度快点,可以牺牲准确率;想准确率高点儿,可以牺牲一点速度。
yolo每一代的提升很大一部分决定于backbone网络的提升,从v2的darknet-19到v3的darknet-53。yolo_v3还提供替换backbone——tiny darknet。要想性能牛叉,backbone可以用Darknet-53,要想轻量高速,可以用tiny-darknet。总之,yolo就是天生“灵活”,所以特别适合作为工程算法。
当然,yolo_v3在之前的算法上保留的点不可能只有上述几点。由于本文章主要针对yolo_v3进行剖析,不便跑题,下面切入正题。
YOLO v3
网上关于yolo v3算法分析的文章一大堆,但大部分看着都不爽,为什么呢?因为他们没有这个玩意儿:
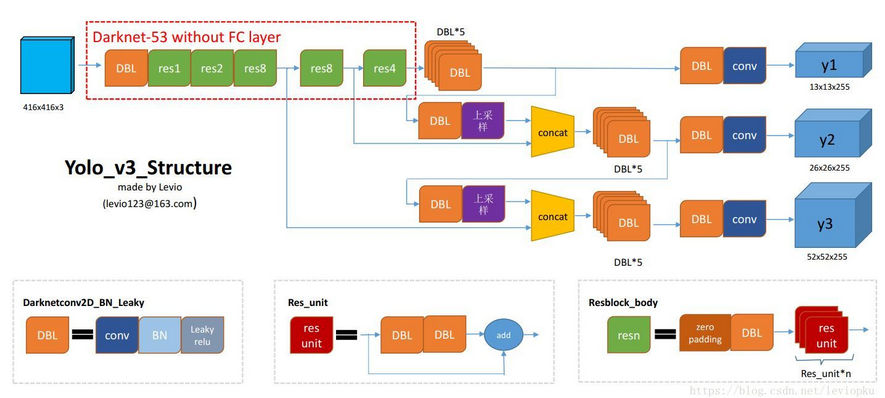
yolo系列里面,作者只在v1的论文里给出了结构图,而v2和v3的论文里都没有结构图,这使得读者对后两代yolo结构的理解变得比较难。but,对于yolo学习者来说,脑子里没有一个清晰的结构图,就别说自己懂yolo了。上图是我根据官方代码和官方论文以及模型结构可视化工具等经过好几个小时画出来的,修订过几个版本。所以,上图的准确性是可以保证的。