1.DeepPose(谷歌大佬首次提出人体关键点解决方案)
2.Joint-cnn-mrf(在cnn框架下利用条件随机场对位置进行建模,提出了heatmap)
3.SpatialDropout (LeCun团队首次将多尺度应用于人体关键点检测)
4.Optical Flowing(首次将光流特征应用于2D关键点检测)
5.CPM(空间特征学习机器,去掉了对马尔科夫模型建模空间联系的依赖)
6.IEF (错误迭代反馈机制,去掉了对马尔科夫模型建模空间联系的依赖)
7.Deepcut & Deepercut(伪多人关键点检测方案)
8.Hourglass(首个以模块形式堆叠形成的人体姿态估计网络)
9.Pose Attention(以Hourglass为基石,引入attention机制,引入CRF取代softmax)
10.PyraNet(以Hourglass为基石,特征金字塔)
11.MSSA(以Hourglass为基石,多尺度特征,掩码训练)
12.G-RMI(单人关键点检测基石,有许多基础思路)
13.Global and Local Normalization(肢体归一化)
14.Adversarial PoseNet(使用生成对抗策略解决关键点遮挡问题)
15.Self Adversarial pose(利用对抗的方式使得热度图更精准)
16.alphapsoe1 & alphapsoe2(解决人体框不准和拥挤场景姿态估计)
17.Recurrent Human Pose Estimation(递归训练实现人体关键点预测)
18.CPN(级联金字塔网络,2017coco关键点冠军)
19.GNet-pose(利用外部构建图特征的方式进行引导学习)
20.PIL(利用外部身体部位信息的方式进行引导学习)
21.simple baseline(简单高效的单人姿态估计网络)
22.DLCM(首次用显式的方式将关键点和连接进行分层学习)
23.Hrnet(coco2019关键点检测冠军)
24.MSPN(基于Hourglass,优化其存在的缺点)
25.FastPose(将知识蒸馏应用于人体关键点检测)
26.Darkpose(首次对关键点的编解码过程进行研究)
27.SSN(轻量级人体姿态估计网络)
28 .LSTM_POSE_Machine(利用LSTM进行对视频进行人体姿态估计)
29.UniPose_LSTM(最新视频姿态估计SOTA)
30.High Performance(优于Hrnet)
·
1.DeepPose(谷歌大佬首次提出人体关键点解决方案)
CVPR2014 Google | DeepPose: Human Pose Estimation via Deep Neural Networks
3rdParty Code:pytorch
3rdParty Code:chainer
3rdParty Code:tensorflow
3rdParty Code:caffe
Google大佬首次提出,如何使用CNN来进行姿态估计的公式,并且提出了一种使用级联的方式来进行更准确的姿态估计器。作者使用CNN并不是用的分类损失,而是使用线性回归损失,预测的关键点和ground-true 的 L2-loss。为了得到更好的精确率,作者训练一个级联的姿态回归器。在第一个阶段,先粗略的估计出部分的姿态轮廓,然后在下个阶段,将通过已知关键点位置不断的优化其他关键点的位置。每个stage都使用已经预测的关键点来切出基于这个关键点的邻域,这个子图像将被用于接下来的网络输入,而接下来的网络就会看到更高分辨率的图像,最终达到更好的精确率。
2.Joint-cnn-mrf(在cnn框架下利用条件随机场对位置进行建模,提出了heatmap)
NIPS 2014 纽约大学 Yann LeCun | Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation
Official Code:tensorflow
本文提出了一种新的混合体系结构,该体系结构由CNN和马尔可夫随机场组成。作者展示了此架构如何成功应用于2D人体姿势估计。该体系结构可以利用结构域约束,例如人体关节位置之间的几何关系。 算法表明,这两种模型范例的联合训练可提高性能,并使我们大大优于现有的最新技术。这是早期的deep learning应用到姿态估计的文章,所以有比较大篇幅网络模型设计,作者通过理论结合实际提出网络结构设计思想(当然现如今NSA已经势不可挡)。下图还展示了本文的核心思想就是不同类间的关键点存在位置上的结构性联系。
1、利用CNN做姿态估计,采用heatmap的方式来回归出关键点
2、利用人体关键点之间的结构关系,结合马尔科夫随机场的思想来优化预测结果,主要针对于网络预测的false postive。
3.SpatialDropout (LeCun团队首次将多尺度应用于人体关键点检测)
2014 纽约大学 Yann LeCun | Efficient Object Localization Using Convolutional Networks
深度卷积网络(CNN)已实现了最新的人体姿势估计性能。 传统的CNN体系结构包括池化和子采样层,可减少计算需求,引入不变性并防止过度训练。 当然这些好处是以降低定位精度为代价的。 本文提出了一种新颖的体系结构,其中包括有效的“位置细化”模型,该模型经过训练可以估计图像小区域内的关节偏移位置。 该精化模型与最新的CNN模型一起级联训练(形成一种新颖的级联架构,该架构结合了精细和粗尺度卷积网络),以提高人体关节位置估计的准确性。文章的主要贡献有:
1、pooling层能为网络增强一些“局部不变性”、“旋转不变性”之类的能力,也能降低参数等种种优点的同时对于回归heatmap的任务却会带来location的精度损失。因此提出了一种新的结构,用于弥补pooling的负效应,“position refinement”。
2、文章提出了全新的“SpatialDropout”策略。
3、多分辨率输入,在更高的分辨率上微调关键点位置。
4. Optical Flowing(首次将光流特征应用于2D关键点检测)
ICCV 2015 | Flowing ConvNets for Human Pose Estimation in Videos
Official Code:caffe
这项工作的目的是对视频中的人体进行姿势估计。本文提出了一种CNN结构,该结构可以通过使用光流将多个帧中的信息组合在一起而从时间上下文中受益。该网络架构:(i)比以前研究回归热图的网络更深; (ii)学习隐式空间模型的空间融合层; (iii)光流用于对齐来自相邻帧的热图预测; (iv)最终的参数化合并层,该层学习将相邻帧热图合并为整体置信度图。
5.CPM(空间特征学习机器,去掉了对马尔科夫模型建模空间联系的依赖)
CVPR 2016 卡内基梅隆大学 | Convolutional Pose Machines
Official Code: caffe
3rdParty Code: Tensorflow v1
3rdParty Code: Tensorflow v2
3rdParty Code: Tensorflow v3
CPM为学习丰富的隐式空间模型提供了一个时序预测框架。在这项工作中,作者展示了一个系统的设计,如何将卷积网络纳入CPM框架中学习图像特征,以及如何将依赖于图像的空间模型用于姿态估计的任务。CPM同时用卷积图层表达纹理信息和空间信息。主要网络结构分为多个stage,其中第一个stage会产生初步的关键点的检测效果,接下来的几个stage均以前一个stage的预测输出和从原图提取的特征作为输入,进一步提高关键点的检测效果。论文还通过提供一个自然的学习目标函数来加强中间监督来解决训练中梯度消失的问题,从而补充反向传播的梯度并调节学习过程。
本文的主要贡献有:
1.提出了一种特殊的卷积网络架构用以学习隐式空间模型。
2.给予上述空间模型设计系统的训练方法,是的模型能够学习图像特征和空间结构特征, 且不需要引入类似第二篇文章Joint-cnn-mrf中的马尔科夫模型对空间联系进行建模。
6.IEF (错误迭代反馈机制,去掉了对马尔科夫模型建模空间联系的依赖)
CVPR 2016 | Human Pose Estimation with Iterative Error Feedback
Official Code: caffe
本文主要内容是提出了一个通用的框架,该框架通过从输入和输出的联合空间学习特征提取器,对输入和输出空间中丰富的结构化信息进行建模。文章引入了自顶向下的反馈机制,不直接预测目标输出,而是在前馈过程中,预测当前估计的偏差并反馈迭代修正预测值,文中称之为IEF(Iterative Error Feedback)。通过上述架构,算法能够提取人体姿态估计和物体分割任务中的结构化关系。与第五篇文章类似,该思想从网络训练和架构设计的角度学习网络的结构化特征,而不需要引入类似与马尔科夫模型来建立图模型。虽然标准的CNN提供了能够在多个抽象级别捕获图像的层次表示,但输出通常被建模为平面图像或像素级别的1-of-K标签,或稍微复杂一些的手工设计表示。我们在本文的目的是通过引入迭代误差反馈(IEF)来减轻这种不对称性,迭代误差反馈将层次表示学习扩展到输出空间,同时在本质上利用相同的机制。广义而言,IEF的工作方式是将重点从预测外部世界的状态转移到纠正对外部世界的期望,这是通过在标准模型中引入一个简单的反馈连接来实现的。
7.Deepcut & Deepercut(伪多人关键点检测方案)
CVPR 2016 | DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation
ECCV 2016 | DeeperCut: A Deeper, Stronger, and Faster Multi-Person Pose Estimation Model
Official Code: caffe
Deepcut:
该算法提出了一种联合解决检测和姿态估计的方法,首先利用CNN的方法提取图像中的所有关键点,所有的关键点作为节点组成一个dense graph(密度图)。其次利用Fasterrcnn获取人体位置,并联合密度图。最终将属于同一个人的关键点(节点)归为一类,每个人作为一个单独类。
本文的思路具有以下几个优势:
1)可以解决未知个数人的图像,通过归类得到有多少个人
2)通过图论节点的聚类,有效的进行了非极大值抑制
3)优化问题表示为 Integer Linear Program (ILP),可以有效求解
Deepercut:
本算法是在Deepcut的基础上,对其进行改进,改进的方式基于以下两个方面:
(1)使用最新提出的residual net进行关键点的提取,效果更加准确,精度更高。
(2)使用Image-Conditioned Pairwise Terms的方法,能够将众多候选区域的节点压缩到更少数量的节点,这也是本文为什么stronger和faster的原因所在。该方法的原理是通过候选节点之间的距离来判断其是否为同一个重要节点。
8.Hourglass(首个以模块形式堆叠形成的人体姿态估计网络)
ECCV 2016 | Stacked Hourglass Networks for Human Pose Estimation
3rdParty Code: Tensorflow
3rdParty Code: torch
3rdParty Code: pytorch
本文提出了一种用于人体姿态估计的新型卷积网络结构。特征跨所有尺度进行处理并整合,用以捕获与身体相关的各种空间关系。文章展示了如何将重复的自底向上、自顶向下的处理与中间监督相结合使用,以提高网络的性能。作者将该架构称为一个堆叠的沙漏网络,它基于池化和上采样的连续步骤,这些步骤将生成最终的预测集。在FLIC和MPII基准上获得的最新结果超过了所有最近的方法。本论文中值得学习的思想如下: 1.使用模块进行网络设计 2.先降采样,再升采样的全卷积结构 3.跳级结构辅助升采样 4.中继监督训练。
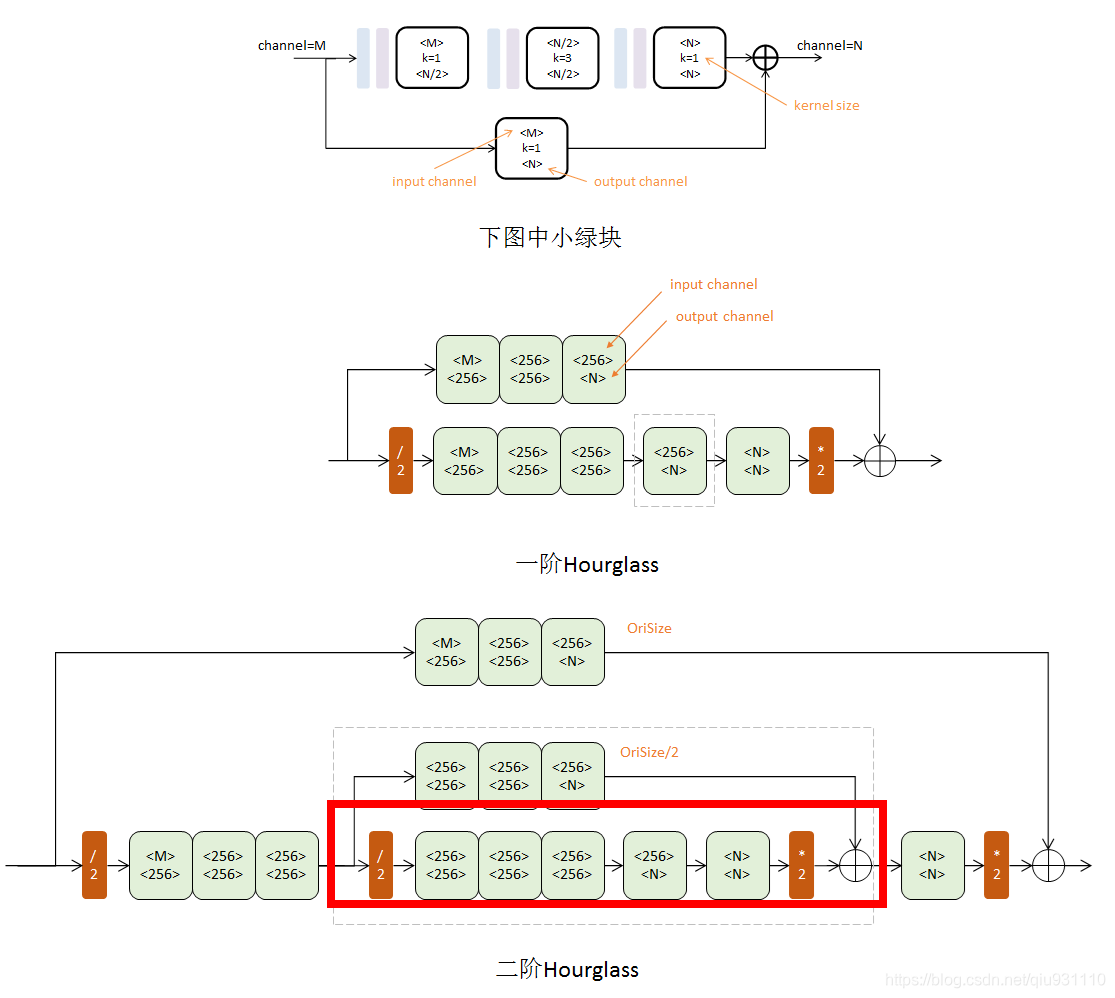
9.Pose Attention(以Hourglass为基石,引入attention机制,引入CRF取代softmax)
CVPR 2017 港中文 | Multi-Context Attention for Human Pose Estimation
3rdParty Code: torch
3rdParty Code: pytorch
本文提出了将多上下文关注和对流引入到端到端的框架中,进行人体姿态估计。作者使用视觉注意力来指导上下文建模。同时作者引入条件随机场(CRF)来进行空间相关建模,而不是使用全局Softmax。文章建立了多情境注意力模型。多分辨率、多语义、分层的整体部分注意方案。此外,为了丰富传统剩余单元的表达能力,提出了一种沙漏剩余单元(HRUs)来增加网络的接受域。
10.PyraNet(以Hourglass为基石,特征金字塔)
ICCV 2017 | Learning Feature Pyramids for Human Pose Estimation
3rdParty Code: pytorch
Official Code
本文提出了两种通用的方案包括:金字塔剩余模块(PRMs),多分支网络初始化方案。PRMs用于增强离散神经网络的尺度不变性。并证明了多分支网络初始化方案的理论正确性和有效性。此外,还提出了一种简单而有效的方法来防止在添加多个映射输出时响应的方差爆炸。
11. MSSA(以Hourglass为基石,多尺度特征,掩码训练)
ECCV 2018 | Multi-Scale Structure-Aware Network for Human Pose Estimation
本文提出的方法是对hourglass沙漏模型的改进:第一:引入多尺度监控网络(MSS-net)和多尺度回归网络(MSR-net),结合丰富的多尺度特征,通过跨尺度特征匹配提高关键点定位的鲁棒性。第二:MSS-net和MSR-net都是利用结构感知损失来明确地从多尺度特征中学习人体骨骼结构,这些特征在复杂场景中恢复遮挡时具有很强的先验性。第三:提出了一个关键点掩码训练方案,该方案可以有效地对网络进行微调,通过相邻匹配对被遮挡的关键点进行鲁棒定位。这些改进可以改善复杂活动、重遮挡、多对象和背景混乱等复杂情况下的姿态估计。
12.G-RMI(单人关键点检测基石,有许多基础思路)
CVPR2017 Google | Towards accurate multi-person pose estimation in the wild
Official Code: pytorch
本文提出了一种2D人体关键点检测的方法,该方法是一种简单而强大的自上而下的方法,包括两个阶段。在第一阶段,算法预测图片中人体的位置和大小;为此,算法使用Faster RCNN检测器。在第二阶段,算法估计每个人体框框中可能包含的关键点。对于每种关键点类型,算法使用全卷积的ResNet预测对应的热图和偏移量。为了结合这些输出,算法引入了一种新颖的聚类来获得高度本地化的关键点预测。文章还使用了一种全新的基于关键点的非极大值抑制(NMS),而不是较粗糙的基于人体的NMS,以及一种新颖的基于关键点的置信度估计的形式,而不是基于目标框评分。本文提出的基于关键点的NMS在后面的自上而下的文章中被普遍应用。
13. Global and Local Normalization(肢体归一化)
ICCV 2017 | Human Pose Estimation using Global and Local Normalization
考虑到关节点相对位置分布的多样性,作者提出了两阶段的归一化方案:人体归一化和肢体归一化,使分布更加紧凑,有利于空间细化模型的学习。归一化的核心是将特征图的指向垂直向下。
14.Adversarial PoseNet(使用生成对抗策略解决关键点遮挡问题)
ICCV 2017 | Adversarial PoseNet: A Structure-aware Convolutional Network for Human
Pose Estimation
Official Code: pytorch
对于单目图像中的人体姿态估计,关节遮挡和人体重叠往往导致姿态预测的偏差。在这种情况下,可能会产生生物学上不可信的姿势预测。相比之下,人类视觉可以通过利用关节间连接的几何约束来预测姿态。为了通过融合人体结构的先验知识来解决这一问题,作者提出了一种新的基于结构感知的卷积网络来隐式地在深度网络训练中考虑这些先验知识。该隐式结构是一种新的姿态估计条件对抗网络,它利用两个鉴别器网络训练一个多任务的姿态发生器。这两个鉴别器的作用就像一个专家,能把合理的姿势和不合理的姿势区分开来。通过训练多任务位姿发生器来欺骗专家,使其相信生成的位姿是真实的,从而使训练得到的网络对人体的遮挡、重叠和扭曲具有更强的鲁棒性。
15.Self Adversarial pose(利用对抗的方式使得热度图更精准)
ArXiv 2017 | Self Adversarial Training for Human Pose Estimation
Official Code: pytorch
Official Code: torch
作者使用生成式对抗网络作为整体学习方式,建立了两个具有相同架构的堆叠沙漏网络,一个作为生成器,另一个作为鉴别器。在训练完成后,利用该生成器作为人体姿态估计器。该算法利用图像特征来预测人体关键部位的热度图,并利用鉴别器来判断人体关键部位的热度图。作者在三个标准基准数据集上对该方法进行了评估,结果表明该方法对于提高预测精度是有用的。
16.alphapsoe1 & alphapsoe2(解决人体框不准和拥挤场景姿态估计)
ICCV 2017 | RMPE: Regional Multi-person Pose Estimation
ArXiv 2018 | CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark
Official Code: caffe
Official Code: pytorch
RMRE(该方法能够处理不准确的bounding box(边界框)和冗余检测。):论文中值得学习的思想有三点: 第一:Symmetric Spatial Transformer Network – SSTN 对称空间变换网络:在不准确的bounding box中提取单人区域。第二:Parametric Pose Non-Maximum-Suppression – NMS 参数化姿态非最大抑制:解决冗余。第三:Pose-Guided Proposals Generator – PGPG 姿态引导区域框生成器:增强训练数据。

CrowdPose:论文中值得学习的思想有两点: 第一: joint-candidate single person pose estimation (SPPE):通过候选点的概念,设计了对应的候选loss,从而抑制非当前人体实例的点,实现了对拥挤人体关键点的提取。第二:global maximum joints associatio:基于上述特定的单人姿态估计网络,检测到的关键点数量比实际要多,因此提出以图论的方式,通过一个线性规划求解最优解的方式实现最优图的构建,从而实现最优实例的链接。

17.Recurrent Human Pose Estimation(递归训练实现人体关键点预测)
FG 2017 | Recurrent Human Pose Estimation
Official Code: matlab
本文提出了一种人体姿态估计的递归人体模型,该模型能够迭代地捕获上下文信息,从而提高了定位性能。实验结果显示,回归热图可以用于预测关键点的遮挡。本文采用将前馈模块与递归模块相结合的架构,其中递归模块可以迭代运行以提高性能,且为辅助loss不参与在线推理。
18. CPN(级联金字塔网络,2017coco关键点冠军)
CVPR 2018 Face++旷世科技 | Cascaded Pyramid Network for Multi-Person Pose Estimation
Official Code: tensorflow
3rdParty Code: pytorch
本文提出了一种新颖的网络结构,称为级联金字塔网络(CPN),其目的是缓解一些遮挡等难例关键点检测问题。更具体地说,算法包括两个阶段:GlobalNet和RefineNet。 GlobalNet是一个功能金字塔网络,可以成功地定位“简单”的关键点(如眼睛和手),但可能无法准确识别被遮挡或看不见的关键点。而RefineNet尝试通过整合来自GlobalNet的多个尺度的特征,通过扩大感受野的方式以及在线的关键点难例挖掘损失(OHKM loss)来优化对难例关键点的检测。如下图所示,网络结构分为多个stage,其中第一个stage会产生初步的关键点的检测效果,接下来的几个stage均以前一个stage的预测输出和从原图提取的特征作为输入,进一步提高关键点的检测效果。
19.GNet-pose(利用外部构建图特征的方式进行引导学习)
IEEE Transactions on Multimedia 2018 | Knowledge-Guided Deep Fractal Neural Networks for Human Pose Estimation
Official Code: Caffe
Official Code: matlab
作者以堆叠的沙漏的hourglass为基础设计,并建议使用inception-resnet作为网络的构建块,在没有明确的图形建模的情况下,将人体姿态回归到热图中。Knowledge-guided学习是一个通用的方案,可用于其他深层神经网络训练任务。
20.PIL(利用外部身体部位信息的方式进行引导学习)
CVPR 2018 | Human Pose Estimation with Parsing Induced Learner
Official Code: pytorch
本文中,作者提出了一种新的解析诱导学习器(PIL),通过有效地利用解析信息(身体部位)来辅助人类姿态估计。PIL学习从解析特征中预测特定的位姿模型参数,调整位姿模型,提取互补的有用特征。整个模型是端到端可训练的。此外,通过使用PIL训练的LIP数据集到MPII数据集进行跨数据集的评估,显示PIL具有良好的可转移性。即使应用的数据集不提供任何解析信息,外部预训练的PIL仍然可以帮助模型达到最好的效果。
21.simple baseline(简单高效的单人姿态估计网络)
ECCV 2018 | Simple Baselines for Human Pose Estimation and Tracking
Official Code: pytorch
3rdParty Code: tensorflow
如下图所示,本论文提出了一种极其简单的单人姿态估计网络,因为简单有效,所以作者称之为baseline。alphapose中的CrowdPose就是使用了这种baseline。该baseline表示即使用下图中的c,简单的降采样加升采样就可以实现类似a图中的hourglass,b图中的CPN等网络的性能。 这一结论很值得深思啊。。。
22.DLCM(首次用显式的方式将关键点和连接进行分层学习)
ECCV 2018 | Deeply Learned Compositional Models for Human Pose Estimation
文章提出DLCM模型,该模型能够描述人体各部分之间复杂而现实的组成关系,提出了一种新的零件表示方法。它简洁地编码了每个部分的方向、比例和形状,并避免了它们潜在的大型状态空间。与以往的深度神经网络(如针对HPE设计的CNNs)相比,该模型具有层次结构和跨多个语义层次的自底向上,自顶向下推理阶段。作者在实验中表明,DLCM的组成性质有助于他们解决自底向上的姿态预测中出现的模糊性。
23.Hrnet(coco2019关键点检测冠军)
CVPR 2019 | Deep High-Resolution Representation Learning for Human Pose Estimation
Official Code: pytorch
并行连接高低分辨率子网,而不是像大多数现有解决方案那样串联连接。因此,本文的方法能够保持高分辨率而不是通过从低到高的过程恢复分辨率,因此预测的热图可能在空间上更精确。大多数现有的融合方案汇总了低级别和高级别的表示。相反,本文在相同深度和相似水平的低分辨率表示的帮助下执行重复的多尺度融合以提升高分辨率表示,反之亦然,导致高分辨率表示对于姿势估计也是丰富的。因此,本文预测的热图可能更准确。
24.MSPN(基于Hourglass,优化其存在的缺点)
CVPR 2019 | Rethinking on Multi-Stage Networks for Human Pose Estimation
Official Code: pytorch
基于Hourglass在coco数据集上并不是很优秀的表现,本文重新思考了这种多阶段策略。并得出了如下三个结论:(1)从Hourglass的网络结构示意图中,我们可以发现在每个stage中,特征图先被降采样,然后升采样,从上图红色区域我们可以发现整个过程网络的通道保持了一致,该过程导致每个降采样后特征的损失。因为降采样后特征图变小了,只有将通道数扩大,才能在升采样时把损失补充回来。(2)抛弃hourglass的每个stage的连接方式,而使用U-net这种连接方式. 文章认为这种做法可以有效的传递上一个stage的信息给下一个stage,从而促进下一个stage更好的预测pose,如下图所示.(3)不同的stage对应的label heatmap 高斯核范围大小不同. 下一stage的heatmap label 高斯核要比上一stage的heatmap label 高斯核更小,如图所示:

25.FastPose(将知识蒸馏应用于人体关键点检测)
CVPR 2019 | Fast Human Pose Estimation
Official Code: pytorch
本文主要考虑的是模型部署时的推理成本,本文的方案是首先构建一个轻量级的网络,其次通过快速姿态蒸馏(FPD)模型训练方法,将潜在的知识从一个预先训练好的较大的教师模型转移到构建好的轻量级网络中,实现效率和精度的trade-off。然而现有的知识蒸馏的方法多是基于类别层次的判别,而本文的方法是基于关键点热度图的判别,这种方式使得蒸馏学习的效率更高,因为特征约束将变的更多。网络的整体图如下,正如上所述的步骤为了建立一个高性价比的人体姿态估计模型,我们需要构建一个紧凑的主干,如(a)一个轻量级的沙漏网络。为了更有效地训练小目标网络,在姿态估计中采用了知识蒸馏原理。这需要(b)预先训练一个强大的教师姿势模型,如最先进的沙漏网络或其他现有的选择。在©姿态估计过程中,教师模型通过拟态损失函数提供额外的监督指导。在测试推理时,小目标位姿模型可以实现快速和低成本的部署。最后抛弃了计算量大的教师模型,因为它的区别性知识已经转移到目标模型中,因此可以用于部署(而不是浪费)。
26.Darkpose(首次对关键点的编解码过程进行研究)
CVPR 2019 | Distribution Aware Coordinate Representation for Human Pose Estimation
Official Code: pytorch
现有的网络训练人体关键点时,受限于计算量等问题,会将人体从原始图像抠出来后进行降采样。如上图d所示,网络训练完后,为了将关键点恢复到原始分辨率下,需要对图像作扩大降采样倍率的操作。而正常情况下,我们将最终预测得到的热度图上的最大点坐标作为最终的关键点位置,然而由于降采样的存在,该过程存在量化误差。直白的说:热度图中最大的激活位置不是关键点的精确定位而是粗定位。本文提出的坐标解码充分挖掘了热图的分布统计信息,以更准确地揭示潜在的最大激活。至关重要的是,它是计算友好的,因为它只需要计算一个位置每个热图的一阶导数和二阶导数。因此,现有的人类姿态估计方法可以很容易地受益,没有任何计算成本的障碍。与解码过程中分析的一样,编码过程也存在量化误差。如下图所示,显然,由于量化误差的影响,生成的热图是不准确和有偏的,这可能会引入次优的监督信号,导致模型性能下降,特别是对于本文提出的精确坐标解码的情况。当然作者解决的方式很简单,就是将量化前的u,v值用于生成高斯分布。
27.SSN(轻量级人体姿态估计网络)
arXiv 2019 | Spatial Shortcut Network for Human Pose Estimation
本文的主要贡献有:
1.提出了一种基于特征变换的空间通道快速移动模型(FSM)。通过对其特征映射移位、信道解耦和注意机制的研究,提出了一种窗口优化、高效灵活的卷积层结构。
2.对上述提到 的FSM模块进行了详细的分析。证明了该算法在空间依赖关系建模、关键点检测与偏移量关系建模等方面的能力。
3.结果表明,该模型能够在较小的结构下取得较好的甚至更好的效果。本文还提出了一种具有竞争性能的轻量级网络,允许在资源有限的设备上应用。
28 .LSTM_POSE_Machine(利用LSTM进行对视频进行人体姿态估计)
CVPR 2018 | LSTM Pose Machines
Official Code: caffe
3rdParty Code: tensorflow
3rdParty Code: pytorch
本文中,作者提出了一种新的递归式的LSTM CNN模型用于视频姿态估计。该策略,解决了传统基于CNN的方法在静态图像上的性能很好,而在视频上的应用不仅需要大量的计算,且还会导致性能退化和抖动,这样的次优结果主要是由于无法实现连续的几何一致性,无法处理严重的图像质量退化(如运动模糊和遮挡)以及无法捕获视频帧之间的时间相关性等问题,在准确性和效率方面都取得了很大的进步。当长时间不可见时,作者确实观察到一些错误的预测,但作者仍然发现LSTM模块确实有助于更好地利用时间信息,并在整个视频中做出稳定和准确的预测。最后,作者对LSTM中的记忆单元进行了探索和可视化,并解释了在变化帧的位姿估计中记忆的基本动态。
29.UniPose_LSTM(最新视频姿态估计SOTA)
arxiV 2020 | UniPose: Unified Human Pose Estimation in Single Images and Videos
作者分别提出了用于单图像和视频姿态估计的UniPose和UniPose- lstm体系结构。UniPose方法使用了WASP模块,该模块的特点是瀑布式流,具有层叠的无压卷积和多尺度表示。该结构可以更好地理解框架中的上下文信息,有助于更准确地估计主体的姿态。
30.High Performance(优于Hrnet)
arxiV 2020 | Towards High Performance Human Keypoint Detection
Official Code : pytorch
由于遮挡、模糊、光照和尺度变化等原因,从单个图像中检测人类关键点非常具有挑战性。本文通过设计高效的网络结构(CMM)、提出三种有效的训练策略,从三个方面解决了这一问题。并且开发了四种有用的后处理技术。hard-negative person detection mining strategy:用于迁移训练和测试中分布不匹配问题。joint-training strategy:使用大量未标记样本进行知识蒸馏。joint-training strategy:利用具有异构标签的外部数据。这三种策略的合作使CCM能够从丰富多样的姿势中学习有区别的特征。四个后处理:(1)抛物线近似。(2)Soft-NMS.(3)在输出热度图上进行高斯滤波。(4)热度图翻转。
